






最先进的知识蒸馏算法发现整合多个模型可以生成更准确的训练监督,但需要以额外的模型参数及明显增加的计算成本为代价。为此,我们提出了一种新颖的“烘焙”算法,有效整合同批次内不同样本间的知识以优化软标签,仅需一个网络即可实现知识整合。
“烘焙”在任意网络架构的训练中即插即用,以最少的时间成本实现有效的大幅性能提升,我们在ImageNet及其他多个常见的图像分类基准下进行了算法验证,如,ImageNet上ResNet-50的性能以最小的计算开销显著提升1.2%。
来自:将门创投

论文链接:
https://arxiv.org/abs/2104.13298
代码链接:
https://github.com/yxgeee/BAKE
项目主页:
https://geyixiao.com/projects/bake

一、简介
图像分类是计算机视觉最基本的任务之一,为众多下游视觉任务提供了有效的预训练模型。深度学习时代以来,有大量的算法致力于提升图像分类的性能,尤其是在最流行的ImageNet基准上。近期一些研究指出,不够完善的人为标注成为了阻碍监督训练的分类模型性能进一步提升的关键问题。具体来说,人为标注的单标签(一图一类)无法准确描述图像中的丰富内容。
为此,许多研究者提出利用知识蒸馏 (Knowledge Distillation) 算法可以自动生成“软性”多标签作为有效的训练监督,弥补单标签系统所带来的缺陷。最先进的算法发现,整合多个教师(下图a)或学生模型(下图b)的预测可以生成更鲁棒的训练监督,进一步提升模型的性能,我们将这类算法称之为整合蒸馏 (Ensemble Distillation) 算法 [1,2,3]。虽然这类算法取得了最先进的性能,但他们依赖于额外的网络模型或参数,无疑大大增加了训练时计算和显存的成本。
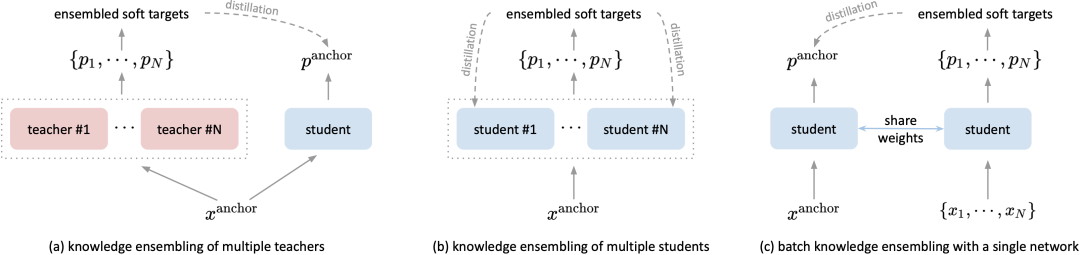
(a) 多教师模型的知识整合;(b) 多学生模型的知识整合;© BAKE: 批次内样本间的知识整合
在该论文中,我们提出了一种新颖的 “烘焙” (BAKE) 训练机制(上图c),整合批次内不同样本间的知识在线优化蒸馏目标,即,将同一批次中样本知识进行加权传播和汇总,而无需多个网络。BAKE首次实现在自蒸馏框架下的知识整合,以最少的训练时间开销和零额外网络参数为代价,持续有效地提高了各种网络架构和数据集的分类性能。例如,使用BAKE训练的ResNet-50在ImageNet上的top-1分类准确率显著提升1.2%,而相比基线模型训练所增加的计算开销仅为3.7%。
除了上述知识蒸馏系列算法之外,还有一类研究被称之标签精炼 (Label Refinery) 算法 [4]。他们往往利用一个预训练标注器为ImageNet进行重新标注,该标注器一般为在更大规模的数据集上训练的较深的网络模型,这不仅需要增加额外的模型,还依赖于额外的超大规模数据集和更多的训练资源,在实际应用中不够灵活。
该文所提出的BAKE算法与已有的自蒸馏、整合蒸馏、标签精炼算法的主要区别见下图:

本文所提出的BAKE算法与已有的自蒸馏、整合蒸馏、标签精炼算法的主要区别
二、方法
传统整合蒸馏算法[1,2,3]往往整合的是多个网络模型对于单个样本的预测,与之不同的是,BAKE整合单网络模型对于批次内多样本的预测。直观地来看,视觉上相似的样本应当具有近似的预测。基于该假设,BAKE依据同批次内其他样本对锚样本的相似度,进行知识的加权传播和汇总,以形成准确的软标签,作为蒸馏训练的监督(见下图)。
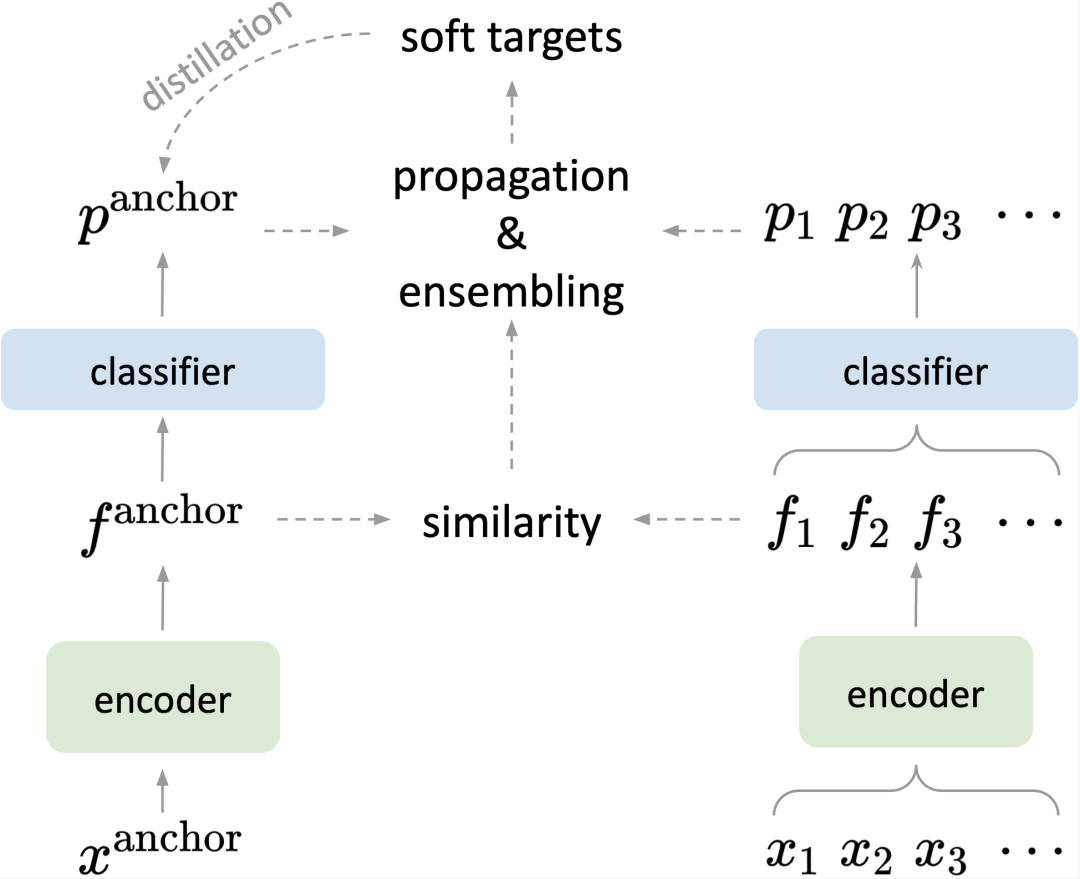 BAKE训练框架
BAKE训练框架
样本间的知识传播基于不同样本与锚样本之间的相似性,所以首先需要计算一个亲和度矩阵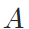 ,也就是计算图像编码器(encoder)输出的特征
,也就是计算图像编码器(encoder)输出的特征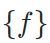 之间的距离。亲和度矩阵需要去除对角线
之间的距离。亲和度矩阵需要去除对角线 ,也就是同一样本的相似度,并在每行进行softmax归一化,使得每一行的和为1,即
,也就是同一样本的相似度,并在每行进行softmax归一化,使得每一行的和为1,即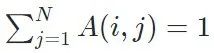 。
。
基于亲和度矩阵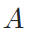 ,可以对除锚样本之外的其他样本的预测进行加权传播,
,可以对除锚样本之外的其他样本的预测进行加权传播, 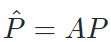 。并与锚样本本身的预测概率进行加权和,从而获得软标签作为蒸馏目标
。并与锚样本本身的预测概率进行加权和,从而获得软标签作为蒸馏目标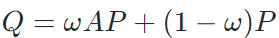 。至此,对批次内样本间知识进行了一次传播,并获得了一次传播后的软标签。
。至此,对批次内样本间知识进行了一次传播,并获得了一次传播后的软标签。
往往基于亲和度矩阵对样本预测做多次传播可以获得更鲁棒准确的软标签,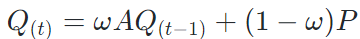 。作者利用近似预测对传播无限次后的软标签进行了估计,
。作者利用近似预测对传播无限次后的软标签进行了估计,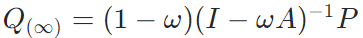 。
。
基于上述知识整合后的软标签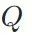 ,可以使用KL散度损失函数进行蒸馏训练。
,可以使用KL散度损失函数进行蒸馏训练。
三、实现
训练的伪代码如下,具体实现请参阅GitHub repo:

四、实验
BAKE以最小的计算开销改进了多种网络架构的训练,并且无需额外的网络辅助。下图汇报了在ImageNet上的top-1分类准确率, “Vanilla”表示使用常规交叉熵损失的基准训练。
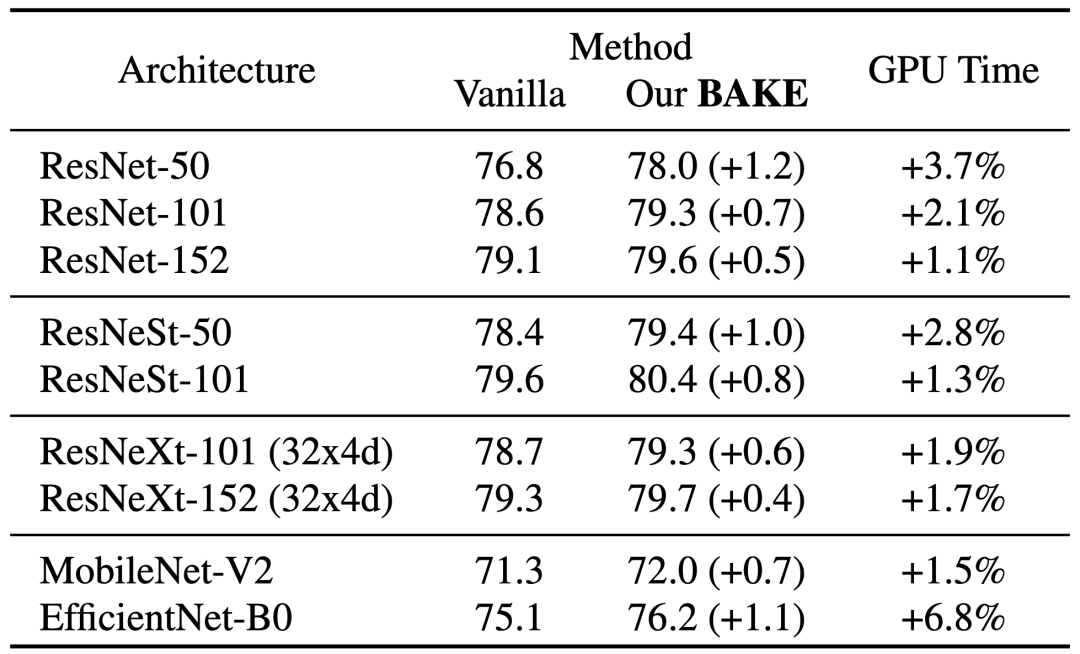 BAKE在ImageNet上的性能, “Vanilla”表示使用常规交叉熵损失的基准训练
BAKE在ImageNet上的性能, “Vanilla”表示使用常规交叉熵损失的基准训练
BAKE不光有效提升了基准模型的训练,也超越了所有单网络下最先进的训练机制,见下图:
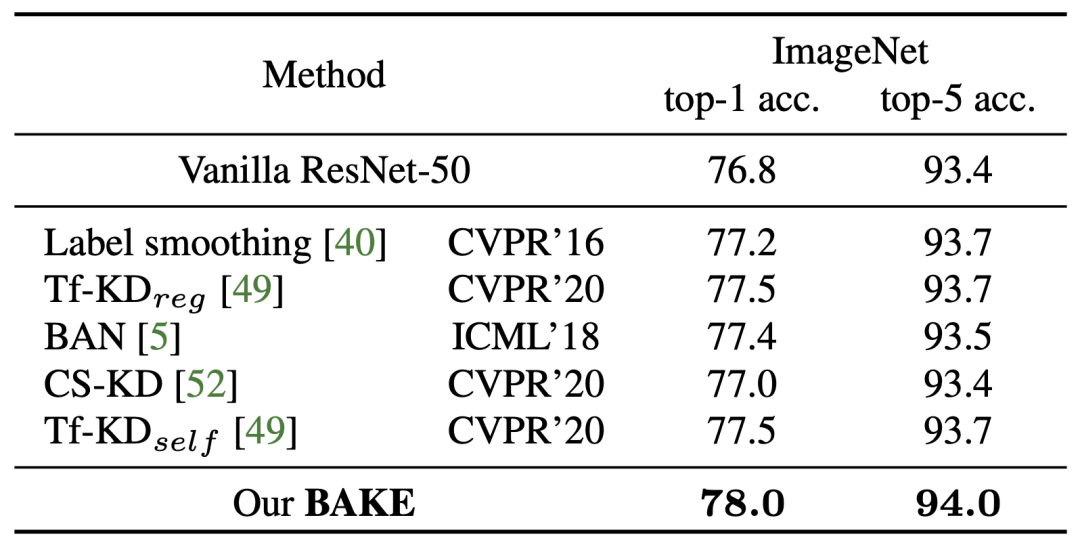
单网络模型训练算法的对比
我们也对BAKE所生成的软标签进行了可视化,如下图,其中每列的四个样本来自于同一批次,请注意,为了简洁,这里只对top-3的类别进行了展示。
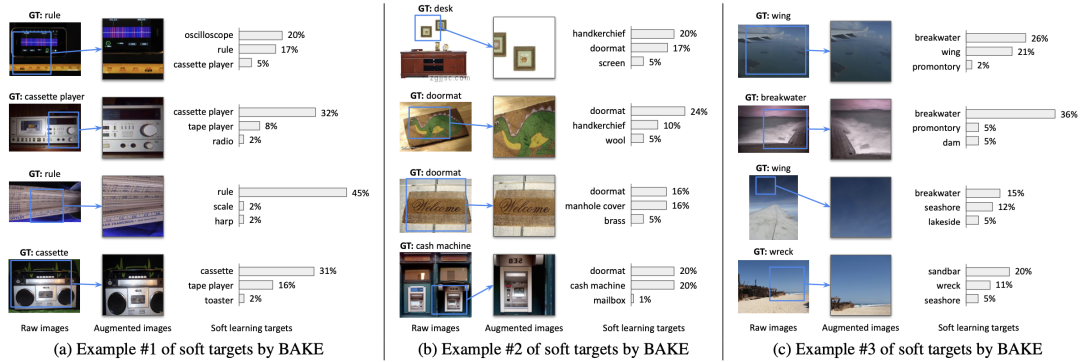
BAKE所生成的软标签示例
我们还检验了利用BAKE训练的分类模型在下游任务中的表现,观察到BAKE所训练的模型在目标检测和实例分割中均可获得稳定的性能提升。

BAKE训练的模型在下游任务中的性能
更多性能分析、鲁棒性测试、消融研究结果请参阅原论文。
五、总结和思考
BAKE是一个非常简洁轻量的算法,无需任何额外的辅助网络就可以生成鲁棒的软标签。BAKE为知识蒸馏中的知识整合提供了一个全新的思路,打破了固有的多模型整合的样式,创新地提出并尝试了样本间的知识整合。目前我们只在最传统的监督分类训练中验证了BAKE,但BAKE的潜力应远不止此,我们后续也会继续在更多的任务中验证BAKE的思想,也欢迎大家在自己的训练任务中尝试加入此类样本间知识整合思想。
参考资料:
[1] Zhiqiang Shen, Zhankui He, and Xiangyang Xue. Meal: Multi-model ensemble via adversarial learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 4886–4893, 2019.
[2] Yonglong Tian, Dilip Krishnan, and Phillip Isola. Contrastive representation distillation. In International Conference on Learning Representations, 2020.
[3] Qiushan Guo, Xinjiang Wang, Yichao Wu, Zhipeng Yu, Ding Liang, Xiaolin Hu, and Ping Luo. Online knowledge distillation via collaborative learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11020–11029, 2020.
[4] Sangdoo Yun, Seong Joon Oh, Byeongho Heo, Dongyoon Han, Junsuk Choe, and Sanghyuk Chun. Re-labeling imagenet: from single to multi-labels, from global to localized labels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021.
//
作者介绍
葛艺潇,香港中文大学多媒体实验室三年级博士生,师从李鸿升教授与王晓刚教授。本科毕业于华中科技大学自动化学院。目前主要研究方向为计算机视觉中的表征学习,包括无监督学习、解耦学习、领域自适应学习等,及其在图像检索、图像生成上的应用。以第一作者身份在NeurIPS、ICLR、CVPR、ECCV等会议中发表多篇论文。
Illustration by Aleksey Chizhikov from Icons8
说个正事哈
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心 。
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
点击上面卡片,关注我呀,每天推送AI技术干货~
整理不易,还望给个在看!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









