






 这篇文章介绍了MacBERT,一种针对中文的预训练语言模型,它通过改进MLM任务和使用N-grammasking与相似词替换策略,显著提升了中文NLP任务的表现。消融实验显示,这些改进对于下游任务效果显著,特别是在机器阅读理解和情感分类方面。MacBERT在CCKS比赛中助力团队取得佳绩,并展示了其在多种技术领域的广泛适用性。
这篇文章介绍了MacBERT,一种针对中文的预训练语言模型,它通过改进MLM任务和使用N-grammasking与相似词替换策略,显著提升了中文NLP任务的表现。消融实验显示,这些改进对于下游任务效果显著,特别是在机器阅读理解和情感分类方面。MacBERT在CCKS比赛中助力团队取得佳绩,并展示了其在多种技术领域的广泛适用性。
每天给你送来NLP技术干货!
来自:NLP情报局
自从Google提出预训练语言模型BERT,关于语言模型的玩法层出不穷。
然而,大部分模型都是在英文场景中提出的,迁移到中文场景效果往往有不同程度的下降。

之前我和朋友参加了CCKS机器阅读理解比赛,查资料时发现哈工大崔一鸣、车万翔、刘挺等人提出了一个针对中文的预训练语言模型 MacBERT,刷新了众多下游任务的 SOTA。
我们在比赛中实测了MacBERT,提分显著,最终在246支参赛队伍中获得了第3。

本文来带你了解这项更强大的中文语言模型 MacBERT。
论文链接
https://arxiv.org/pdf/2004.13922.pdf
开源权重
https://github.com/ymcui/MacBERT
1. MacBERT是什么?
我们先简单回顾一下什么是BERT。
BERT本质上是一个自编码语言模型,为了见多识广,BERT使用3亿多词语训练,采用12层双向Transformer架构。注意,BERT只使用了Transformer的编码器部分,可以理解为BERT旨在学习庞大文本的内部语义信息。
具体训练目标之一,是被称为掩码语言模型的MLM。即输入一句话,给其中15%的字打上“mask”标记,经过Embedding和12层Transformer深度理解,来预测“mask”标记的地方原本是哪个字。
input: 欲把西[mask]比西子,淡[mask]浓抹总相宜
output: 欲把西[湖]比西子,淡[妆]浓抹总相宜例如我们给BERT输入苏东坡的诗“欲把西[mask]比西子,淡[mask]浓抹总相宜”,模型需要根据没有被“mask”的上下文,预测出掩盖的地方是“湖”和“妆”。
相比之下,MacBERT 沿用了 BERT 的整体架构,主要在训练目标上做了改进。
针对 MLM 任务改进
Mac = MLM as correction,即校正的 mask 策略。
原始 BERT 模型的缺点之一是预训练和微调阶段任务不一致,pretrain 有 [mask] 字符,而 finetune 没有。
MacBERT 用目标单词的相似单词,替代被 mask 的字符,减轻了预训练和微调阶段之间的差距。
具体实现分2步:1)我们使用全词mask以及Ngram mask策略来替代随机mask,其中单词级别的1-gram到4-gram的比例为40%,30%,20%,10%。
2)抛弃 [mask] 字符,而是通过word2vec查找被考察单词的语义相似单词进行mask。在极少数情况下,当没有相似的单词时,会降级以使用随机单词替换。
最终,我们对15%的输入单词进行mask,其中80%替换为相似的单词,10%替换为随机单词,其余10%则保留原始单词。
如果感觉有点抽象,看这张图就一目了然。

假设原始中文句子是“使用语言模型来预测下一个词的概率”。BEP切词后,按BERT的随机 masking 策略,可能得到:
1. 使 用 语 言 [M] 型 来 [M] 测 下 一 个 词 的 概 率。
如果加入全词掩码策略,会以实体为单位进行 masking:
2. 使 用 语 言 [M] [M] 来 [M] [M] 下 一 个 词 的 概 率。
继续加入 N-gram 掩码:
3. 使 用 [M] [M] [M] [M] 来 [M] [M] 下 一 个 词 的 概 率。
最后加入 Mac 掩码,用语义相似的词代替 [M]:
4. 使 用 语 法 建 模 来 预 见 下 一 个 词 的 几 率。
以上就是 MacBERT 的核心思想。
针对 NSP 任务改进
原始NSP已被证明贡献不大,MacBERT 引入了 ALBERT 的句子顺序预测(SOP)任务,通过切换两个连续句子的原始顺序来创建负样本。
后续的消融实验证明,SOP 效果好于 NSP。
2. 实验设置与结果
从中文维基百科中,我们获得了大约0.4B的单词。此外,还从收集的扩展数据中获得了 5.4B 个字,包含百科全书,新闻和问答网站,比中文维基百科大十倍。
为了识别中文单词的边界,我们使用LTP进行中文单词分割,词表沿用原始BERT。
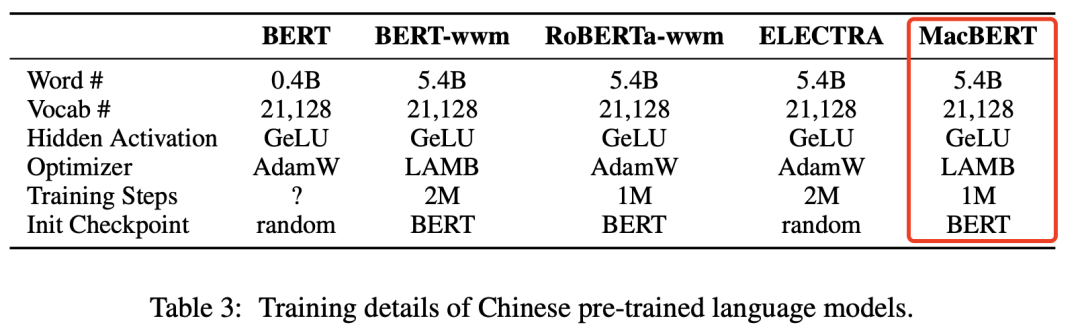
微调实验
最终我们在分类、匹配、阅读理解等众多下游任务上对比了不同预训练模型的效果。
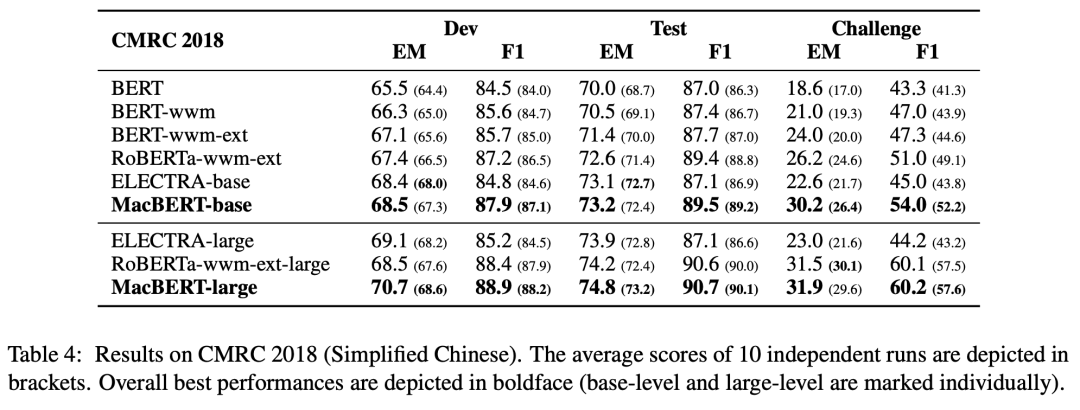
CMRC 2018 机器阅读理解:
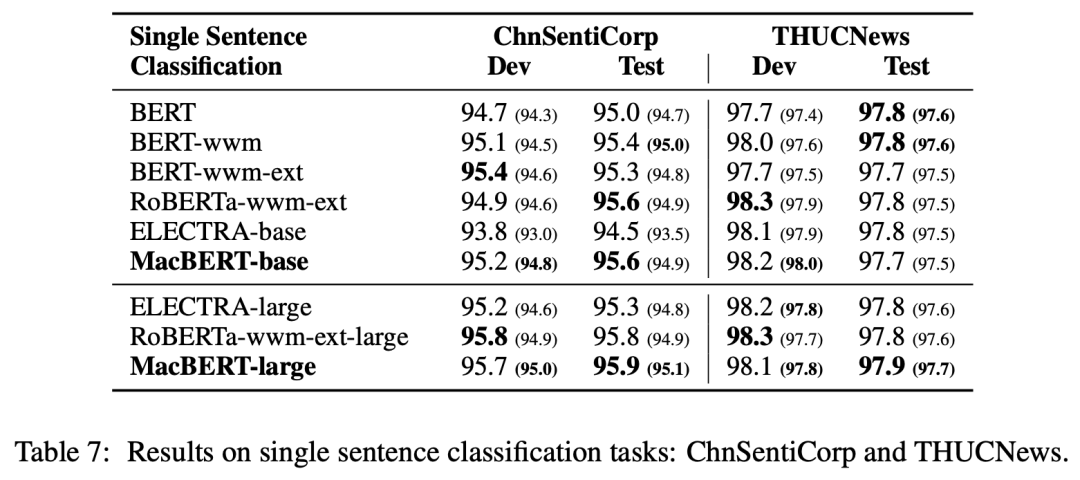
情感分类+长文本分类:
文本相似匹配:
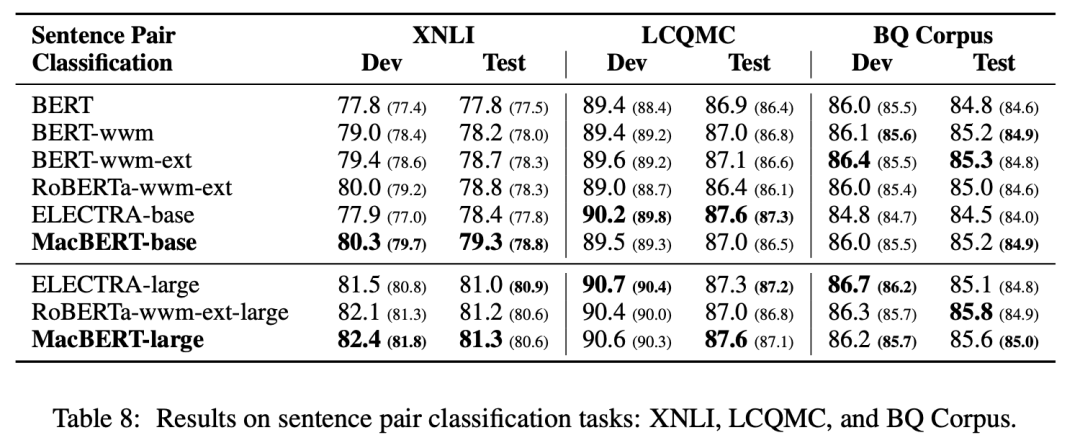
实验证明,MacBERT 在多种中文 NLP 任务上都获得了显著改进。
这些改进的重要部分又来自何处呢?详细的消融实验给出了答案。
消融实验
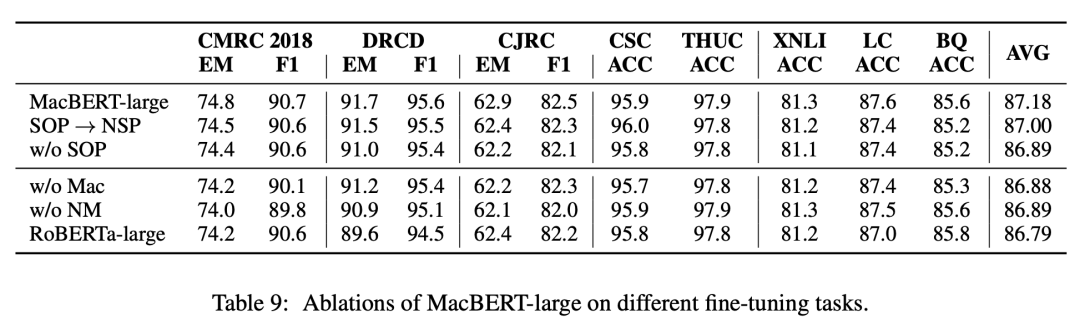
实验结论:
1. 所有提出的改进点,对于总体结果都有帮助。
2.最有效的修改是N-gram masking和相似单词替换。
3.NSP任务的重要性不如MLM,设计更好的MLM任务以充分释放文本建模能力十分重要。
4.SOP任务确实比NSP表现出更好的性能,删除SOP将导致阅读理解任务明显下降。
我们在CCKS比赛中实测了MacBERT,在编码器中将RoBertA替换为MacBERT,验证集 F1 从 0.780 上升到 0.797,获得了将近 2% 的提升。
3. 总结
MacBERT 将 MLM 任务作为一种语言校正方式进行了修改,减轻了预训练和微调阶段的差异。
下游各种中文NLP数据集的微调实验表明,MacBERT 可以在多数任务中获得显著收益。
通过分析消融实验,我们应该更多关注MLM任务,而不是NSP及其变体,因为类似NSP的任务并没有显示出彼此的压倒性优势。
这篇收录于 EMNLP 2020 子刊的论文,是对中文场景预训练语言模型的创新与尝试,由于模型结构并没有改动,可以很好地兼容现有任务(替换 checkpoint 和配置文件即可)。
感兴趣的小伙伴,快来动手试试吧!
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!
















 1007
1007

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









