






每天给你送来NLP技术干货!

来自:复旦DISC
COLING 2022
国际计算语言学大会 (Inteational Conference on Computational Linguistics,COLING),是自然语言处理和计算语言学领域的重要国际学术会议,每两年召开一次,1965年第一届召开以来,COLING已成功地举办了29届。2022年秋季, COLING将以混合形式在韩国庆州举行, 所有参与者都可以在会场现场或虚拟加入。
在COLING 2022中, 复旦大学数据智能与社会计算实验室 (Fudan DISC) 共计 4 篇文章被录用, 其中包括 3 篇长文和 1 篇短文。
1 A Progressive Framework for Role-Aware Rumor Resolution
作者:陈蕾, 李冠颖, 魏忠钰, 杨洋, 周葆华, 张奇, 黄萱菁
类别:Long Paper,Poster
摘要:在这项工作中,我们构造了“引爆点识别”的新任务,以期识别出在对谣言传播具有推动作用或对谣言判别有指示作用的消息。我们对PHEME数据集进行了扩展,对2万余条推特消息进行了标注,数据分析表明信息引爆点在社交网络中更具有泛化属性,尽管信息引爆点在整体消息中占比较低但却对谣言判别具有辅助作用。此外我们还构造了非对称的图循环神经网络对信息传播树进行建模,采用渐进式的框架完成信息引爆点识别以及谣言判别两项任务。实验结果表明,该模型在两项任务上都能取得较好的性能,在跨事件的表示学习中也有性能的提升。

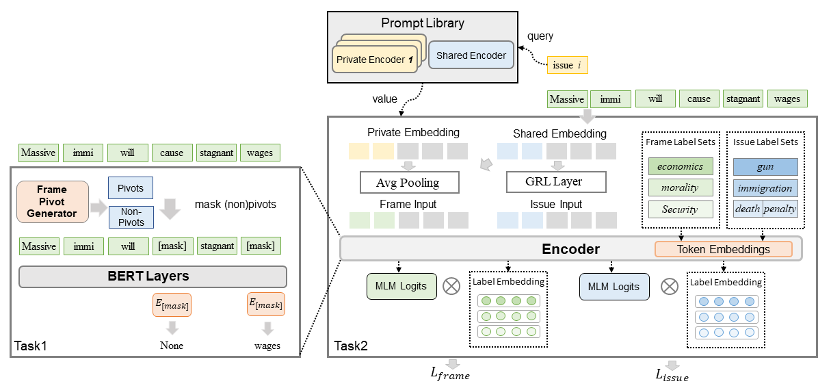
2 A Two Stage Adaptation Framework for Frame Detection via Prompt Learning
作者:牟馨忆,魏忠钰,蒋昌建,彭佳杰
类别:Long Paper,Poster
摘要:框架是一种通过选择和强调特定概念来使讨论偏向自己观点的沟通策略,框架检测任务旨在自动化分析框架策略。以往关于框架检测的工作集中在单个场景或问题上,忽略了框架沟通的特殊性,即被讨论的新事件不断出现、政策议程动态变化。为了更好地处理不同场景、问题和类型的框架检测,我们提出了一个两阶段适应框架。在基于预训练的框架域适应阶段中,我们设计了基于框架枢轴和提示学习的任务,以学习可迁移的编码器、提示库和语言表达器。在下游场景泛化阶段,将可迁移的组件应用于新的问题和标签集合。实验结果证明了提出框架在不同场景下的有效性,同时也在全资源和低资源条件下都表现出优势。
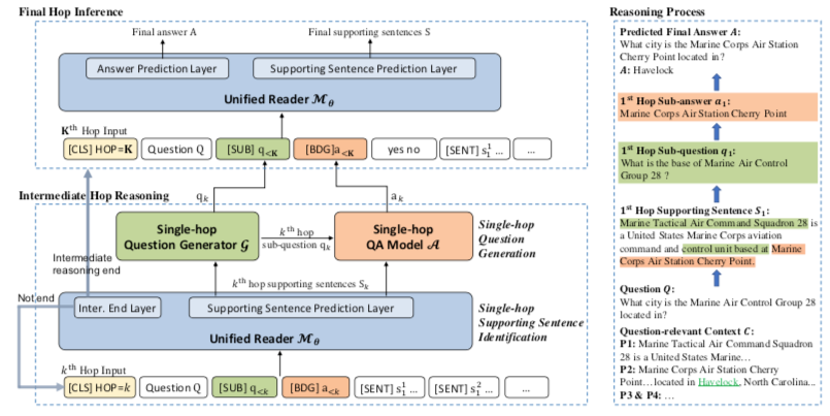
3 Locate Then Ask: Interpretable Stepwise Reasoning for Multi-hop Question Answering
作者:王思远,魏忠钰,范智昊,张奇,黄萱菁
类别:Long Paper,Poster
摘要:多跳推理需要聚合多个文档来回答复杂的问题,现有方法通常将多跳问题分解为更简单的单跳问题以显示可解释的推理过程,然而他们忽略了每个推理步骤的支持事实,从而产生不准确的分解。本文我们提出了一个可解释逐步推理框架,在每个中间步骤结合单跳支持句识别和单跳问题生成,并利用当前跳的推理内容进行下一步,直到推理出最终结果。我们采用统一阅读器模型进行中间跳推理和最终跳推理,并采用联合优化进行更精确更稳健的多跳推理。我们在数据集HotpotQA和2WikiMultiHopQA上进行了实验,结果表明我们的方法可以有效地提高性能,在没有问题分解监督数据的情况下也可以产生更好的可解释推理过程。
4 A Structure-Aware Argument Encoder for Literature Discourse Analysis
作者:李寅子*,陈伟*,魏忠钰,黄煜俊,王楚珺,王思远,张奇,黄萱菁,吴力波
类别:Short Paper,Poster
摘要:现有的论点表示学习研究倾向于平等对待句子中的词元(token),而忽略了形成论辩语境的隐含结构。特别是,在科学文献中,大量术语的使用会给论证结构的分析带来额外的困难。在本文中,我们提出了一种新颖的结构感知论点编码器,用于文献话语分析。具体地,我们提出将词元分为两组,即框架词和主题词,并提出论点注意力机制以对不同组的词元之间注意力机制的交互进行建模,以捕获论点的结构信息。此外,我们还考虑段落级的位置信息来学习论点的高级结构。在自建的气候领域的科学文献语料库和一个公开的生物医学文献语料库上的实验结果表明了我们模型的有效性。
备注:*共同一作

📝论文解读投稿,让你的文章被更多不同背景、不同方向的人看到,不被石沉大海,或许还能增加不少引用的呦~ 投稿加下面微信备注“投稿”即可。
EMNLP 2022 和 COLING 2022,投哪个会议比较好?
ACL'22 | 快手+中科院提出一种数据增强方法:Text Smoothing
阿里+中科院提出:将角度margin引入到对比学习目标函数中并建模句子间不同相似程度
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套! 后台回复【五件套】
下载二:南大模式识别PPT 后台回复【南大模式识别】投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!














 1309
1309











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









