






每天给你送来NLP技术干货!
©作者 | 社媒派SMP
来源 | 社媒派SMP
排版 | PaperWeekly
论文标题:
A Progressive Framework for Role-Aware Rumor Resolution
论文作者:
陈蕾(复旦大学),李冠颖(复旦大学),魏忠钰(复旦大学),杨洋(浙江大学),周葆华(复旦大学),张奇(复旦大学),黄萱菁(复旦大学)
收录会议:
The 29th International Conference on Computational Linguistics

论文简介
社交网络是当前重要的信息传播媒介,然而其相对自由和开放的发言环境,也助长了谣言传播。早期,学者们通过挖掘谣言本身的语言学特征进行自动化的谣言判别。然而消息本身的特征较为单一,目前研究大多认为社交网络中的谣言在公众参与下具有自证性,即通过传播过程中产生的评论或转发内容可辅助对消息真实性的判别。
我们的工作聚焦于对信息传播树的建模。通过消息的转发关系可构建信息传播树,借助自然语言处理技术,可对传播链路进行建模,从而实现对谣言真实性的分类。可采取的实施路线包括根据转发文本时间形成序列化结构(如 CNN/RNN)、根据转发关系或用户网络抽象为树结构(如 RvNN/treeLSTM)或图结构(如 GNN)。
得益于注意力机制的发展,现有工作能较好捕捉判别谣言相关的消息和用户,并提供一定程度的可解释性。然而此类方法仅仅对随机划分的数据集有效,现实生活中热点事件的重复率较低,现有模型对未在训练语料中出现的消息词汇的泛化能力较差。
此项工作立足于社会科学研究对谣言传播机制的探索,提出了谣言判别的渐进式框架,构造了信息引爆点识别任务(trigger identification),进而辅助对不实信息进行判别。
信息引爆点(trigger)指的是对谣言传播具有显著推动作用或对谣言判别具有明显指示意义的消息,我们将其细分为以下 4 类:1)开启话题(amplify),指引入了新观点或扩大了讨论范围的消息;2)反对质疑(deny),指对上文提出反对或质疑意见的消息;3)澄清说明(clarify),指含有事实依据对观点进行解释说明的消息;4)无实义的(Null),指没有指示性的消息。

我们在现有的 PHEME 数据集上补充了消息级别标注,并构造了可进行消息角色感知的图循环神经网络模型,经实验验证,能有效提升谣言判别的性能。

任务描述
谣言判别是在传播树级别上进行的分类任务,即给定一条未经证实的谣言信源及相应的转发消息,预测传播树的真实性,将其分类为真实的(True)、虚假的(False)和未能证实的(Unverified)。信息引爆点识别是在消息级别进行的分类任务,即对传播树中涉及的每一则消息 ,将其分类为开启话题(Amplify)、反对质疑(Deny)、澄清说明(Clarify)、无意义的(Null)。

数据标注
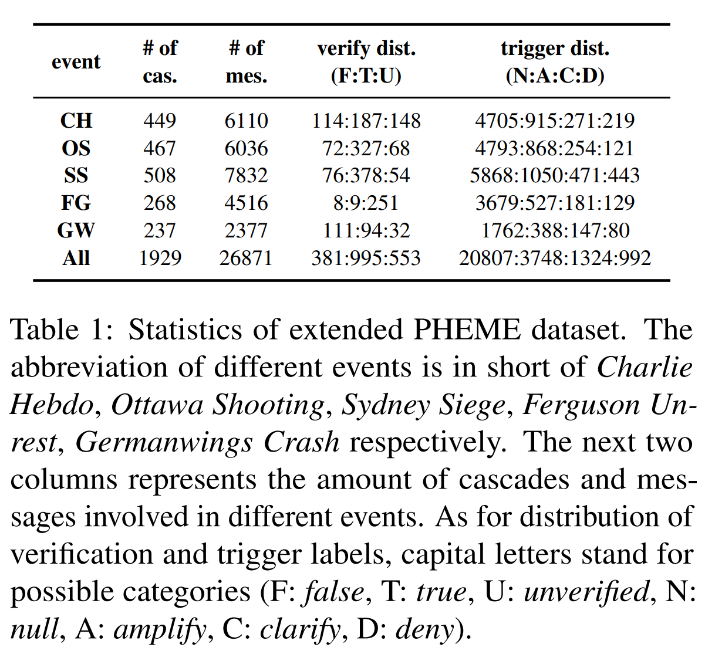
基于 Zubiaga 等人在 2016 年提出的 PHEME 的数据集,我们完成了在消息级别上的标注,补充了信息引爆点识别任务的标签。标注过程由三部分组成。首先设计了基于可视化传播树的标注系统。接着,招募了新闻专业的本科生对所有消息进行标注,每个传播树分别由 3 名学生标注,只有当 2 人的标注结果吻合,才将其视作为最终的标签,否则将此条消息标注为无意义的(Null)。最后,使用 Fleiss 卡帕系数评估标注质量,结果为 0.515。扩展数据集的统计特征如下表所示。

数据分析
在完成数据集标注后,我们探索了不同类别的消息在内容连贯性和时序变化情况的不同。
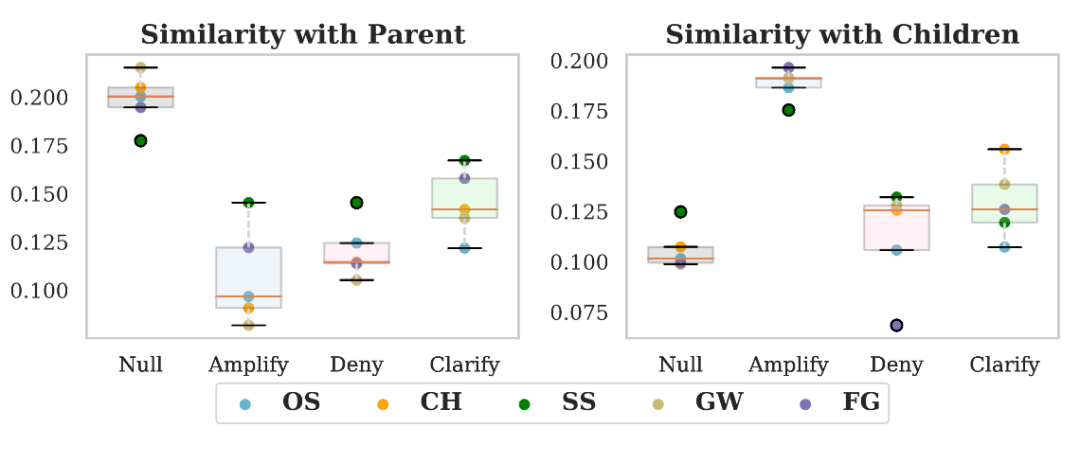
内容连贯性是通过和上文和下文的文本相似度来呈现的,和上文的相似度由该条消息和父节点之间相同词汇数量与最长文本词汇数量的比值来确定。和下文的相似度通过计算出和每条子节点文本的相似度后取平均来确定。
对 4 类消息分别计算不同事件中两类相似度的平均值,绘制箱形图有以下发现:
1. 从整体上来看,对于不同事件的数据,各种类别的引爆点在文本相似度呈现出较高的一致性,说明了信息引爆点在不同事件背景下也具有类似的文本交互特征;
2. 对于不同类别的引爆点,开启话题的引爆点和父节点相似度较低、而和子节点的相似度极高,说明子节点大多基于新话题开始讨论;反对质疑的引爆点和父节点以及子节点的相似度都较低,大多包含否定态度类的情感词汇;澄清说明的引爆点和父节点、子节点的相似度处于中等水平,会更多的基于上文文本进行阐述。
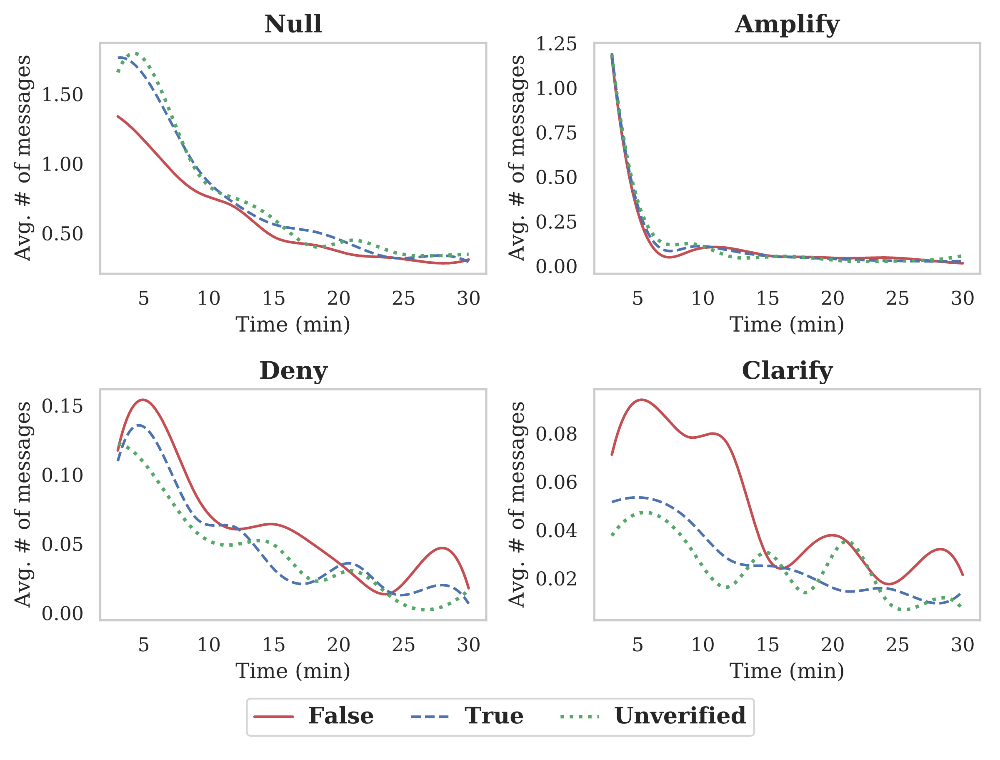
时序变化是分析不同类别的引爆点在谣言传播的不同阶段所占比例的不同。筛选了近一半的传播时间超过 30 分钟的信息传播树,统计在每 3 分钟内不同类别的消息在所有消息中的比例。
通过折线图呈现不同类别消息所占比例随时间的变化,有以下发现:
1. 从整体来看,对所有类别的信息,早期的讨论都较为剧烈,讨论热度随时间变化有衰减趋势;
2. 反对质疑的消息在虚假谣言中的比例远高于其他两类谣言;澄清说明在虚假谣言中比例也较高,并且在前期较长时间段内都频繁出现,因而鉴别不同类别的信息也会对最终的谣言判别有辅助作用。

建模思路
我们提出了非对称的图循环神经网络对信息传播图中消息的传播方向、交互特征进行建模,并使用引爆点识别的结果进行角色感知的信息融合,从而完成渐进式的谣言判别,整体框架如下图所示。
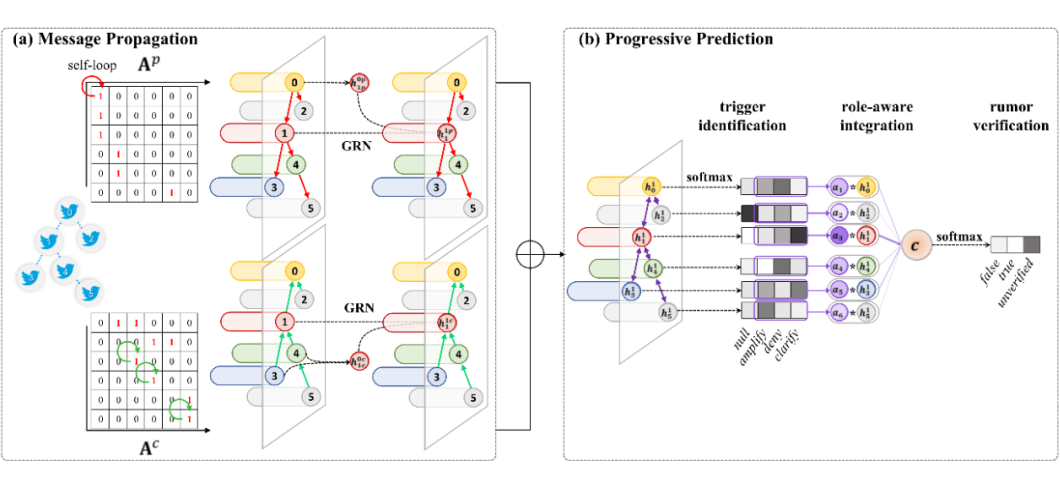
在传播图初始化中,使用传播的消息代表节点,转发关系代表边,使用 Bertweet 获取的句向量对节点表示进行初始化。
在传播图解构中,根据信息传播方向将传统邻接矩阵拆分两个,分别代表从父节点到子节点、从子节点到父节点的信息流向。
在消息交互时,采用图循环神经网络层,根据邻接矩阵进行信息融合,并使用循环神经网络进行层间信息传递。接着将两种流向所获得节点表示进行拼接,用于信息引爆点识别任务。
接着,在传播图信息融合时,利用信息引爆点的标签,忽略无意义类别维度的信息,将剩余维度加和计算融合权重,获取全图表示,从而完成谣言判别任务。

实验结果
实验采取两种测试方式:① RANDOM - 随机将数据集划分为训练、验证、测试集合;② LOEO- 固定类别较为均匀的 1 个事件数据作为验证集,剩余 4 个事件分别将 1 个事件作为测试集,其余数据作为训练集,对 4 次实验结果取平均。由于两个任务的标签分布都极为不均,采用宏平均 F1 值(macro F1)作为实验评价指标。
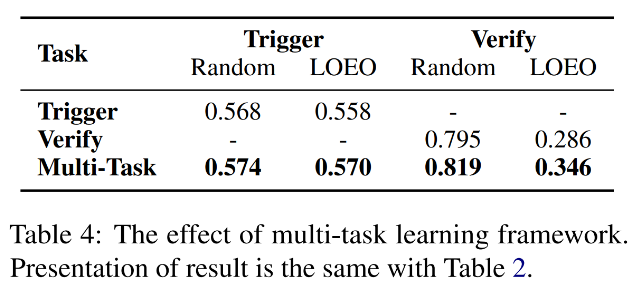
实验与目前广泛采用的传播链路建模的基线模型进行了对比,结果如表 2 所示,在引爆点识别和谣言判别任务均有表现优异,尤其对于谣言判别任务提升明显。
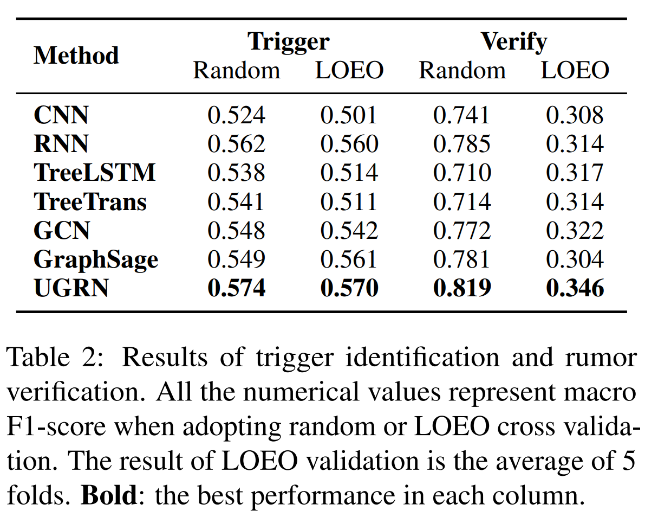
消融实验结果如表 3所示,对比不进行传播图解构与仅采用单向信息流所获取的节点表示,验证了考虑传播方向的有效性。
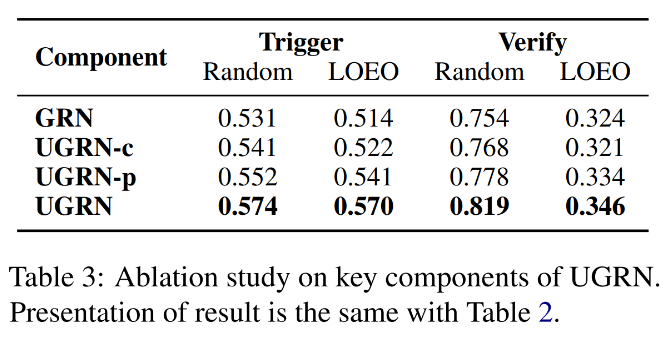
表 4 对比了单任务与多任务的实验性能,实验结果显示考虑信息引爆点对谣言判别任务的性能有显著提升。
此外,我们还探索了渐进式的判别机制的有效性。对于提出的模型和基线模型,我们将角色感知的加权方式修改为传统的注意力方法,在 12 组实验中,9 组实验采用角色感知的加权方式取得了更优的性能。

总结
在这项工作中,我们构造了“引爆点识别”的新任务,以期识别出在对谣言传播具有推动作用或对谣言判别有指示作用的消息。对 PHEME 数据集进行了扩展,对 2 万余条推特消息进行了标注,数据分析表明信息引爆点在社交网络中更具有泛化属性,尽管信息引爆点在整体消息中占比较低但却对谣言判别具有辅助作用。此外还构造了非对称的图循环神经网络对信息传播树进行建模,采用渐进式的框架完成信息引爆点识别以及谣言判别两项任务。实验结果表明,该模型在两项任务上都能取得较好的性能,在跨事件的表示学习中也有性能的提升。
📝论文解读投稿,让你的文章被更多不同背景、不同方向的人看到,不被石沉大海,或许还能增加不少引用的呦~ 投稿加下面微信备注“投稿”即可。
最近文章
DiffCSE: 将Equivariant Contrastive Learning应用于句子特征学习
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套! 后台回复【五件套】
下载二:南大模式识别PPT 后台回复【南大模式识别】投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注~















 722
722











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









