







来自:Jina AI
精准的图像描述不仅可以让人们更容易理解图像背后的故事和信息,还可以让图像更易于被检索和识别。然而,对于那些复杂的图像来说,写出既准确又详细的描述实在是件非常困难的事情。
图像描述算法的演变
所谓 Image Caption(图像描述)任务,就是让计算机能够根据一张图片自动生成相应的文字描述。在早期的模型,比如 OpenAI 的 CLIP,利用了无监督学习和微调技术,通过海量的图片和文本数据集进行了训练,理解了图片和文本间的联系,从而能够生成有意义的图像描述。
后来,一种名为 BLIP-2 的算法应运而生,它采用了更高效的预训练策略。BLIP-2 利用现成的冻结预训练图像编码器和大型语言模型,通过一个轻量级的查询式 Transformer 来连接不同的模态。不仅减少了训练参数,还保证了各种视觉-语言任务上取得 SOTA 表现。
得益于多模态技术的不断发展,图像描述这个需要结合 CV 和 NLP 的老大难问题在近些年里迈出了一大步。但直到现在,大部分 AI 生成的图像描述都比较笼统简短,难以充分展示图像的丰富内涵。尤其为复杂图像所生成的文本描述在准确性方面仍存在明显不足,更别提那些涉及多个物体、互动和复杂细节的图像了。
现有图像描述解决方案面临的挑战
1. 过于简化或空泛的论述
如图,大多数图像字幕算法给出的是“一个人和一条狗”,看似准确,但其这张图里有非常丰富的物体和故事。他们在外面做什么,他们为什么会露营,右边的背包有什么暗示吗?

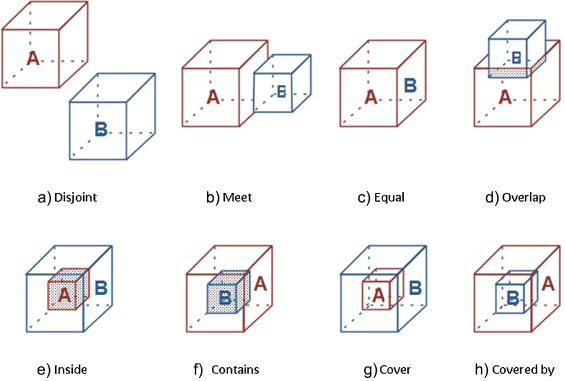
2. 缺少细微差别和关系
如图,简单地给出“对象 A 和对象 B”的描述是远远不够的,两者间的空间关系传达了截然不同的内涵。
3. 处理噪音和糟糕的图像质量
如图,中间显示的“攻击”对比扰动原来照片,尽管人类眼睛瞟一眼就知道和原始图片没变化,但图像描述算法依然标错了分类。

4. 难以处理复杂图像
对于经典画作,如下图,很多图像描述算法只能给出简单的“波提切利的维纳斯的诞生”的说明,单单一个名字实在让人一知半解,让观众无法理解图像所展现的品味。

👓 SceneXplain 生成的描述
一幅标志性的画作「维纳斯的诞生」展开在眼前,女神维纳斯从贝壳中诞生,周身环绕着神话人物和天界人物,包括美人鱼、天使和手持花束的女人。这些人物之间微妙的交互营造出一种迷人和惊奇的感觉,宛如在庆祝维纳斯降临于人世。这优雅的构图引领观众进入神话领域,惊叹于这个永恒场景所展现的壮丽和优雅。
相比起上面生成的枯燥无味的标题,由 SceneXplain 生成的这样一段丰富生动的描绘不仅能够帮助我们更好地欣赏图像,还能让我们深入了解其审美价值。
应对多媒体内容的挑战,SceneXplain 让故事破图而出
总而言之,现有图像字幕解决方案取得了很大进步,能够为图片生成相关的描述,然而还无法为复杂图像生成细节、上下文和细微差别的描述。如何进一步提高处理这样复杂图像的能力,是当前图像描述技术面临的重要挑战。
这也正是 SceneXplain 一个箭步跨进来的契机,这是一个颠覆性的工具,它不止停留在表面,而是进一步拓宽了图像描述的边界。它突破了传统图像描述算法的局限性,提供了简练专业、引人入胜的图像叙事体验。凭借 用户友好的界面、无缝 API 集成 和 强大的多语言支持,方便开发者轻松集成到他们的多模态应用中。

SceneXplain 生成的文本拓展了图片的表现力,不管是动漫,风景,商品,还是产品 UI,它都准确识别了图片中关键信息,理解了画面表达的气氛,并深入捕捉到了图片中的细节,并用流畅连贯的语言完成了描述。


<<< 左右滑动见更多 >>>
SceneXplain vs Midjourney describe
我们对 SceneXplain 与市面上流行的图像描述工具和算法的性能进行了测评。
SceneXplain:生成详细、复杂、生动、富有上下文的文本描述,为复杂视觉内容提供先进的图像描述解决方案。
Midjourney:最近发布的
/describe功能,旨在将图像转化为文本提示词。
注意:相比起 /describe 生成的是图像提示词 Prompt,而 SceneXplain 生成出的是详细、复杂、生动、富含上下文的图像描述,更适合人类阅读。 此外,我们还对比了
BLIP-2:一种高效的预训练策略,使用现成的冻结的预训练图像编码器和大型语言模型进行视觉语言预训练,可在训练参数大大减少的情况下,实现各种视觉语言任务的 SOTA 性能。
CLIP Interrogator 2.1 专门设计给 Stable Diffusion 2.0 模型生成图像提示词。
接下来让我们将这些算法对同一图片进行描述,展示它们在各种图像描述任务中的效果。完整的 Benchmark 表格请在公众号回复 SceneX 获取。
相比之下,Midjourney /describe 和 CLIP Interrogator 2.1 等解决方案侧重于为图像生成对应提示词,而非让人类轻松阅读的自然语言描述。 同时,BLIP-2 生成的字幕非常简短、粗略且生硬,仅包含几个相关词汇,可能适用于简单的场景,但难以捕捉到更为复杂的视觉细节,从而忽略了关键信息,无法展示图像的丰富内涵。
而 SceneXplain 填补了这一块空白,深入、准确、丰富 —— 面对复杂图像,SceneXplain 让图像描述更上一层楼。 它兼顾了准确性和深度,它能够深入到复杂场景里错综复杂的细节,并基于这些细节的微妙关联,比如空间位置,依赖关系等,构建出流畅连贯的叙事。这种结构化叙事让观众能够从更高的视角去理解图像所呈现的复杂概念和场景,使得图像栩栩如生,故事得以生动诉说。
当然,我们也必须要承认 SceneXplain 在简单场景下有些矫枉过正,会出现一些幻觉。
SceneXplain 的优势
与其他图像描述解决方案相比,SceneXplain 具有许多优势:
抗噪声和变化的图像质量
SceneXplain 背后强大的 AI 算法增强了其对各种图像质量的理解能力,哪怕是低分辨率、模糊不清或带有噪点的图像,SceneX 也能基于有限的信息推断图像内涵,确保生成的描述保持准确性。
<<< 左右滑动见更多 >>>
多语言支持
SceneXplain 有强大的多语言支持,可以生成多种语言的上下文丰富的图像描述。
应用场景
我们期待您探索和体验 SceneXplain 的能力,它的潜在应用非常广泛,比如三个关键领域:
视觉叙事升级:SceneXplain 的丰富描述能够把简单的视觉图像转化为真正引人入胜的叙事体验。这种叙事升级能够在各个场景下得以运用,比如电商产品详情页的撰写,通过详细的图像描述,为用户提供更丰富的浏览体验。
优化 SEO:SceneXplain 生成的生动且丰富的描述包含大量的关键词,这有助于提高内容的搜索引导性和点击率,从而有可能带来网站排名的提升和来自搜索引擎的更多流量。
提高可访问性:SceneXplain 生成的描述能够充分解释图像细节和含义,从而有望彻底改变无障碍多媒体内容的创建和消费方式,改善视觉障碍用户的网络体验。
从三个关键领域对应的场景上,SceneX 也有许多应用空间,对于 社交媒体内容创作者,美食博主,旅游博主等为拍摄的图片生成更加具体生动的描述,提高图片素材的影响力;在线电商企业 可以用来描述商品,用关键词和描述语句丰富产品详情页描述,提升 SEO;博物馆等公共服务行业 用于为展品创建详细的文字描述,帮助视障人士更好地欣赏等等。
如何将 SceneXplain 集成到您的应用中
SceneXplain 提供多种集成选项以满足不同组织的需求。
1. 通过网页生成图像描述
2. 通过 API 批量处理图像
对于寻求自动化和无缝集成的组织,SceneXplain 为其系统提供了强大、可扩展且安全的 API。快速批处理 API 允许在 50 秒内在一个批次中描述多达 128 张图像。
3. 作为 ChatGPT 插件使用
对于 ChatGPT Plus 用户来说,可以在 ChatGPT 插件里使用。
4. 本地隐私保护解决方案
对于数据安全和隐私有严格要求的组织来说,我们提供本地解决方案,您可以在自己的服务器上部署 SceneXplain,确保了敏感数据保留在自己的网络中,同样无缝集成 SceneXplain 的高级图像描述。
添加技术运营微信 jinaai01,或扫描文末二维码,与我们的团队约定会议了解本地解决方案。
SceneXplain 的核心优势在于它能精准捕捉到图片中多个物体之间的关系和互动,同时考虑它们在场景中的位置,以及周围环境的氛围。这些细节在普通的图像描述工具里经常被忽略,但 SceneXplain 不仅在生成文本描述时保留了这些细节,还提供了更多的情境感,将视觉内容的精髓高效地呈现出来,帮助读者更好地理解图像所呈现的内容。无论是社交媒体、电商网站,还是公共服务领域,它都能大显身手。
赚积分享折扣,产品功能等你来探索!
现在登录 Scenex.jina.ai 官方网站,即可免费获得 20 积分!探索功能还可能获得更多免费积分,如上传第一张图片即可获得「快照感觉」,复制图片描述即可获得「剪贴板鉴赏家」。心动不如行动,看热闹不如看门道!现在就来开启你的故事之旅!
🔗:https://scenex.jina.ai/
首次登录的用户将自动得到一张 8 折的全产品优惠券,24 小时内购买会员还可享受优惠折扣!
快来注册吧,限时特惠!
点击“阅读原文”,即刻体验 SceneXplain

















 500
500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









