






 文章介绍了提示学习在自然语言处理(NLP)中的应用,通过模板设计来减少预训练模型与下游任务之间的差距。主要内容包括模板的类型、形状和构成,如ClozePrompt和PrefixPrompt,以及手动和自动模板生成方法,如LPAQA、PET、AutoPrompt和LM-BFF。这些方法在少样本和零样本情况下,通过优化模板和答案,提升模型预测性能。
文章介绍了提示学习在自然语言处理(NLP)中的应用,通过模板设计来减少预训练模型与下游任务之间的差距。主要内容包括模板的类型、形状和构成,如ClozePrompt和PrefixPrompt,以及手动和自动模板生成方法,如LPAQA、PET、AutoPrompt和LM-BFF。这些方法在少样本和零样本情况下,通过优化模板和答案,提升模型预测性能。
来自:SUFE AI Lab
进NLP群—>加入NLP交流群
1.提示学习:基于模板的 NLP 微调范式
自 BERT、GPT 等大模型面世以来,自然语言处理任务多遵循“预训练(Pre-train)- 微调(Fine-tuning)”的过程,通过引入预训练语言模型(Pre-trained Language Model,PLM)进行下游任务的微调在诸多应用场景上已经取得了较好的表现,然而,该过程忽略了下游任务目标与预训练模型目标存在不一致的问题,且仍然需要引入大量训练数据以支持在具体任务上的微调过程,而提示学习方法(Prompt Learning) 正是通过设计模板使得下游微调任务的训练方式与预训练任务更接近,故在提示学习方法下的自然语言处理任务过程变成了“预训练(Pre-train)- 基于提示学习模板的微调(Prompt-tuning)”,并且在少样本及零样本情况下仅对少量参数进行微调就能够有较好的表现。
提示学习方法需包含模板及答案两部分的设计,以经典的 BERT 分类任务为例,其预训练过程中的两个任务形式为:
1.1 掩码语言模型(Masked Language Model,MLM)
输入句子:this movie is good
训练任务:this movie is [MASK]
1.2 下句预测(Next Sentence Prediction,NSP)
输入句子对:{this movie is good, i like it}
训练任务:[CLS] this [MASK] is good [SEP] [MASK] like it [SEP]
传统的下游任务微调方式将输入改造为BERT预训练任务中的掩码形式,并通过[CLS]标签的线性层将结果映射到预测任务空间中,然而在BERT的预训练任务中[CLS]标签为两个句子输入是否为上下句的预测结果,但分类任务的预测目标实则为分类结果,由此可以看到预训练任务和下游任务在预测目标上实际上是存在GAP的,而提示学习的思想就是利用了预训练模板与真正的预测目标间关联性的可提升空间,通过设计具体场景的模板使得下游任务在任务形式上与预训练模型更接近以进一步提升预测表现,两种训练方式设计如下所示:
传统微调方法
输入句子:我今天真的很高兴
训练任务:[CLS] 我今天真[MASK]很高兴 [SEP]
基于提示学习模板的微调方法
输入句子:我今天真的很高兴
训练任务:[CLS] 我今天真的很高兴。我的情绪是 [MASK] [SEP]
其中“我的情绪是[MASK]”是为情感分类任务设计的模板,该过程被称为模板工程,而[MASK]标签将根据具体的任务设计映射为最终的分类结果(例如:{正面,负面}),该过程则被称为答案工程,通过设计更符合具体任务场景的模板及答案,NLP模型在学习过程中能够更好地被“提示”以进一步提升预测表现。
2.模板类型
模板出现的位置、数量及构成类型等因素都会造成结果的差异性表现,故在具体任务中需要根据任务目标及训练模型结构进行调整。
从模板形状上进行分类,模板设计中的答案映射[MASK]常出现在句中或句末的位置,在句中出现被称作完形填空式模板(Cloze Prompt),常用于MLM任务,而在句末出现被称作前缀型模板(Prefix Prompt),常用于生成式任务。
从模板构成上进行分类,无论是模板还是答案,都可划分为软、硬两种形式:硬模板(Hard Prompts) 又被称作离散型模板(Discrete Prompts),由基于离散空间映射的自然语言组成,符合人类语义表达形式的硬模板往往具有较强的可解释性;而软模板(Soft Prompts) 又被称作连续型模板(Continuous Prompts),该方法取消了模板基于自然语言离散空间的限制以期更好的启示模型训练;此外,也存在结合两种模板的混合型模板设计。
离散型模板常依赖于专家知识由人工设计(经典方法下见3.1手动模板),在此简要介绍几种常见的连续型模板方法:
2.1 Prefix-tuning
论文名称:Prefix-Tuning: Optimizing Continuous Prompts for Generation
作者:Xiang Lisa Li, Percy Liang
来源:ACL-IJCNLP 2021
链接:https://arxiv.org/abs/2101.00190

Prefix-tuning 基于自回归语言模型,针对句子构造形如[Prefix, X, Y]的模板,或设计多段模板如[Prefix, X, Prefix’, Y]作为模型输入,其中Prefix为隐藏层数为h的可训练参数矩阵,并在其上设计了一层MLP结构,并且在下游任务中固定预训练模型参数,仅针对依赖于预训练模型参数的Prefix参数进行微调,该方法仅使用较少的训练参数就能在low-data settings和unseen topics场景有着较好的表现,极大程度减轻了训练大模型的成本开销。
2.2 Prompt-tuning
论文名称:The Power of Scale for Parameter-Efficient Prompt Tuning
作者:Brian Lester, Rami Al-Rfou, Noah Constant
来源:EMNLP 2021
链接:https://arxiv.org/abs/2104.08691
Prompt-tuning基于Seq2Seq的生成式模型T5,对Prefix-tuning进行了简化,该方法取消了模板参数对预训练参数的依赖限制,使用独立的模板参数在冻结预训练模型参数的情况下进行微调,并提出可以训练多个软模板进行投票预测。
其他常见的连续型模板方法有将单向MLP结构拓展为LSTM以捕捉双向特征的P-tuning及其优化版本P-tuning v2等方法。
3.模板生成方式
从模板生成方式上看,可划分为基于人工知识的手动模板设计方法和由模型不依赖于人类知识生成的自动模板方法。
3.1 手动模板
在具体领域中,专家的领域知识往往能对模板设计起到较大的帮助,一个贴合场景的手动模板甚至能够超过复杂算法搜索出的自动模板。下对两种经典的手动模板方法进行介绍:
3.1.1 LPAQA (Language Model Prompt And Query Archive)
论文名称:How Can We Know What Language Models Know?
作者:Zhengbao Jiang, Frank F. Xu, Jun Araki, Graham Neubig
来源:TACL 2020
链接:https://arxiv.org/abs/1911.12543
LPAQA方法针对知识探针任务优化LAMA数据集(可视作离散型模板),由关系挖掘及回译方法两部分组成。
在关系挖掘中,该方法提出了基于句子的主谓宾关系和中间词的两种抽取方式,其中依赖路径方法(Dependency-based Prompts)将句子成分间的依赖路径视作模板,例如从“France of capital is Paris”提取出模版“capital of x is y”,而中间词方法(Middle-word Prompts)将[主语][中间词][谓语]句子形式中的中间文本视作模板。
在保持模板语义的基础上,回译方法为增加了词汇多样性通过反向翻译(Back Translation),将句子翻译到另一种语言再翻回原语言以生成多个样本,并根据往返概率(Round-trip Probability)筛选出模板。
3.1.2 PET (Pattern-Exploiting Training)
论文名称:Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference
作者:Timo Schick, Hinrich Schütze
来源:EACL 2021
链接:https://arxiv.org/abs/2001.07676
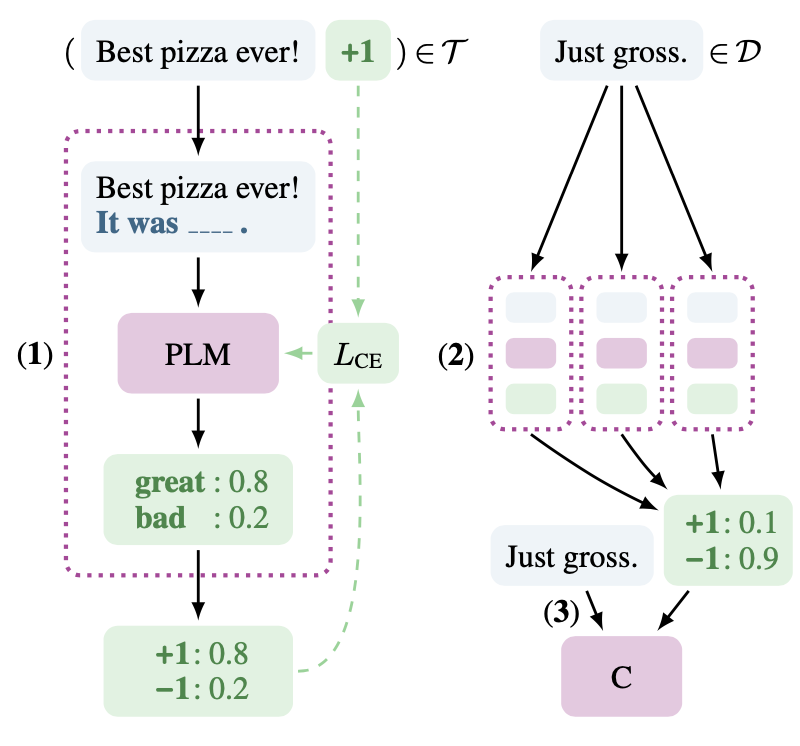
PET 是一种半监督方法,首先针对少量的有标签样本集上,根据场景任务手动设计多个完形填空式模板及答案映射(e.g. Best pizza ever! It was __ .) 分别进行训练,其次在无标签数据上进行预测,通过所有设计的模板预测结果进行加权归一化进行知识蒸馏,获得最终的模型结果。
3.2 自动模板
自动模板方法不依赖于人工知识,通过算法自动搜索优化最优的模板设计,下对两种经典的自动生成模板方法进行介绍:
3.2.1 AutoPrompt
论文名称:AUTOPROMPT: Eliciting Knowledge from Language Models with Automatically Generated Prompts
作者:Taylor Shin, Yasaman Razeghi, Robert L. Logan IV, Eric Wallace, Sameer Singh
来源:EMNLP 2020
链接:https://arxiv.org/abs/2010.15980
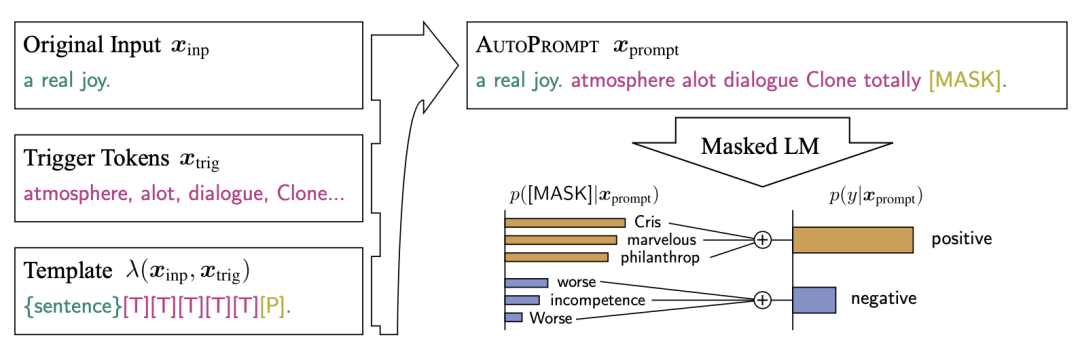
AutoPrompt 设计了形如{sentence}[T]...[T ][P]的模板,其中[T]为触发词(Trigger words),[P]为预测标签的预留位置,基于该预设模板上进行梯度搜索以生成最优模板。
在答案搜索上,该论文使用[MASK]标签作为初始值,记分类标签Label为,第i个模板触发词为,和为权重和偏差项,使分类器最大化给定标签候选词下对应Label出现的概率,并选择前个标签作为最终生成的答案:
在模板搜索上,该论文在固定了预设模板,以[MASK]为初始值,在top-k个候选词中通过梯度搜索,最大化在预设模板下对应标签出现的概率,选取第n个epoch的模板结果作为最优模板。
3.2.2 LM-BFF
论文名称:Making Pre-trained Language Models Better Few-shot Learners
作者:Tianyu Gao, Adam Fisch, Danqi Chen
来源:ACL 2021
链接:https://arxiv.org/abs/2012.15723
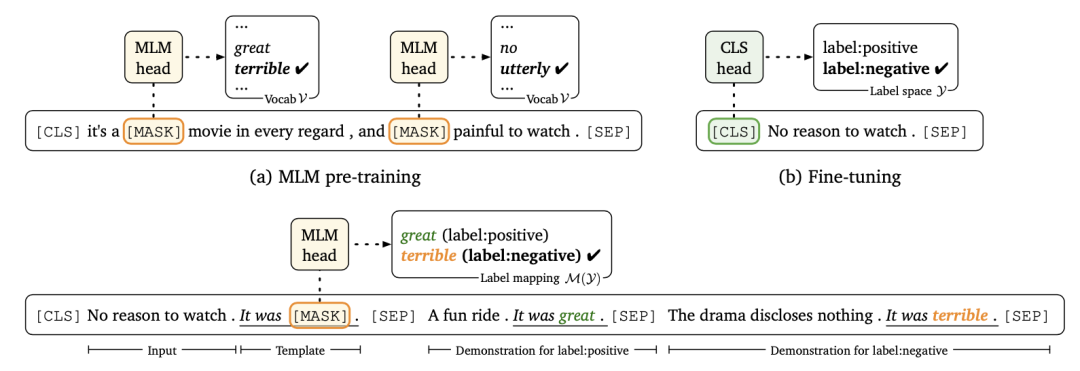
LM-BFF 针对few-shot场景,延续了PET中的完型填空式模板,将模板和答案的人工构建过程优化为自动搜索,在固定模版/答案的情况下,最大化输入下对应答案/模板的概率。
此外,在下游任务过程中使用了基于示例的方式进行训练,针对某个输入句子,通过相似度计算后随机拼接与其相似的一条正样本和一条负样本作为示例,将改造后的拼接文本作为模型输入,发现“举个例子”的训练方式有效提升了模型的预测表现。
总结
本文简要概括提示学习领域的思想,从不同形状及构成的模板类型以及两种模板生产方式(手动模板&自动模板)进行了梳理,并展开介绍了一些经典的提示学习论文,包括连续型模板方法(Prefix-Tuing以及Prompt Tuning)、手动模板(LPAQS以及PET)、自动模板(Autoprompt以及LM-BFF),此外,仍有较多的优秀提示学习方法例如结合了外部知识的KPT方法、结合了场景规则的PTR方法以及对模板进行预训练的PPT方法等研究未能详细展开介绍,提示学习领域通过模板设计从更贴近预训练任务形式、更契合场景特性、更有效利用大模型预训练结果三方面对自然语言处理领域有着较大的贡献。

精研勤思,经济匡时
“十四五”规划围绕经济社会发展总体目标,在人工智能发展方面布局的重点之一是打造数字经济新优势,形成数据驱动、人机协同、跨界融合、共创分享的智能经济形态。提示学习领域在应用中正体现了“人机协同”的无限可能性,通过与行业领域专家知识的有效结合,给予人工智能机器模型有重点、有价值的指导,使得其在应用中能够实现更好的表现,进一步提升了社会生产。
进NLP群—>加入NLP交流群


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









