






前言:骆驼(Luotuo)项目是由冷子昂@商汤科技,陈启源@华中师范大学以及李鲁鲁@商汤科技发起的中文大语言模型开源项目,包含了一系列语言模型,感兴趣的可以去github上了解下,非常棒。
进NLP群—>加入NLP交流群
知乎:Cheng Li
地址:https://zhuanlan.zhihu.com/p/624662198
项目:https://github.com/LC1332/Luotuo-QA
其实从之前的Paper Reading就可以知道,对于小于50B的模型,他的知识水平是要较弱的。
所以对于6B 7B这样级别的模型,如果希望进一步提升模型的能力,就像BingGPT或者很多论文中的一样,需要形成一套 搜索——问答的系统。骆驼团队之前发布的 骆驼-Embedding(LuotuoBERT) 模型[1],就是希望进一步提升中文的模糊搜索能力。而这次,我们希望对于后面一步,问答进行进一步的调优。

这次发布的骆驼QA模型,是在唐杰老师的GLM-6B的基础上,利用陈丹琦学姐发布的CoQA数据集进行了翻译,并在翻译和增广后的CoQA数据集上进行微调而得到的。是一个专注于中文阅读理解的问答模型。这次初步发布的版本为0.1版本,日后的升级计划见下文中的讨论。
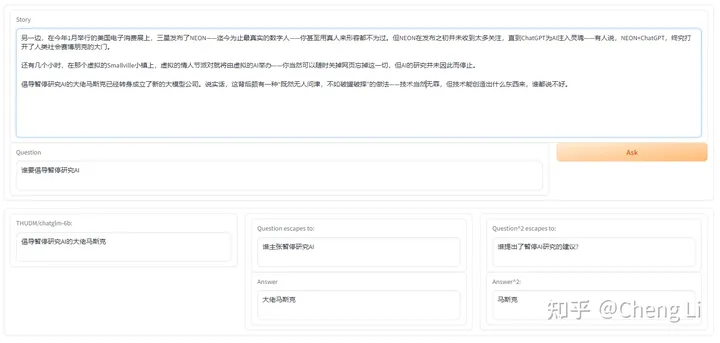
我们在这次的发布中提供了两个colab的脚本,一个是直接对模型进行测试,一个是支持Gradio交互界面的版本。打开后就可以进行测试。这里非常感谢项目的主要开发 Jansen 廖等同学付出的努力。

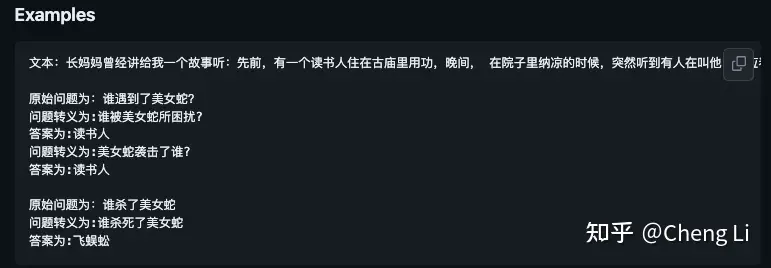
为了训练这个中文的问答模型,我们增广并翻译了陈丹琦学姐在斯坦福参与的的CoQA数据集。

因为CoQA原本的设计是为了给Chat机器人使用,里面是考虑了连续的问答和有很多带有指代的原问题。所以我们利用GPT,对每个问题进行了5次增广。给出了更为详细的问题的问法。见右图。同时我们准备逐步公开这些数据集,当然还要搭建一个数据表格申请的方式,可能在之后放出。
在给项目赞助人的开放测试中,我们发现了几个问题。
由于CoQA在构建的时候,更多是去考虑容易比较、测评的问题。在问题的构造中,很少去出现怎么样(How)和为什么(Why)这样形式的问题。这一点在开放测试中就直接fail了。

对于文本中不覆盖的问题讨论,模型没有garding的能力,或者说模型不会回答文中其实没有提到。这个我觉得在增加数据训练完一个0.3版本的之后版本中,可以去考虑提升。

目前文本覆盖的领域太少,只有几千个story,之后的版本中,我们希望借助中文wiki和各种赞助人爸爸提供的自己希望的语料,利用GPT自动生成问答对的方式,提升到2万到3万的故事级别,再乘以5会出现10万到15万个问答组合,这样看起来会更多一些。
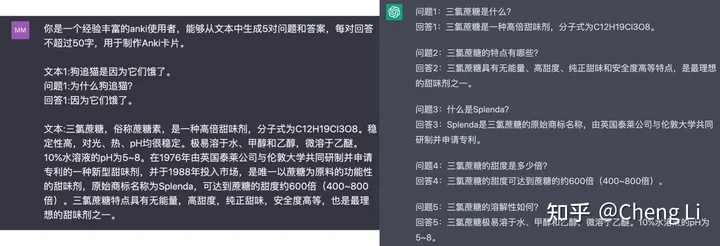
可以用之前咒术宝典中记载的这个Anki卡片的方法,来增广问答的数据,这样会产生更多的数据。另外感觉数据多了的话,那个问题转化也不一定是完全必要的。(当然也可以增广完问答之后,再增广5个不同的问题)
在骆驼QA有了初步的版本之后,我们就可以结合LuotuoBERT的搜索能力,去搭建一个Mini的BingGPT了。特别是可以针对1000个左右的私有化文档,做对应的检索和QA。
另外要提前感谢一下Hugging Face社区,已经联系到我们可以做有长期运行的Demo机器了。这个骆驼问答显然就是有意义的Demo了,我们之后会整理挂在Hugging Face的社区上。把我们的进展汇报给大家,给社区做一些微不足道的贡献。
所有的模型、测试代码、训练数据和训练代码,我们都会逐步清理和开源到我们的项目中,大家可以在我们的项目主页[2]中找到项目的所有信息,或者也可以直接去骆驼QA[3]的项目中进行查看。同时我们也在积极寻找项目的赞助以及训练算力的支持。如果您觉得我们的工作对您有帮助,拜托 到我们的Github项目主页给上star。如果没有github账号,也可以在知乎的文章直接点赞。谢谢大家!
进NLP群—>加入NLP交流群
参考资料
[1]
骆驼-Embedding: https://github.com/LC1332/Luotuo-Text-Embedding
[2]Luotuo-Chinese-LLM: https://github.com/LC1332/Luotuo-Chinese-LLM
[3]Luotuo-QA: https://github.com/LC1332/Luotuo-QA















 1024
1024











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









