






深度学习自然语言处理 分享
整理:pp
 摘要:中等规模的大语言模型(LLM)--参数为 7B 或 13B 的模型--表现出良好的机器翻译(MT)性能。然而,即使是基于 13B LLM 的顶级翻译模型(如 ALMA),其性能也无法与最先进的传统编码器-解码器翻译模型或更大规模的 LLM(如 GPT-4)相媲美。在本研究中,我们弥补了这一性能差距。我们首先评估了在 MT 任务中对 LLM 进行有监督微调的缺点,强调了参考数据中存在的质量问题,尽管这些数据是人工生成的。然后,与模仿参考译文的 SFT 不同,我们引入了对比偏好优化(Contrastive Preference Optimization,CPO),这是一种新颖的方法,可训练模型避免生成适当但不完美的译文。将 CPO 应用于仅有 22K 个平行句子和 1200 万个参数的 ALMA 模型,会产生显著的改进。由此产生的名为 ALMA-R 的模型在 WMT'21、WMT'22 和 WMT'23 测试数据集上的表现可以媲美或超过 WMT 竞赛获奖者和 GPT-4 的表现。
摘要:中等规模的大语言模型(LLM)--参数为 7B 或 13B 的模型--表现出良好的机器翻译(MT)性能。然而,即使是基于 13B LLM 的顶级翻译模型(如 ALMA),其性能也无法与最先进的传统编码器-解码器翻译模型或更大规模的 LLM(如 GPT-4)相媲美。在本研究中,我们弥补了这一性能差距。我们首先评估了在 MT 任务中对 LLM 进行有监督微调的缺点,强调了参考数据中存在的质量问题,尽管这些数据是人工生成的。然后,与模仿参考译文的 SFT 不同,我们引入了对比偏好优化(Contrastive Preference Optimization,CPO),这是一种新颖的方法,可训练模型避免生成适当但不完美的译文。将 CPO 应用于仅有 22K 个平行句子和 1200 万个参数的 ALMA 模型,会产生显著的改进。由此产生的名为 ALMA-R 的模型在 WMT'21、WMT'22 和 WMT'23 测试数据集上的表现可以媲美或超过 WMT 竞赛获奖者和 GPT-4 的表现。
https://arxiv.org/abs/2401.08417
Q1: 这篇论文试图解决什么问题?
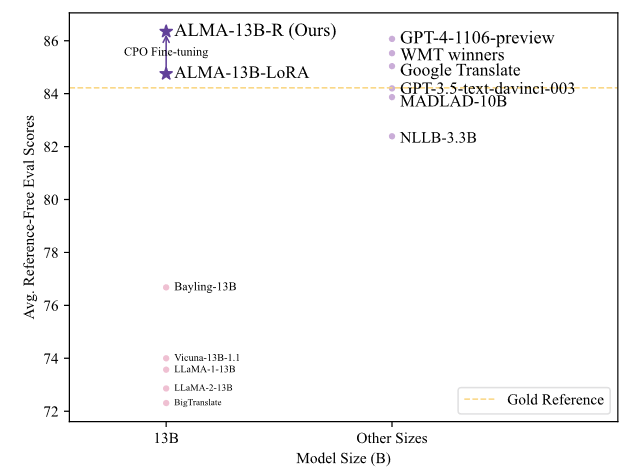
A:这篇论文试图解决的问题是中等规模的大语言模型(LLMs)在机器翻译(MT)任务上的性能与最先进的传统编码器-解码器翻译模型或更大规模的LLMs(如GPT-4)相比仍有差距。尽管像ALMA这样的模型在翻译任务上已经取得了显著的进步,但它们仍然没有达到GPT-4或WMT竞赛获胜者的性能水平。为了缩小这一性能差距,作者提出了一种名为对比偏好优化(Contrastive Preference Optimization, CPO)的新方法,通过训练模型避免生成虽然足够但并不完美的翻译,从而提高翻译质量。
Q2: 有哪些相关研究?
A:这篇论文中提到了以下相关研究:
ALMA模型:由Xu等人(2023)引入,旨在通过在多种语言的大量单语数据上进行初始微调,然后在少量但高质量的平行数据上进行监督微调(SFT),来增强中等规模LLMs的多语言理解能力。
GPT系列:由Brown等人(2020)提出,展示了在各种自然语言处理(NLP)任务中的卓越效能,激发了研究者对这些仅解码器LLMs翻译潜力的兴趣。
机器翻译中的Transformer编码器-解码器架构:由Vaswani等人(2017)提出,是机器翻译领域中主导的模型结构,如NLLB-200、M2M100、BIBERT和MT5等模型都采用了这种架构。
对比学习:如Oord等人(2018)和Chen等人(2020)的工作,展示了通过对比学习可以有效地学习数据的表示。
直接偏好优化(Direct Preference Optimization, DPO):由Rafailov等人(2023)提出,用于从人类反馈中优化策略,但在本文中作者提出了对比偏好优化(CPO)作为其更高效的变体。
参考免费评估模型:如KIWI-XXL和XCOMET,用于评估翻译质量,这些模型不依赖于参考翻译,而是直接评估翻译的好坏。
机器翻译中的参考数据质量:Kocmi等人(2023)和Freitag等人(2023)的工作指出,目标参考数据的质量对于机器翻译任务至关重要,但即使是人类编写的数据也可能存在质量问题。
机器翻译中的评估指标:如BLEU和COMET-22,这些指标在评估机器翻译系统时广泛使用,但本文指出它们可能受到参考数据质量的影响。
机器翻译中的模型大小和性能:Zhu等人(2023a)和其他研究者的工作表明,更大的LLMs(如GPT-3.5和GPT-4)展现出更强的翻译能力,但中等规模的LLMs仍然落后。
机器翻译中的多语言能力:Yang等人(2023)和Zeng等人(2023)的工作试图通过增强中等规模LLMs的多语言能力来提高翻译性能。
这些研究为本文提出的对比偏好优化(CPO)方法提供了理论基础和实践背景。
Q3: 论文如何解决这个问题?
A:论文通过以下步骤解决了中等规模LLMs在机器翻译任务上的性能问题:
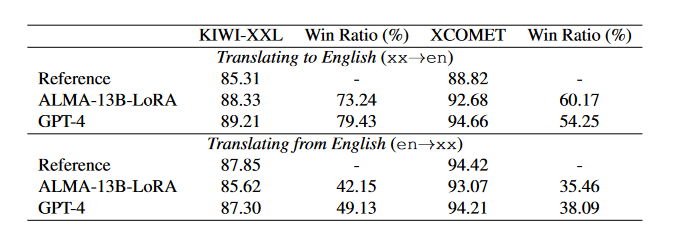
分析参考数据质量论文首先评估了用于机器翻译任务的参考数据(FLORES-200数据集)的质量。通过与强翻译模型生成的翻译进行比较,作者发现即使是人类编写的参考翻译也可能存在质量问题,这表明仅依赖参考数据进行训练可能不是最有效的方法。

引入对比偏好优化(CPO):为了克服仅模仿参考翻译的监督微调(SFT)方法的局限性,作者提出了CPO。CPO通过使用特别策划的偏好数据来训练模型,使模型能够生成更高质量的翻译,同时学会拒绝不够完美的翻译。

构建偏好数据:作者创建了一个包含源句子和三种不同翻译(参考翻译、GPT-4生成的翻译和ALMA模型生成的翻译)的三元组数据集。使用ref-free评估模型对这些翻译进行评分,并将得分最高的翻译标记为“优选翻译”,得分最低的标记为“非优选翻译”。

CPO目标函数的推导:论文详细介绍了从直接偏好优化(DPO)到CPO目标函数的推导过程。CPO通过最小化一个上界来优化模型,这个上界是基于模型预测的优选翻译和非优选翻译的概率。
实验设置:在实验中,作者使用ALMA-13B-LoRA模型作为初始检查点,并在CPO训练过程中专注于更新其LoRA权重。训练数据集是从FLORES-200数据集中派生出的,包含了10个翻译方向的2000对句子。
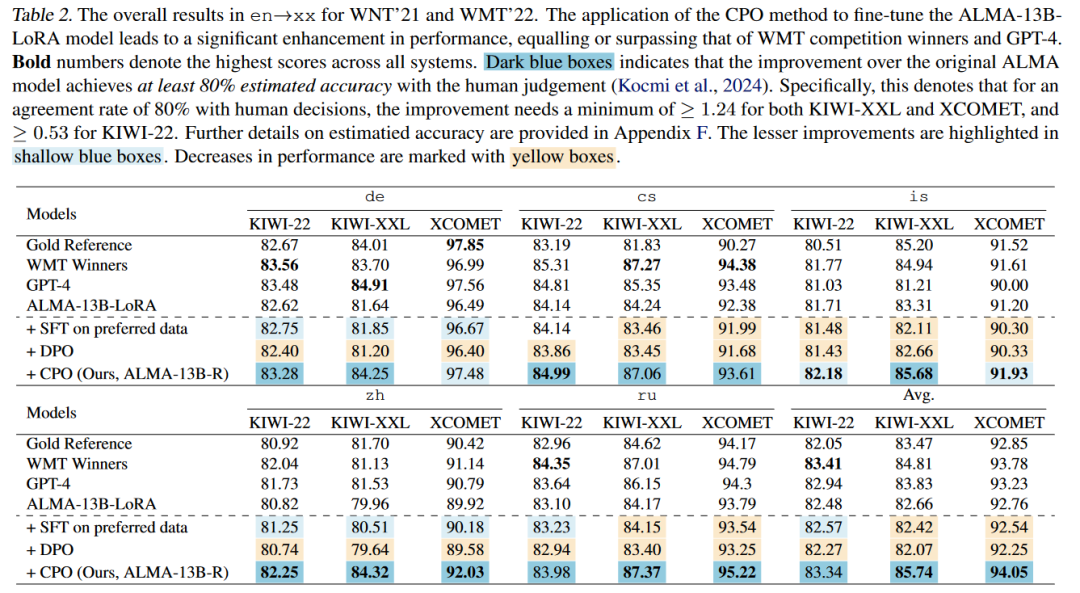
性能评估:通过在WMT'21、WMT'22和WMT'23测试数据集上进行评估,作者展示了应用CPO方法后ALMA-R模型的性能显著提升,能够匹配或超过GPT-4和WMT竞赛获胜者的性能。
通过这些步骤,论文成功地提高了中等规模LLMs在机器翻译任务上的性能,缩小了它们与最先进翻译系统之间的差距。
Q4: 论文做了哪些实验?
A:论文中进行了以下实验:
参考数据质量分析:作者对FLORES-200数据集中的参考翻译与由ALMA-13B-LoRA和GPT-4生成的翻译进行了比较。他们使用参考ref-free模型KIWI-XXL和XCOMET来评估翻译质量,并计算了模型输出超过参考翻译的比例(Win Ratio)。
对比偏好优化(CPO)的实现:作者介绍了CPO方法的实现细节,包括如何从FLORES-200数据集中构建偏好数据集,以及如何将CPO损失函数集成到模型的训练过程中。
模型训练:使用ALMA-13B-LoRA作为初始模型,作者在CPO框架下对其进行了微调。训练数据集包括从FLORES-200数据集中派生的2000对句子,并且包含了1000对内部人类标记的偏好数据。
性能评估:在WMT'21和WMT'22测试数据集上评估了微调后的ALMA-R模型。评估使用了ref-free评估模型KIWI-XXL、XCOMET和KIWI-22,以及参考基础评估指标sacreBLEU和COMET-22。
与现有技术的比较:作者将ALMA-R模型的性能与现有的技术进行了比较,包括ALMA-13B-LoRA、TowerInstruct、GPT-4以及WMT竞赛的获胜者。
分析:进行了多项分析,包括对CPO损失函数各部分的贡献进行消融研究,评估了人类标记的偏好数据的影响,以及探讨了翻译质量是否真的优于参考数据或仅仅是指标偏好。
WMT'23的实验结果:在WMT'23测试数据集上展示了ALMA-R模型的平均性能,并与WMT竞赛的获胜者进行了比较。
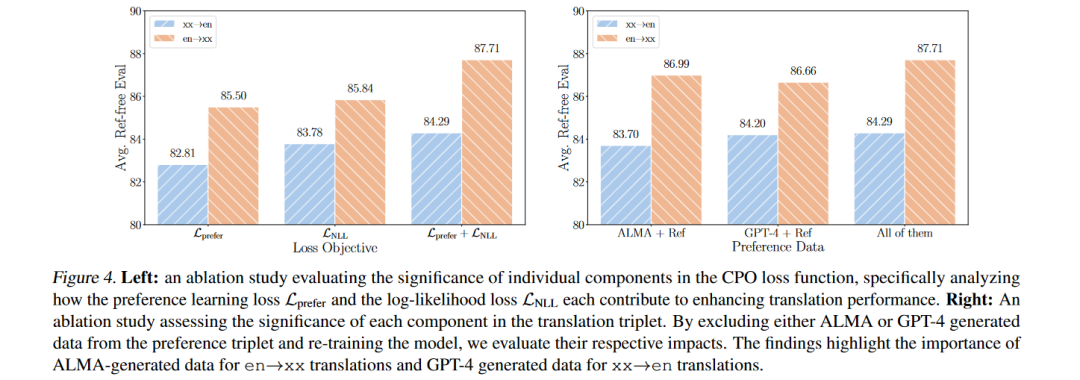
这些实验旨在验证CPO方法的有效性,并通过与现有技术的比较来展示ALMA-R模型的性能提升。
Q5: 有什么可以进一步探索的点?
A:论文提出了一些可以进一步探索的点,包括:
CPO在更大模型上的应用:虽然论文主要关注了中等规模的LLMs,但CPO方法也显著提升了7B模型的性能。可以进一步研究CPO在更大模型上的效果,例如数十亿参数的模型。
CPO在其他NLP任务的应用:CPO方法在机器翻译任务上取得了成功,可以考虑将其应用于其他自然语言处理任务,如文本摘要、问答系统、对话系统等。
CPO与其他训练技术的结合:可以探索CPO与其他训练技术(如指令调优、多任务学习等)结合使用,以进一步提升模型性能。
CPO的可扩展性和效率:研究CPO方法在大规模数据集和计算资源上的可扩展性和效率,以及如何优化CPO以减少训练时间和资源消耗。
CPO的泛化能力:评估CPO方法在不同语言对和领域上的泛化能力,以及是否需要针对特定任务或领域进行调整。
CPO的解释性:研究CPO训练过程中模型学习到的偏好,以及如何解释模型的决策过程,这对于理解模型行为和提高用户信任至关重要。
CPO与人类评估的比较:虽然CPO依赖于参考免费模型进行评估,但可以进一步研究CPO生成的翻译与人类评估者偏好之间的一致性。
CPO的长期记忆和一致性:研究CPO训练是否能够提高模型在长期记忆和一致性方面的表现,这对于机器翻译尤其重要。
CPO的鲁棒性和安全性:探索CPO是否能够提高模型对错误输入的鲁棒性,以及是否能够防止模型生成有害或误导性的翻译。
CPO的多语言能力:研究CPO是否能够提高模型在多语言翻译任务上的性能,特别是在低资源语言对上。
这些方向为未来的研究提供了丰富的探索空间,有助于进一步理解CPO方法的潜力和局限性。
Q6: 总结一下论文的主要内容?
A:这篇论文的主要内容包括:
问题提出:中等规模的大型语言模型(LLMs)在机器翻译(MT)任务上的性能与最先进的传统编码器-解码器翻译模型或更大规模的LLMs(如GPT-4)相比仍有差距。
分析参考数据质量:对FLORES-200数据集的参考翻译进行了深入分析,发现即使是人类编写的参考翻译也可能存在质量问题。
引入对比偏好优化(CPO):提出了CPO,一种新的训练方法,旨在训练模型避免生成虽然足够但并不完美的翻译。
CPO方法的实现:详细描述了CPO的实现过程,包括目标函数的推导、偏好数据的构建以及训练过程中的优化。
实验设置:在ALMA-13B-LoRA模型上应用CPO,并使用22K平行句子和12M参数进行微调。
性能评估:在WMT'21、WMT'22和WMT'23测试数据集上评估了应用CPO后的ALMA-R模型,结果显示其性能可以匹配或超过GPT-4和WMT竞赛获胜者。
分析:进行了多项分析,包括CPO损失函数各部分的贡献、人类标记的偏好数据的影响、翻译质量是否真的优于参考数据或仅仅是指标偏好等。
结论:CPO方法显著提升了中等规模LLMs在机器翻译任务上的性能,缩小了它们与最先进翻译系统之间的差距。
这篇论文通过提出和验证CPO方法,为中等规模LLMs在机器翻译任务上的性能提升提供了新的视角和解决方案。
以上内容均由KimiChat生成,深入了解论文内容仍需精读论文
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦















 359
359











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









