






深度学习自然语言处理 分享
整理:pp
 摘要:Instruction tuning 可有效优化大型语言模型(LLM),使其适用于下游任务。由于实际应用中的环境不断变化,LLMs 需要在不发生灾难性遗忘的情况下,针对特定任务进行持续适应。考虑到沉重的计算成本,基于重放的持续学习(CL)方法是解决遗忘问题的最简单、最广泛的 LLM 方法。然而,传统的基于重放的方法不能充分利用指令来定制重放策略。在这项工作中,我们提出了一种名为基于指令的持续学习(InsCL)的新模式。InsCL 基于任务相似性动态重放之前的数据,任务相似性由带有指令的 Wasserstein Distance 计算得出。此外,我们还进一步引入了指令信息度量(InsInfo)来量化指令的复杂性和多样性。根据 InsInfo,InsCL 引导重放过程更倾向于高质量数据。我们在 16 个任务中以不同的训练顺序进行了大量实验,观察到 InsCL 在性能上的持续改进。当所有任务都训练完毕后,InsCL 与随机重放相比实现了 3.0 的相对性能增益,与无重放相比实现了 27.96 的相对性能增益。
摘要:Instruction tuning 可有效优化大型语言模型(LLM),使其适用于下游任务。由于实际应用中的环境不断变化,LLMs 需要在不发生灾难性遗忘的情况下,针对特定任务进行持续适应。考虑到沉重的计算成本,基于重放的持续学习(CL)方法是解决遗忘问题的最简单、最广泛的 LLM 方法。然而,传统的基于重放的方法不能充分利用指令来定制重放策略。在这项工作中,我们提出了一种名为基于指令的持续学习(InsCL)的新模式。InsCL 基于任务相似性动态重放之前的数据,任务相似性由带有指令的 Wasserstein Distance 计算得出。此外,我们还进一步引入了指令信息度量(InsInfo)来量化指令的复杂性和多样性。根据 InsInfo,InsCL 引导重放过程更倾向于高质量数据。我们在 16 个任务中以不同的训练顺序进行了大量实验,观察到 InsCL 在性能上的持续改进。当所有任务都训练完毕后,InsCL 与随机重放相比实现了 3.0 的相对性能增益,与无重放相比实现了 27.96 的相对性能增益。
https://arxiv.org/abs/2403.11435
Q1: 这篇论文试图解决什么问题?
 A:这篇论文提出了一种名为InsCL(Instruction-based Continual Learning)的新范式,旨在解决大型语言模型(LLMs)在持续学习(Continual Learning, CL)任务中的灾难性遗忘问题。具体来说,它针对以下几个问题:
A:这篇论文提出了一种名为InsCL(Instruction-based Continual Learning)的新范式,旨在解决大型语言模型(LLMs)在持续学习(Continual Learning, CL)任务中的灾难性遗忘问题。具体来说,它针对以下几个问题:
灾难性遗忘:在现实应用中,由于新数据和知识的不断涌现,LLMs需要不断地适应新任务,同时保留对旧任务的知识,避免在学习新任务时遗忘之前学到的知识。
数据效率:传统的基于重放(replay)的持续学习方法虽然能够缓解遗忘问题,但它们通常需要大量的计算资源。InsCL旨在提高数据使用效率,减少计算成本。
指令的利用:指令(instructions)是高质量任务描述的来源,但传统方法并没有充分利用指令来定制重放策略。InsCL通过动态重放策略和指令信息度量(InsInfo)来充分利用指令信息,以提高重放数据的质量。
任务相似性:InsCL通过计算任务间的Wasserstein距离来动态调整重放策略,使得模型能够根据任务的相似性来选择性地回忆相关知识。
复杂性和多样性:InsCL引入了InsInfo来量化指令的复杂性和多样性,并通过InsInfo引导的采样过程来选择高质量的重放数据,从而提高模型在旧任务上的性能。
总的来说,InsCL旨在通过更智能地利用指令信息和任务相似性来提高LLMs在连续学习任务中的性能,同时减少计算资源的消耗。
Q2: 有哪些相关研究?
A:这篇论文提到了几类相关的研究工作,主要包括:
指令调优(Instruction Tuning):近年来,大型语言模型(LLMs)在自然语言处理(NLP)任务中展现出了卓越的性能。指令调优是一种有效的方法,通过给定的输入指令来生成适当的输出,从而进一步提升LLMs的性能。相关研究包括如何使用{指令, 输入, 输出}对来对LLMs进行监督微调。
传统持续学习方法(Traditional CL Methods):持续学习旨在学习一系列任务而不遗忘之前学到的知识。传统方法包括基于巩固的方法(如EWC)、基于架构的方法(如为每个任务添加特定参数)和基于重放的方法(存储并重放先前任务的训练示例)。
LLMs的指令调优的持续学习(CL for LLMs instruction tuning):随着LLMs规模的增加,它们在指令调优方面展现出了更好的适应性。相关研究探讨了如何在有限的训练资源下,通过参数高效的调优方法来缓解遗忘问题,并且在全微调场景下初步研究了基于重放的方法。
具体地,论文中提到的相关工作包括但不限于以下论文和研究:
Brown et al., 2020; Ouyang et al., 2022; Touvron et al., 2023(LLMs在NLP任务中的能力)
Wei et al., 2021; Peng et al., 2023; Shi et al., 2023(指令调优方法)
Sanh et al., 2021; Mishra et al., 2021; Chung et al., 2022(LLMs的指令调优)
Kirkpatrick et al., 2017; Zhang et al., 2020; Monaikul et al., 2021; Liu et al., 2021; Qin and Joty, 2021(基于巩固的方法)
Rusu et al., 2016; Gu et al., 2020; Madotto et al., 2020(基于架构的方法)
Sun et al., 2019; Zhang et al., 2022; Mi et al., 2020; Qin et al., 2022(基于重放的方法)
Scialom et al., 2022; Song et al., 2023; Wang et al., 2023; Yin et al., 2023(LLMs的指令调优的CL方法)
这些相关工作为InsCL的提出提供了理论和技术背景,并帮助定义了该研究领域的当前状态和挑战。InsCL通过结合这些相关研究的洞见,提出了一种新的方法来提高LLMs在连续学习任务中的性能和数据效率。
Q3: 论文如何解决这个问题?


A:论文提出了一种名为InsCL(Instruction-based Continual Learning)的方法来解决上述问题。InsCL的核心思想是充分利用指令(instructions)作为任务描述的信息,来动态调整持续学习过程中的数据重放策略。具体来说,InsCL包含以下几个关键组件:
动态重放(Dynamic Replay):InsCL根据任务间的相似性动态决定重放数据的比例。它使用Wasserstein距离来衡量任务之间的相似性,这个距离通过比较指令的分布来计算。对于与当前任务差异较大的任务,InsCL会重放更多的数据。
指令信息度量(Instruction Information Metric, InsInfo):InsCL引入了InsInfo来量化指令的复杂性和多样性。InsInfo基于指令中标签的频率和分布来计算,从而评估指令的信息量。高InsInfo意味着指令包含更丰富的信息。
InsInfo引导的采样(InsInfo-guided Sampling):在确定了基于任务相似性的重放比例后,InsCL使用InsInfo来引导数据采样过程,选择高质量的重放数据。这个过程倾向于选择那些具有高InsInfo的指令对应的数据。
实验验证:论文通过在16个不同任务上的广泛实验来验证InsCL的有效性。实验结果表明,InsCL在不同训练顺序下都能一致地提高模型在旧任务上的性能,并显著减少了灾难性遗忘。
总结来说,InsCL通过结合任务相似性计算和指令信息度量,设计了一种数据高效的重放策略,旨在提高LLMs在连续学习任务中的性能,同时减少因重放带来的计算成本。论文的实验结果证明了InsCL在减少遗忘和提高模型稳定性方面的优势。
Q4: 论文做了哪些实验?
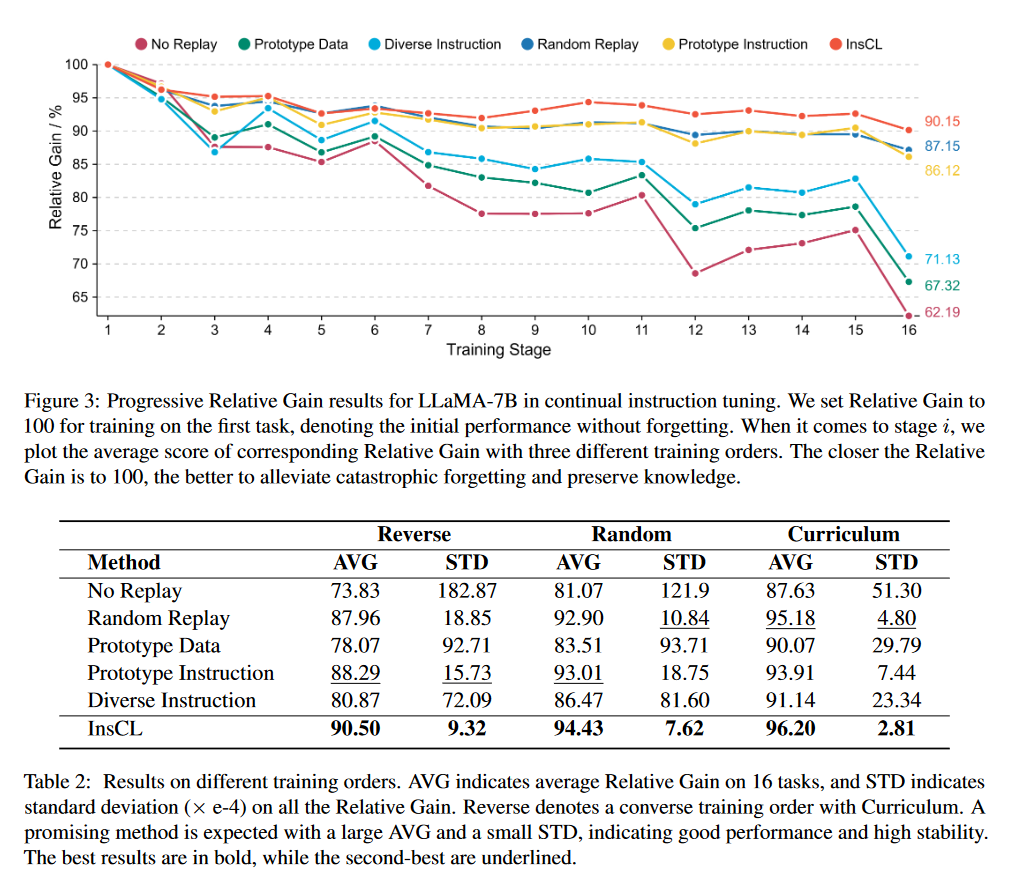
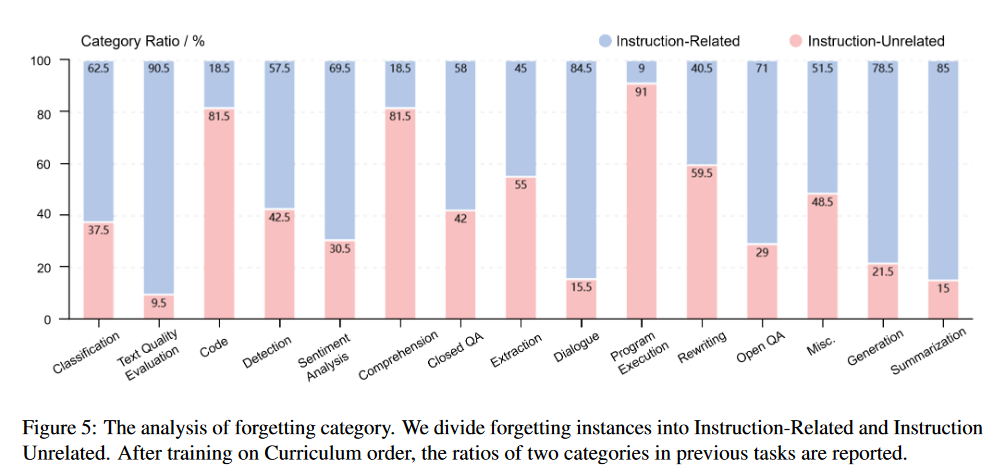
A:论文中进行了一系列实验来验证InsCL(Instruction-based Continual Learning)方法的有效性。以下是实验的主要内容:
实验设置:
数据收集:使用SuperNI数据集,整合了765个英文任务分为16个类别。
模型和训练细节:使用LLaMA-7B模型进行实验,每个任务训练2个epoch,批量大小为64。
评估指标:使用相对增益(Relative Gain)来衡量模型在不同训练阶段的性能,并使用Rouge-L来计算每个任务的相对增益。
基线方法:
No Replay:不使用任何重放数据进行增量训练。
Random Replay:从每个先前任务中随机采样数据作为重放数据。
Prototype Data:基于数据嵌入空间聚类选择代表性数据。
Prototype Instruction:基于指令聚类选择代表性指令。
Diverse Instruction:重放与当前任务指令最不同的数据。
主要实验结果:
对于LLaMA-7B模型,在16个任务上进行连续训练,InsCL在减少灾难性遗忘方面表现出色,与Random Replay相比有3.0的相对增益,与No Replay相比有27.96的相对增益。
训练顺序分析:
分析了不同训练顺序对模型性能的影响,包括从简单到困难的任务顺序(Curriculum)。
在Curriculum训练顺序下,InsCL在所有CL方法中表现最佳,具有最高的平均相对增益和最低的标准差。
消融研究(Ablation Study):
分别评估了动态重放和InsInfo引导的采样这两个InsCL组件的有效性。
结果表明,两个组件都有助于减少灾难性遗忘,而InsCL结合这两个组件时达到了最佳性能。
遗忘分析(Forgetting Analysis):
定义了遗忘率(Forgetting Rate)来量化训练过程中性能下降的程度。
对于No Replay设置,复杂推理任务(如Program Execution和Code)的遗忘率较高。
使用InsCL时,几乎所有任务的遗忘率都低于20%,表明大部分先前知识得以保留。
遗忘类别分析(Forgetting Category Annotation):
将遗忘实例分为“与指令相关”和“与指令无关”两类,并分析了不同任务的遗忘类别比例。
发现大多数任务的遗忘实例主要是与指令相关的,而对于复杂推理任务,与指令无关的遗忘实例占主导。
这些实验全面地展示了InsCL在不同设置和不同任务上的性能,并与多种基线方法进行了比较,证明了InsCL在减少灾难性遗忘和提高模型稳定性方面的优势。
Q5: 有什么可以进一步探索的点?
A:尽管InsCL在减少灾难性遗忘和提高持续学习性能方面取得了显著成果,但仍有一些潜在的研究方向可以进一步探索:
更复杂的任务相似性度量:虽然Wasserstein距离在衡量任务相似性方面表现良好,但探索其他距离度量或相似性度量方法可能会提供更精细的重放策略。
多模态学习:目前的InsCL主要针对文本任务。将该方法扩展到多模态任务(如图像和文本的组合)可能会带来新的挑战和机遇。
长期持续学习:研究InsCL在长期持续学习场景下的表现,即在更长的时间跨度和更多的任务上进行学习。
遗忘机制的深入理解:进一步研究LLMs在持续学习过程中遗忘的底层机制,以便设计出更有效的抗遗忘策略。
指令质量的影响:研究指令的质量如何影响InsCL的性能,以及如何自动化地提高指令质量以优化模型表现。
跨领域适应性:探索InsCL在不同领域间的迁移学习能力,以及如何设计策略来处理领域间的知识和遗忘差异。
实时数据流:研究InsCL在处理实时数据流时的表现,以及如何有效地从动态到来的数据中学习和适应。
模型压缩和效率:探索如何将InsCL与模型压缩技术结合,以减少存储需求并提高在资源受限环境下的效率。
可解释性和透明度:提高InsCL的可解释性,使研究人员和用户能够更好地理解和信任模型的决策过程。
实际部署和应用:将InsCL应用于实际问题,并评估其在真实世界场景中的性能和实用性。
这些潜在的研究方向可以帮助学术界和工业界更好地理解和应用持续学习技术,特别是在大型语言模型的背景下。
Q6: 总结一下论文的主要内容?
A:这篇论文的主要内容可以总结如下:
标题: InsCL: A Data-efficient Continual Learning Paradigm for Fine-tuning Large Language Models with Instructions
背景: 大型语言模型(LLMs)在下游任务中表现出色,但在现实世界的应用中,它们需要不断地适应新任务,同时避免灾难性遗忘。传统的重放方法在计算资源上代价昂贵,且没有充分利用指令信息来定制重放策略。
主要贡献:
提出了一种新的持续学习范式InsCL,专门针对带有自然语言指令的LLMs的微调。
InsCL通过计算任务间基于Wasserstein Distance的相似性来动态重放数据。
引入了指令信息度量(InsInfo)来量化指令的复杂性和多样性,并指导重放数据的采样过程。
在16个不同任务上进行了广泛的实验,证明了InsCL在减少灾难性遗忘和提高模型性能方面的有效性。
方法:
动态重放策略:根据任务间的相似性动态调整重放数据量。
InsInfo度量:使用GPT-4进行指令的细粒度标注,并通过数量和频率的标签来量化指令信息。
InsInfo引导的采样:根据InsInfo选择高质量的重放数据。
实验:
使用SuperNI数据集进行实验,该数据集包含多种NLP任务。
与不重放、随机重放以及其他基线方法进行比较。
分析了不同训练顺序对性能的影响。
进行了消融研究以验证各个组件的有效性。
探讨了遗忘率和遗忘类别,以深入了解遗忘现象。
结果:
InsCL在所有任务上实现了一致的性能提升。
与随机重放相比,InsCL在所有任务上平均获得了3.0的相对增益。
与不重放相比,InsCL平均获得了27.96的相对增益。
结论:
InsCL是一个有效的数据高效方法,可以减少LLMs在指令调优中的灾难性遗忘。
InsCL的方法是模型无关的,表明了其强大的可转移性。
InsCL的设计充分利用了指令作为任务描述,通过动态调整重放比例和选择高质量数据来提高持续学习的性能。
限制: InsCL的性能依赖于高质量的指令。如果指令模糊不清,可能会影响任务相似性的计算和InsInfo引导的采样,从而误导InsCL。
致谢: 论文的工作得到了深圳科技创新委员会的资助。
以上内容均由KimiChat生成,深入了解论文内容仍需精读论文
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦














 859
859











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









