







论文:Interactive Evolution: A Neural-Symbolic Self-Training Framework For Large Language Models
地址:https://arxiv.org/abs/2406.11736
项目:https://github.com/xufangzhi/ENVISIONS
这篇论文试图解决什么问题?
这篇论文提出了一个名为ENVISIONS的环境引导的神经符号自训练框架,旨在解决以下两个问题:
符号数据的稀缺性:在神经符号场景中,与丰富的自然语言(NL)标注数据相比,获取符号标注数据(例如,用于复杂规划、数学推理、机器人学和代理任务的符号表示)更加困难和昂贵。
大型语言模型(LLMs)处理符号语言的能力有限:当前的自训练方法在自然语言场景中取得了成功,但在神经符号场景中,LLMs在处理符号语言方面的能力还有待提高。
为了解决这些问题,ENVISIONS框架通过与环境的交互来进行迭代训练,以增强LLMs处理符号语言的能力,并减少对人类标注数据的需求。通过广泛的评估,论文证明了该方法在不同领域(包括Web代理、数学推理和逻辑推理)的有效性,并通过深入分析揭示了ENVISIONS成功的贡献因素,为未来在这一领域的研究提供了有价值的见解。
论文如何解决这个问题?
论文通过提出ENVISIONS框架来解决上述问题,具体方法包括以下几个关键步骤:
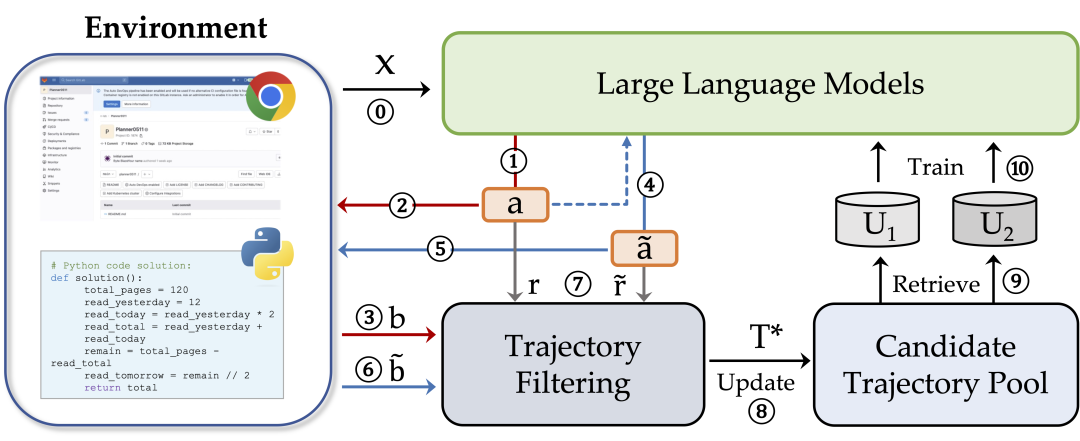
环境引导的自训练(Env-guided Self-Training): ENVISIONS框架采用环境引导的自训练方法,通过与环境的交互来迭代训练LLMs。这种方法不依赖于现有的更强大的LLMs或人类标注的符号数据。
在线探索(Online Exploration): LLMs自主地与环境交互,生成候选的符号解决方案,并通过执行这些方案来获得反馈。这个过程包括自我探索、自我提炼和自我奖励三个阶段。
自我探索(Self-Exploration):给定自然语言输入,LLM生成多种符号输出,并在环境中执行这些输出以获得基于期望输出的二进制反馈。
自我提炼(Self-Refinement):使用自我探索得到的解决方案作为参考,LLM重新生成经过提炼的符号解决方案,以提高解决方案的质量。
自我奖励(Self-Rewarding):根据LLM生成的符号解决方案的序列输出概率计算软奖励分数,以此来区分不同正解之间的偏好或从负解中获得有价值的反馈。
数据选择和训练策略(Data Selection and Training Strategies): 通过在线探索阶段生成的候选轨迹,ENVISIONS选择优质轨迹进行LLM的训练。这包括轨迹过滤、候选池更新、监督式微调以及从错误中学习。
对比损失函数(Contrastive Loss Function): ENVISIONS设计了一个无需强化学习的损失函数,通过对比正负解决方案来优化模型,这样做提高了训练效率并保持了自我提炼的能力。
通过这些方法,ENVISIONS框架能够在不需要昂贵的人类标注数据和现有强大模型的情况下,有效地提升LLMs处理符号语言的能力,并在多个领域展现出卓越的性能。
论文做了哪些实验?
论文中进行了广泛的实验来评估ENVISIONS框架的有效性,实验涉及三个不同的领域:Web代理、数学推理和逻辑推理。以下是具体的实验细节:
数据集: 选择了三个领域内的多个数据集进行评估:
Web代理:使用了MiniWob++数据集,这是一个广泛使用的Web导航基准测试。
数学推理:包括了GSM8K、MATH、GSM-Hard、SVAMP和AsDiv等任务。
逻辑推理:使用了ProofWriter和RuleTaker数据集来评估逻辑推理性能。

基线和训练细节: 考虑了三种不同的基线方法,包括Distill-then-Finetune、Reinforced Self-Training和Env-guided Self-Training,并在相同的代码库下复现这些基线以确保公平比较。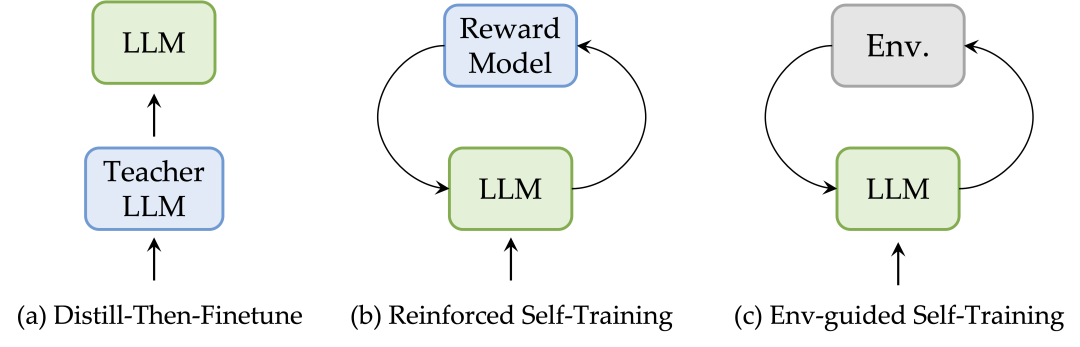
训练配置: 使用了LLaMA2-Chat 7B/13B模型进行评估,并设置了不同的候选解决方案数量K(5个),迭代次数(对于Web代理、数学和逻辑任务分别设置为5、10和8次迭代)。
主要结果: 展示了ENVISIONS与其他基线方法相比的性能提升,包括与Distill-then-Finetune方法相比5.66%-7.13%的改进,以及与Reinforced Self-Training和其他Env-guided Self-Training方法相比2.78%-14.47%的平均增益。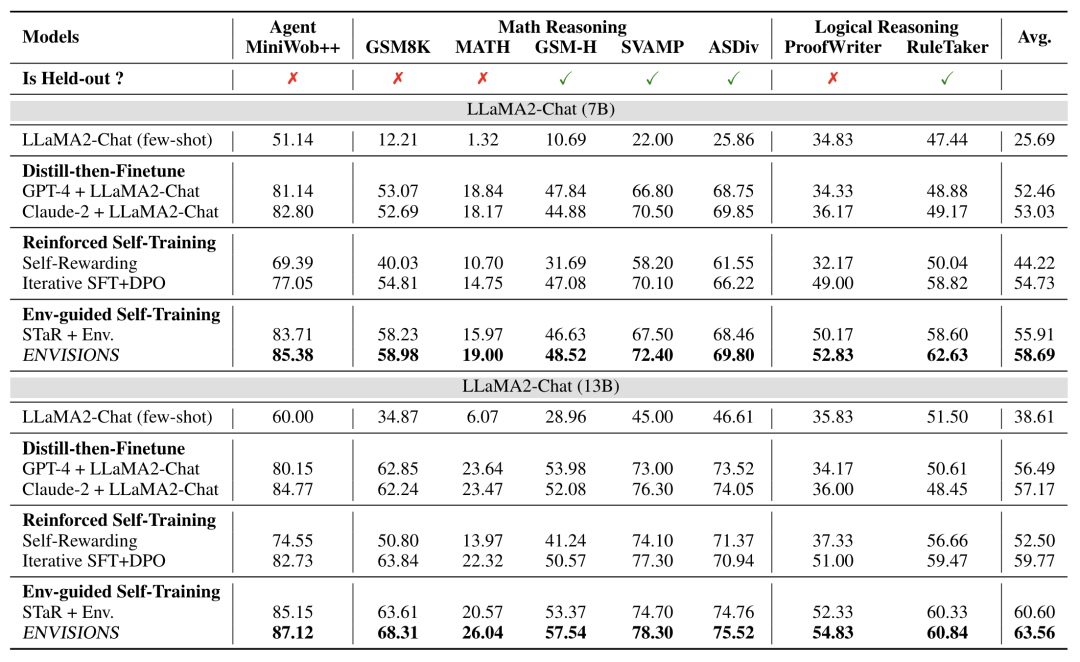
自我训练框架的迭代演变: 通过迭代演变曲线展示了ENVISIONS和其他自训练方法的性能进步,特别是在LLaMA2Chat 13B模型上。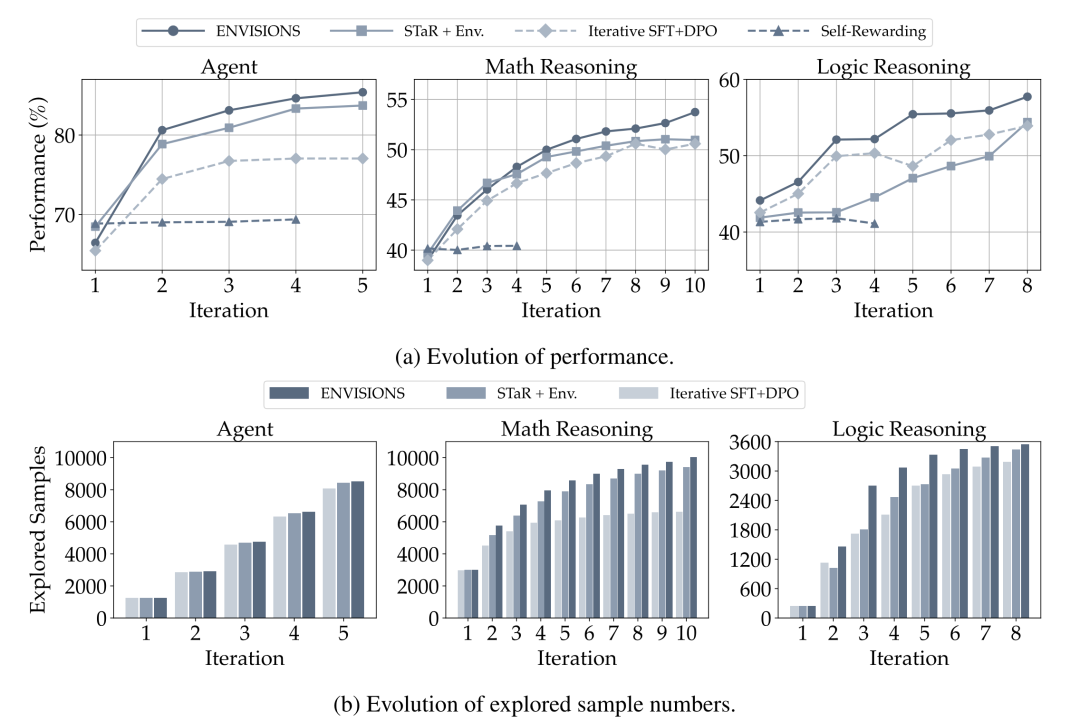
消融研究: 对ENVISIONS的关键组件进行了消融研究,以验证它们在提升性能中的作用,包括自我提炼过程、自我奖励策略、长期记忆的使用以及L2损失函数的优化。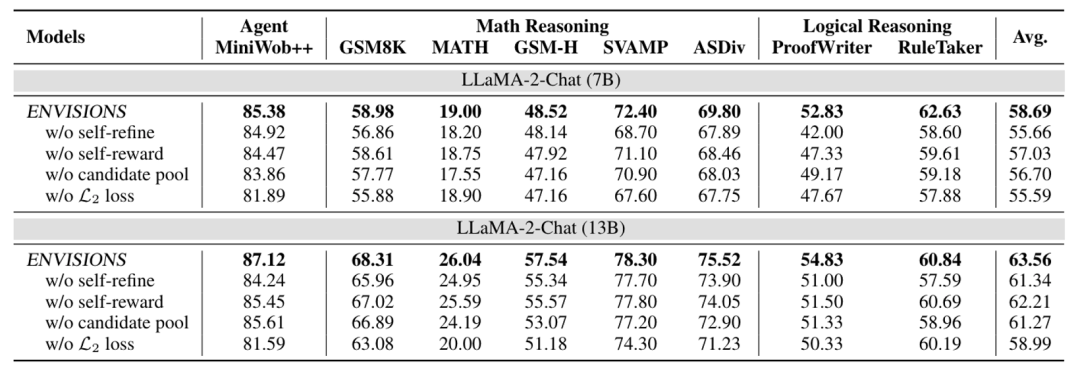
泛化到不同模型: 展示了ENVISIONS框架对其他大型语言模型(如DeepSeek-Chat和Llemma)在数学推理任务上的泛化能力。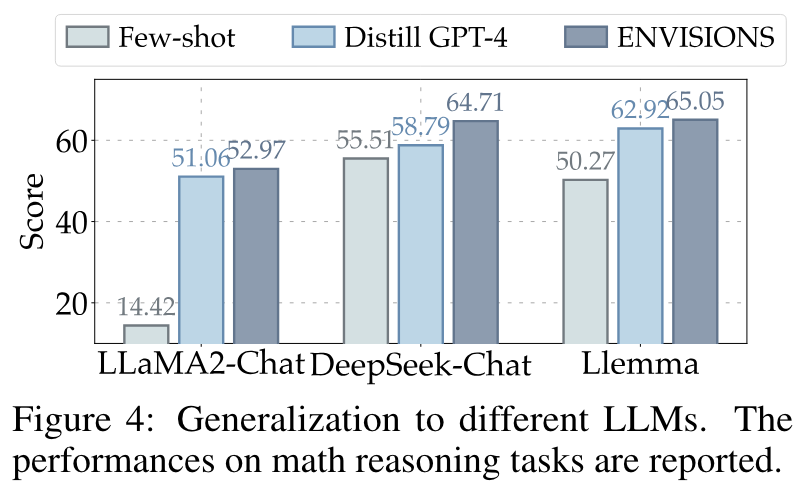
分析实验: 深入分析了ENVISIONS成功的原因,包括探索能力和稳定性的平衡、正负解之间的对数概率边界以及合成样本的多样性。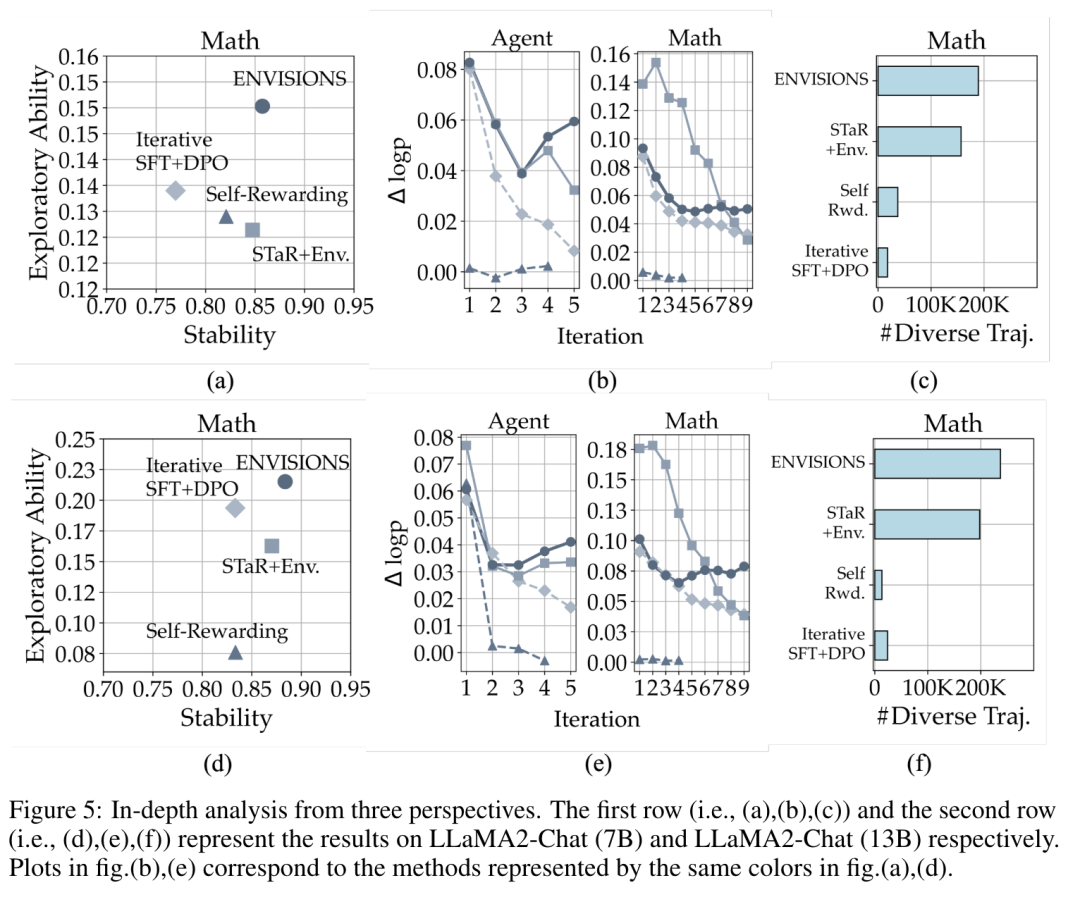
实验设置和统计显著性: 论文详细说明了所有训练和测试的细节,包括数据分割、超参数选择、优化器类型等,但没有报告误差条,因为计算成本过高。
计算资源: 提供了实验所需的计算资源信息,包括GPU类型和数量。
这些实验结果表明,ENVISIONS框架能够有效地提升LLMs在神经符号场景中的表现,并且具有很好的泛化能力和可扩展性。
论文主要内容总结
这篇论文的主要内容可以总结如下:
问题提出: 论文针对大型语言模型(LLMs)在神经符号场景下的应用,提出了两个主要挑战:符号数据的稀缺性和LLMs在处理符号语言上的局限性。
ENVISIONS框架: 为了解决上述问题,论文提出了一个名为ENVISIONS的环境引导神经符号自训练框架,该框架不依赖于人类标注的符号数据,也不需要现有的更强大的LLMs作为教师模型。
自训练方法: ENVISIONS框架采用迭代的自训练方法,包括自我探索、自我提炼和自我奖励三个阶段,以增强LLMs处理符号语言的能力。
实验评估: 论文在Web代理、数学推理和逻辑推理三个不同的领域进行了广泛的实验评估,验证了ENVISIONS框架的有效性。
性能提升: 实验结果显示,ENVISIONS在各个领域中均展现出了优越的性能,与现有的自训练方法相比有显著的性能提升。
消融研究: 通过消融研究,论文深入分析了ENVISIONS框架中关键组件的作用,包括自我提炼过程、自我奖励策略等。
泛化能力: 论文还探讨了ENVISIONS框架对不同LLMs的泛化能力,证明了其能够提升不同基础模型在数学推理任务上的性能。
深入分析: 论文从探索能力、稳定性、正负解之间的对数概率边界以及合成样本的多样性等角度,深入分析了ENVISIONS框架的优势。
未来工作: 论文讨论了ENVISIONS框架的局限性,并提出了未来研究的方向,如扩展到更广泛的领域、更大规模的模型、提高计算效率等。
社会影响: 论文讨论了该研究可能带来的社会影响,包括积极的和潜在的负面影响,并考虑了相应的缓解策略。
总的来说,这篇论文提出了一个创新的自训练框架ENVISIONS,旨在提高LLMs在神经符号场景下的性能,并通过一系列实验验证了其有效性,同时对未来的研究方向提供了指导。
本文由kimi+人工共同完成。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦















 629
629











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









