








论文题目:
Interactive Evolution: A Neural-Symbolic Self-Training Framework For Large Language Models
作者单位:
西安交通大学、上海AI Lab、香港大学、南京大学
论文地址:
https://arxiv.org/abs/2406.11736
项目地址:
https://github.com/xufangzhi/ENVISIONS

研究背景与核心问题
大语言模型(Large Language Model, LLM)在下游任务上的卓越性能,主要依靠大量人类标注的自然语言(Natural Language, NL)数据训练。为了摆脱对人类标注数据的强依赖,研究者们开始利用合成数据,进行模型的自训练(Self-Training),从而实现大模型能力从弱到强的转变(Weak-to-Strong)。
这些 LLM Self-Training 的最新研究主要集中在以自然语言为核心的场景中,即输入 x 和输出 y 都是 NL 的形式。然而,为了拓展 LLM 的应用范围和能力边界,需要神经-符号结合(Neural-Symbolic)的复杂应用场景受到越来越多的关注。
在这些 neural-symbolic 场景中(例如 agentic tasks),LLM 需要根据自然语言指令 x,生成可执行的符号化表示 a,并在环境中执行得到结果(或状态)y。相比于丰富的 NL 标注数据(x-y),收集符号化的数据对(x-a-y)是非常昂贵且有挑战性的,主要受限于符号语言(Symbolic Language,SL)的稀缺性和内生复杂性。
因此,我们研究的核心问题就是:如何在不依赖人类标注符号数据的情况下,实现 LLM 在神经-符号场景下的 Self-Training?

环境交互的Self-Training范式
当前,有两种常见的 Self-Training 范式,如下图(a)、(b)所示。
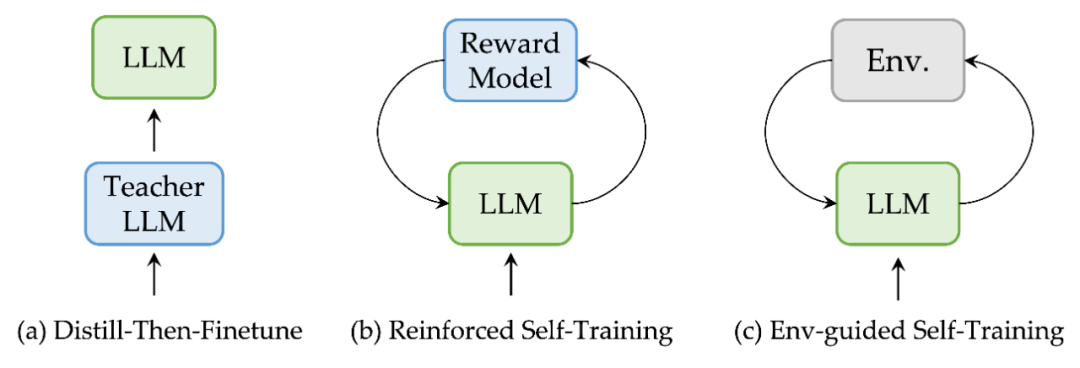
第一种是 Distill-then-Finetune。通过 Prompt Teacher LLM(如 GPT-4)获取数据对,用于 student LLM 的训练。该方法简单且有效,缺点是严重依赖于 Teacher LLM 且成本高。
第二种是 Reinforced Self-Training。利用 LLM 和 RL 的训练结合,来提升性能。但是,该范式的训练非常低效,且奖励模型的训练同样需要依赖人类标注。
针对 neural-symbolic 场景,我们提出 Env-guided Self-Training 范式(见图c)。仅仅依靠 LLM 自身与环境的不断交互,完成 weak-to-strong 的转化。优势在于:1)不引入人类标注和 Teacher LLM,能解决 SL 数据稀缺的挑战。2)通过自我合成数据实现自我进化,解决 LLM 在 neural-symbolic 场景上的能力短板。
上述三种范式不是正交的,理论上可以自由组合。

自训练框架ENVISIONS
基于 Env-guided Self-Training 范式,我们提出了一个全新的自训练框架 ENVISIONS:ENV-guIded Self-traIning framework fOr Neural Symbolic scenarios,如下图所示。
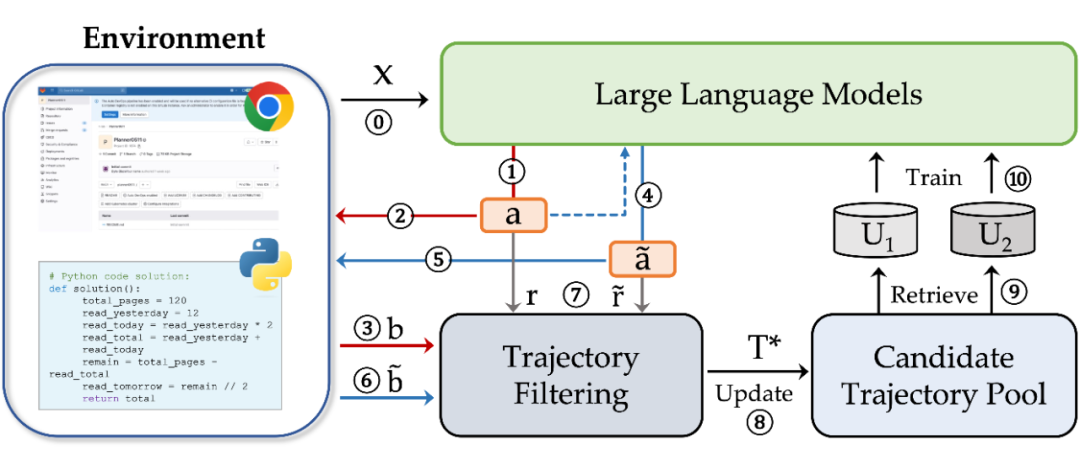
3.1 Preliminaries
对于每一个 iteration,我们可以拿到 pair,其中 是 NL 形式的任务指令, 是对应的答案或者 NL 描述的一种结果状态。
基本设定:基于 NL 的输入 ,LLM 需要生成符号化的输出 ,通过在环境 ENV 中的执行,得到确定性结果 。
3.2 Online Exploration
Online exploration 包含 Step1-7,LLM 不断地自主生成候选轨迹并与环境交互,构造高质量的正负训练样本。其中,Step1-3 为 Self-Exploration 阶段,Step4-6 为 Self-Refinement 阶段,Step7 为 Self-Rewarding 阶段。
3.2.1 Self-Exploration
Step 1:根据输入 ,生成 个候选 symbolic solutions 。即,;
Step 2:在环境 ENV 中执行每一个 ,得到反馈结果,即 ;
Step 3:根据环境的反馈与 作比较,得到二值化的奖励,即 。
3.2.2 Self-Refinement
由于 NL-centric 的 LLM 在符号语言生成上的天然劣势,根据 直接生成 是有挑战性的。考虑将 作为参考输入,进一步生成 。该步骤可以看作 Self-Refine 的过程。
在 Step4-Step6 中,我们进行与 Self-Exploration 阶段类似的操作。根据输入 和 ,合成 ,并通过与环境的交互,得到二值化的奖励 。
3.2.3 Self-Rewarding
根据 Step1-6,只能获得二值化的反馈。但无法区分更好的正样本或负样本。因此,使用生成输出过程中的 length-normalized logits,来作为 soft self-rewards,衡量样本之间的相对好坏。
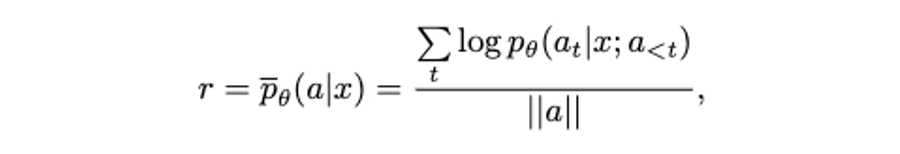
3.3 Data Selection and Training Strategies
前 7 个 step,收集到的轨迹可以表示为 和 。
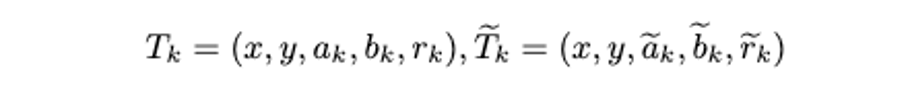
对轨迹进行过滤筛选,得到更优的轨迹 。使用 去更新 candidate trajectory pool。
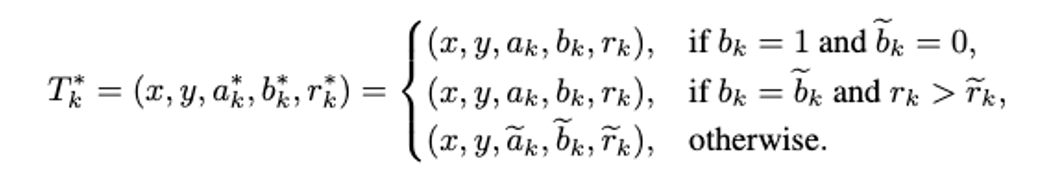
一种最直接 bootstrap LLM 的方式,就是利用正样本进行微调。为了得到更优的正样本进行进练,根据当前 trajectory pool 中每一个正样本的 self-rewards 值,进行重新降序排序,得到 ranked positive set .
对于第 个输入 ,取前 个正样本进行训练,形成集合 。
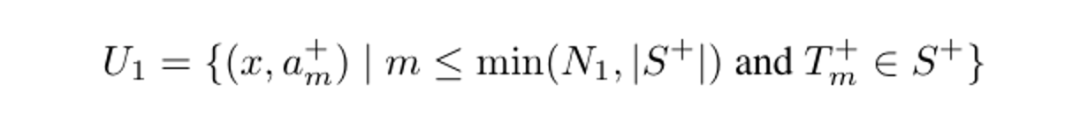
对应的就是一个 SFT 损失 ,根据 NL 输入 生成对应的 。
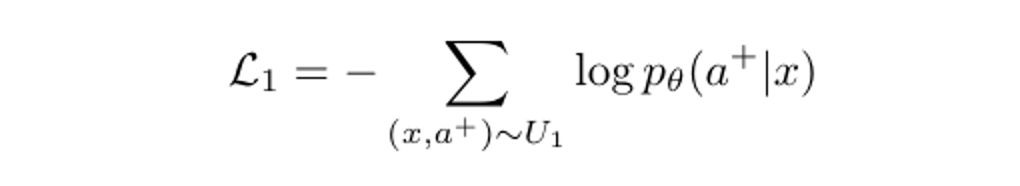
除了正样本之外,candidate trajectory pool 中的负样本也具有很大的利用价值。例如,LLM 可以在 weak-to-strong 中获取 learn from mistakes 的能力。与正样本 pool 相似,我们也可以得到 ranked negative set 。排位越前的负样本轨迹,对应的 self-rewards 值越高,说明是更难的负样本。
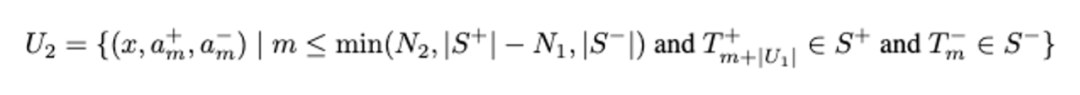
从 和 中,我们使用 self-rewards 更低的正样本,与 self-rewards 更高的负样本,去构造 N2 个正负样本对。形成包含 的集合 。考虑到 RL 方法在探索场景中的低效性,我们构造 RL-free 的 self-refine loss ,根据 和 去预测 。
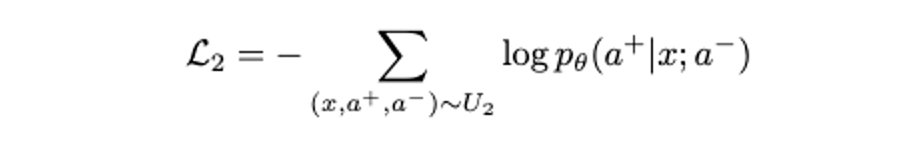
最终的训练损失就是 +,是一个纯 SFT 的 loss。

主要实验
4.1 实验设定
实验中选择 LLaMA2-Chat(7B/13B)作为基座大模型。在三个不同的领域任务上对自训练框架进行验证,分别是 Web Agent、Math Reasoning、Logic Reasoning。具体细节如下表所示。

对比的基线方法可以按照 self-training 的范式分为对应的三类。Distill-then-Finetune 中,分别采用 GPT-4 和 Claude-2 作为 Teacher LLM。Reinforced Self-Training 中,我们引入 Self-Rewarding、iterative SFT+DPO 作为强基线。Env-guided Self-Training 中,将 STaR 拓展到环境交互的场景,作为对比基线。
4.2 ENVISIONS在多类任务上展现了一致的优越性
从主表中可以看出,ENVISIONS 自训练框架在所有测试任务中,均超越了对比的基线方法。相较于次优的对比基线方法,也取得了接近 3% 的平均性能增益。同时,Env-guided Self-Training 范式在神经-符号场景下,展现了非常强的可拓展性。

4.3 ENVISIONS自训练框架兼备进化效率和可持续性
下图中呈现了 LLaMA2-Chat(7B)的进化过程,(a)图中为性能变化过程,(b)图中为探索到的成功样本的数量变化过程。
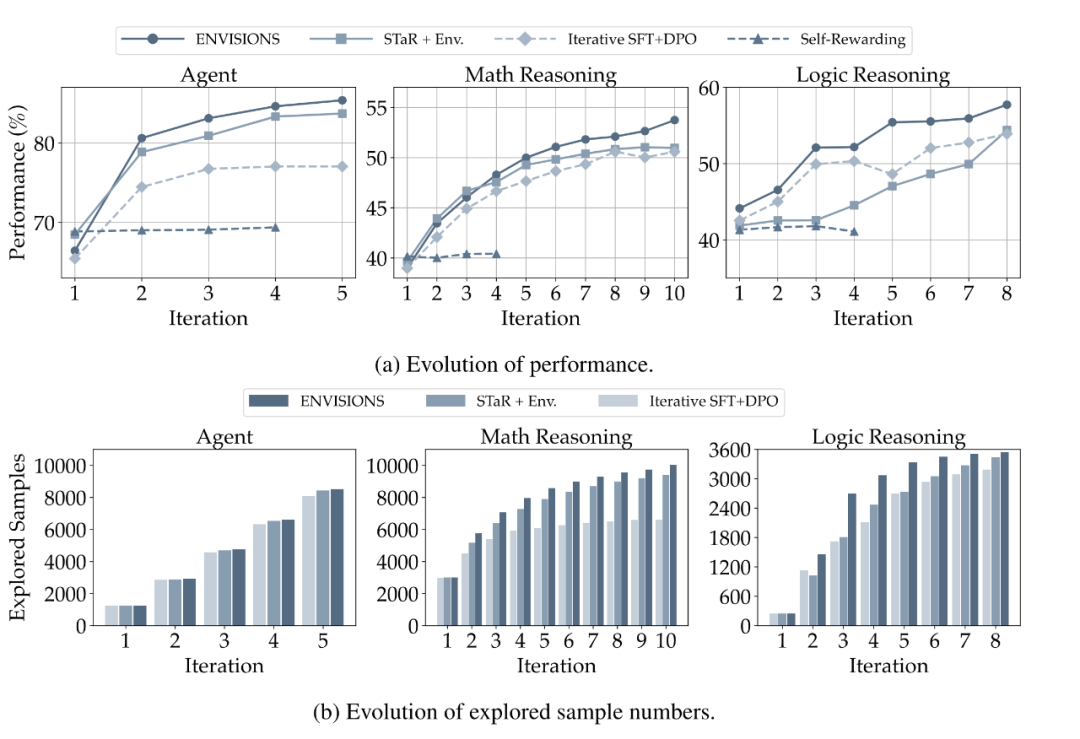
小结:(1)ENVISIONS 探索效率很高,且随着迭代轮次的增加,保持了稳定性。(2)RL 的基线方法在神经符号探索场景中表现的很挣扎。
4.4 在多个基座模型上的泛化能力
为了证明 ENVISIONS 在不同基座 LLM 上的泛化能力,下图展示了多个基座 LLM 在数学推理任务上的实验结果。
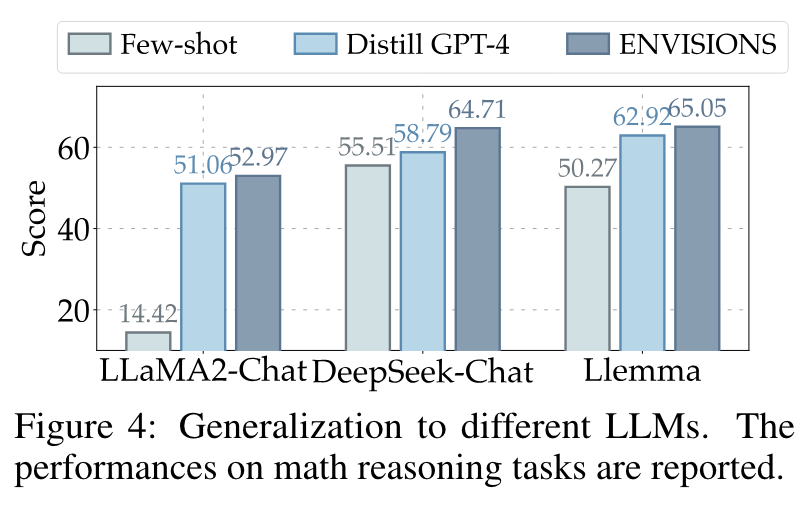
小结:ENVISIONS 不仅能训练 LLM 完成 weak-to-strong 的转变,也能 convert LLMs from strong to stronger。

分析实验
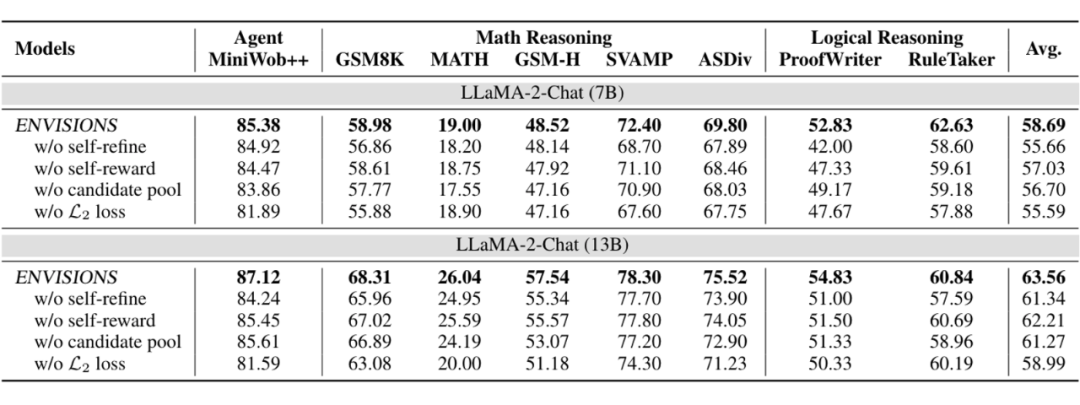
5.1 ENVISIONS 成功的关键模块是什么?
首先,本文进行了消融实验,验证了各个关键模块的有效性。如下图所示。
5.2 ENVISIONS 出色性能的深层原因分析
除此以外,本文进行了大量分析实验,来探索 ENVISIONS 优异性能的深层原因。
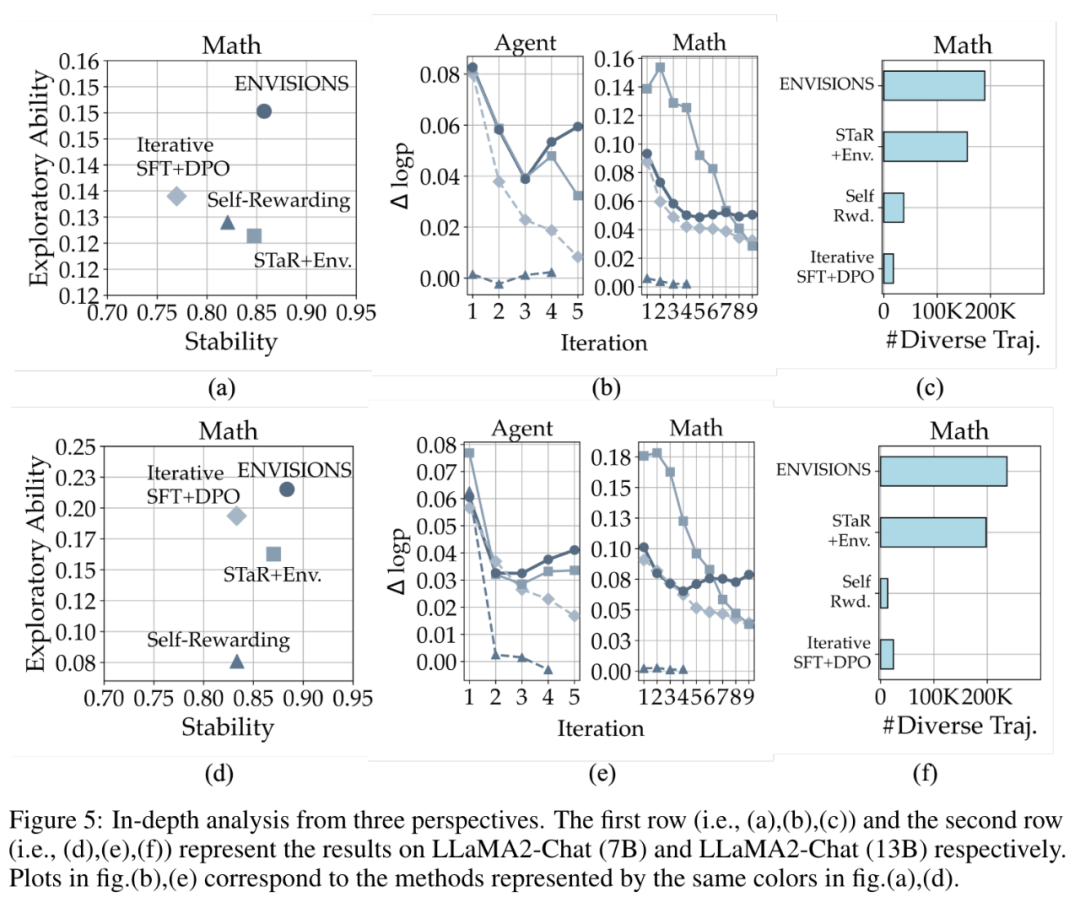
主要结论有三点:(1)平衡的探索效率和探索稳定性是 weak-to-strong 成功的关键。(2)清晰地区分正、负样本可以帮助 LLM 的优化。(3)生成轨迹的多样性对于 self-training 过程非常重要。

主要贡献总结
(1)方法贡献。本文针对神经符号场景,提出了基于环境交互的自训练框架ENVISIONS。无需人类标注、Teacher LLM,实现 LLM weak-to-strong 的转变。
(2)实验分析贡献。本文进行了全面的实验分析,验证了 ENVISIONS 的有效性,以及 Env-guided Self-Training 范式在神经符号场景下的优越性。大量针对 “why” questions 的分析,为后续研究提供了 insights。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·
















 32
32











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









