






论文:Can LLMs Generate Novel Research Ideas? A Large-Scale Human Study with 100+ NLP Researchers
地址:https://arxiv.org/abs/2409.04109

研究背景
研究问题:这篇文章探讨了大型语言模型(LLMs)在生成新颖研究想法方面的能力。具体来说,研究问题是 LLMs 是否能够生成与专家人类研究员相当的新颖想法。
研究难点:该问题的研究难点包括:评估 LLMs 生成的研究想法的创新性和可行性,招募和评估大量专家研究员,以及控制实验中的混杂变量。
相关工作:该问题的研究相关工作包括使用 LLMs 进行代码生成、自动评审生成、相关工作整理、实验结果预测和未来工作推荐等任务。然而,这些工作大多依赖于低成本的评估代理或快速的评估方法,而不是大规模的人类比较研究。
研究方法
这篇论文提出了一个实验设计,用于评估 LLMs 生成的研究想法的创新性,并与专家人类研究员的想法进行比较。具体来说,
LLM 生成想法:首先,构建了一个简单的 LLM 生成想法的代理,包括论文检索、想法生成和想法排序三个组件。
论文检索:使用检索增强生成(RAG)技术,通过查询语义学者 API 获取与给定研究主题相关的论文。
想法生成:提示 LLMs 生成多个候选想法,并使用去重和扩展技术生成最终的想法。
想法排序:使用公开评审数据训练一个 LLM 排名器,对生成的想法进行排序。
人类研究员生成和评审想法:招募了超过 100 名 NLP 研究员,让他们生成和评审想法。为了减少混杂变量的影响,标准化了想法的格式和风格,并匹配了主题分布。
盲评审:设计了详细的盲评审表,包括新颖性、兴奋度、可行性和预期有效性四个评分维度。评审者对每个想法进行评分,并提供自由文本反馈。
实验设计
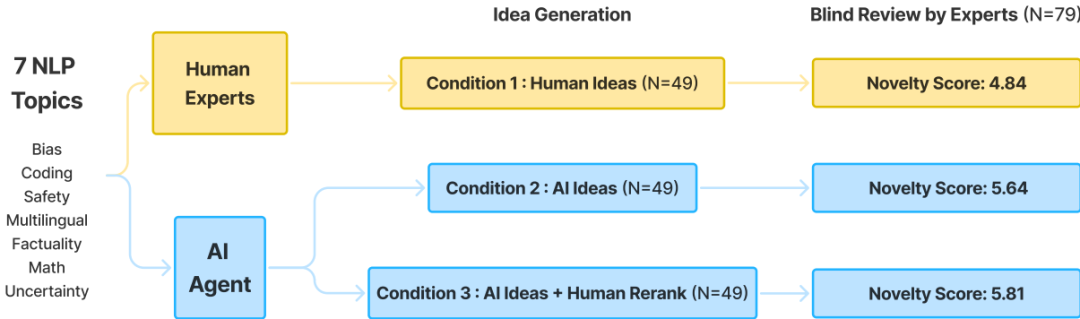
数据收集:招募了 49 名专家研究员生成想法,并收集了 298 条独特评审记录。
实验设计:实验包括三种条件:人类想法、AI 生成的想法和 AI 生成的想法经过人类重新排序。所有想法都遵循相同的主题描述和模板。
样本选择:从 71 个机构的 1426 名 NLP 研究员中招募了 49 名专家研究员生成想法,并从 32 个机构的 79 名研究员中招募了 79 名专家研究员进行评审。
参数配置:LLM 模型使用 Claude-3-5-sonnet-20240620,检索时每次生成最多 20 篇论文,总共生成 4000 个候选想法。
结果与分析
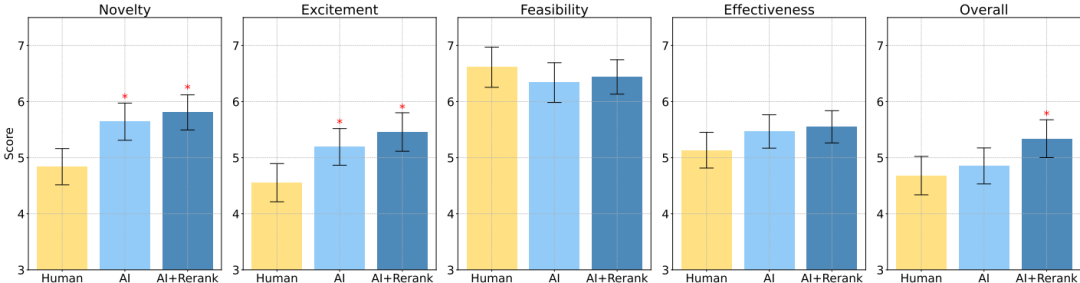
主要发现:在所有统计测试中,AI 生成的想法被认为比人类专家生成的想法更具新颖性(p<0.05),但在可行性方面略逊一筹。
定量分析:在三种不同的统计测试中,AI 生成的想法在新颖性得分上均显著高于人类想法,而在兴奋度和整体得分上也表现出相似的优势。
定性分析:评审者的自由文本反馈显示,AI 生成的想法在创新性方面得分较高,但在可行性和细节方面存在一些不足。
LLM 代理的局限性:尽管 AI 生成的想法在生成数量上具有优势,但在多样性方面表现不佳,且无法可靠地评估自己的想法。
总体结论
这篇论文通过大规模的人类比较研究,首次统计显著地证明了 LLMs 在生成新颖研究想法方面的潜力。尽管 AI 生成的想法在创新性方面表现出色,但在可行性和自我评估方面仍存在局限。未来的研究可以进一步探索如何提高 LLM 生成想法的多样性和可靠性,并评估这些想法在实际研究项目中的表现。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









