






链接:https://arxiv.org/html/2409.12136v1
论文:GRIN: GRadient-INformed MoE

研究背景
研究问题:这篇文章要解决的问题是如何有效地训练混合专家(MoE)模型,以克服稀疏计算对传统训练方法的挑战。MoE模型通过专家路由选择性地激活少量专家模块,从而实现比密集模型更有效的扩展。然而,离散的专家路由阻碍了标准的反向传播和基于梯度的优化。
研究难点:该问题的研究难点包括:离散专家路由导致不可微输出,无法直接应用反向传播进行梯度计算;MoE模型的稀疏激活机制使得标准的训练方法难以有效应用。
相关工作:该问题的研究相关工作有:Lepikhin等人(2021)、Fedus等人(2022)、Zoph等人(2022)提出的MoE模型,这些模型通过专家路由实现模型扩展,但在训练过程中面临梯度估计和稀疏计算的挑战。
研究方法
这篇论文提出了GRIN(Gradient-Informed MoE training)方法,用于解决MoE模型训练中的梯度估计和稀疏计算问题。具体来说,GRIN方法包括以下几个关键步骤:
稀疏梯度估计:提出SparseMixer-v2方法来估计专家路由的梯度。与传统的使用门控梯度作为路由梯度的代理不同,SparseMixer-v2通过随机采样离散变量和Heun's第三阶方法来近似专家路由梯度。
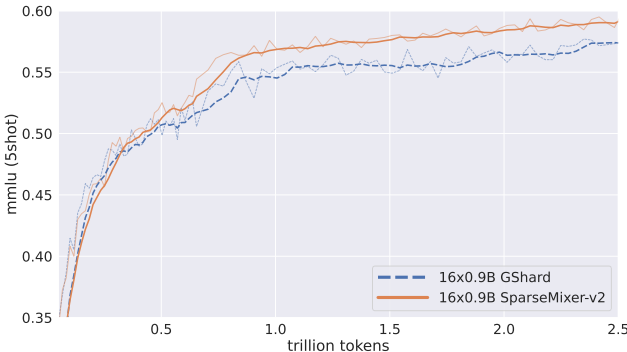
模型并行性配置:配置模型并行性以避免在训练过程中丢弃令牌。通过使用管道并行性和张量并行性,GRIN方法消除了对容量因子和令牌丢弃的需求。
MoE层的实现:在每个MoE层中,模型从前向网络中选择一个专家网络,该选择由路由网络决定。具体公式如下:
其中,,是路由参数,是门控函数(通常为softmax),是前馈网络。
实验设计
数据收集:GRIN MoE在4T令牌上进行预训练,使用与Phi-3密集模型相同的训练数据集。后训练阶段包括基于因果语言建模目标的有监督微调和直接偏好优化(DPO)。
实验设置:模型在24B令牌上进行SFT训练,使用高质量的多类别数据,如数学、编程和对话。DPO数据集包含1.4B令牌,用于对齐模型输出与微软的责任AI原则。
参数配置:GRIN MoE模型采用16x3.8B的配置,总共42B参数,其中6.6B为激活参数。
结果与分析
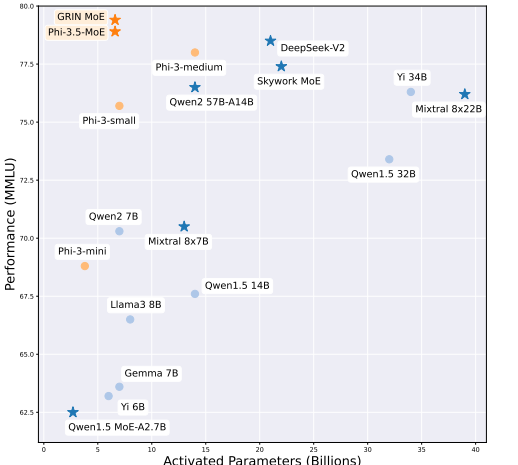
基准测试:GRIN MoE在多个基准测试中表现出色,特别是在编码和数学任务上。例如,在MMLU任务上得分为79.4,在HumanEval任务上得分为74.4,均优于7B密集模型,并与14B密集模型的表现相当。
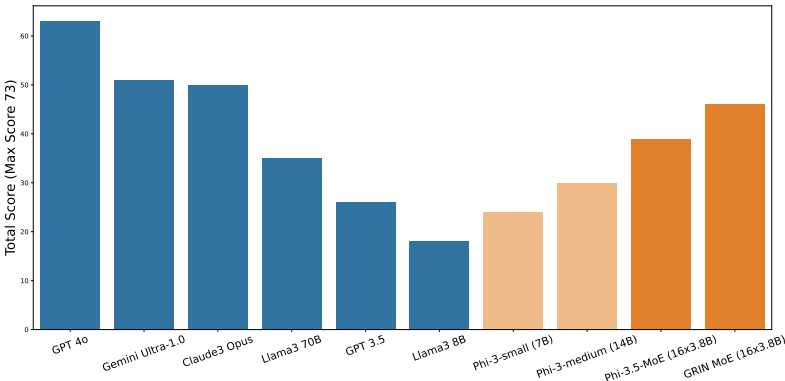
案例分析:在2024年中国高考数学题的案例分析中,GRIN MoE得分为46分(满分73分),优于Llama3 70B模型11分,且仅次于Gemini Ultra-1.0和Claude3 Opus。
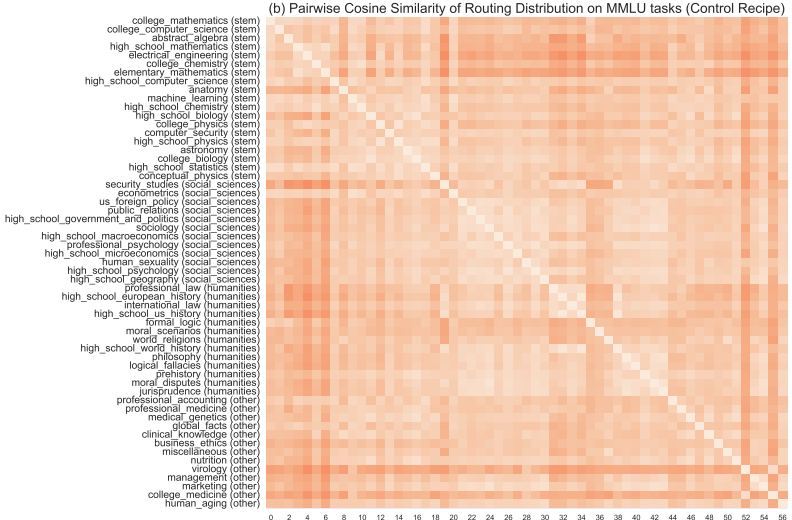
路由分布分析:通过分析不同任务的MoE路由分布,发现不同任务的路由分布存在显著差异。这表明GRIN MoE的专家在不同任务和领域中表现出不同的专长。
总体结论
这篇论文详细介绍了GRIN MoE模型及其训练技术,展示了MoE模型在扩展性方面的潜力。通过引入稀疏梯度估计和模型并行性配置,GRIN方法显著提高了MoE模型的训练效率和性能。未来的研究方向包括进一步探索MoE模型的训练和推理算法,以及解决softmax近似topk采样的新挑战。
本文由AI辅助人工完成。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









