







如今,大语言模型已经成为机器翻译任务(Machine Translation)上的新型强大工具。 然而,多数在机器翻译大语言模型(MT-LLM)上开展的研究工作都是句子层面的,每一句话都被独立进行翻译,从而忽视了在翻译文档翻译(Document-Level)场景下句子间可能存在的逻辑关系。
此外,大语言模型在推理框架中是一个独立、封闭的个体,仅能被动地接收外部输入的信息并进行处理,同时还具有上下文容量上的局限性,因此难以胜任诸如长文本处理、文档翻译之类的复杂任务。
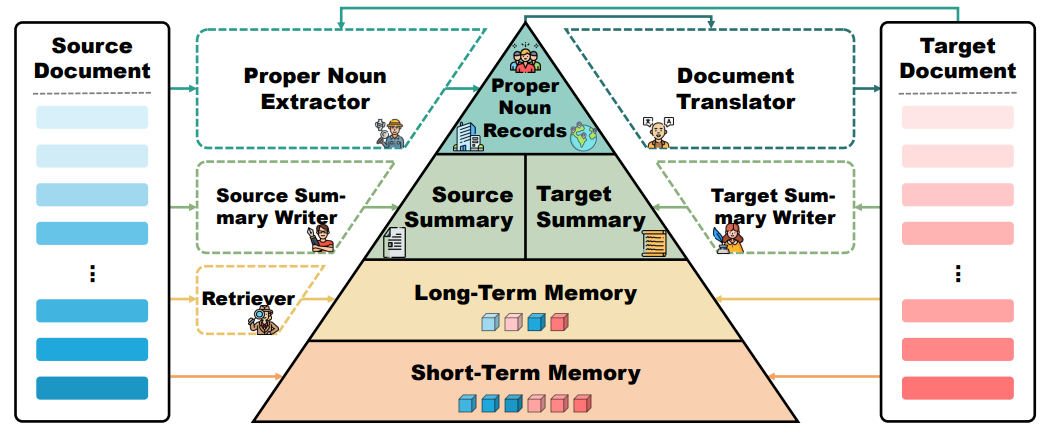
今天介绍的论文来自哈尔滨工业大学(深圳)计算与智能研究院和腾讯WeChat AI。 这篇论文提出了一种名为DelTA(Document-levEL Translation Agent)的基于多级记忆组件的文档翻译智能体。 DelTA通过使用专有名词记录、双语摘要和长短时记忆等多级记忆机制,对文档中不同范围、不同粒度及不同形式下的关键信息进行提取、存储和检索,以辅助翻译过程的进行。 这种创新架构不仅能够提升文档翻译的质量,还能够显著改善翻译结果的上下文一致性,以及避免大语言模型在翻译整篇文档时可能造成的句子漏译现象。
论文标题:DelTA: An Online Document-Level Translation Agent Based on Multi-Level Memory
论文地址:https://arxiv.org/abs/2410.08143
代码地址:https://github.com/YutongWang1216/DocMTAgent
动机
我们可以使用一种朴素的方法来利用大语言模型进行文档翻译,即利用大语言模型自身的上下文建模能力,一次性对文档中一个窗口内的多句话进行翻译。 随后窗口后移,再进行下一批句子的翻译。 窗口遍历完整篇文档后,将所有译句连接起来形成最终的译文文档。 然而,这样的方法会面临以下两个方面的挑战:
1. 翻译的一致性
在文档中,通常存在着许多包括人名、地名、术语在内的专有名词。 当源文档中的某个专有名词两次出现的位置不在同一个翻译窗口中时,大语言模型有可能会对其采取不同的翻译结果。 例如:上文中,大语言模型将“Natalia Rybczynski”这一人名翻译为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









