






来自:FudanNLP

我们提出了一个全面、细粒度的奖励模型评估基准,涵盖了超过 49 个现实世界场景,包含了超过三千条现实世界的用户问题。在pairwise 比较之外,我们还提出了 Best-of-N 的新基准评估范式。我们证明了我们的基准测试与奖励模型下游对齐任务表现之间的正相关性,并对目前SoTA 的奖励模型进行广泛分析。
📖 论文: https://arxiv.org/abs/2410.09893
🎮 数据&代码: https://github.com/Zhou-Zoey/RMB-Reward-Model-Benchmark
我们的评估代码和数据集可在 GitHub 上获取。
点击阅读原文直接访问论文链接
1
特点总结(省流)
奖励模型引导大规模语言模型的对齐过程,使其朝着人类偏好的行为方向发展。评估奖励模型是更好对齐 LLMs 的关键。
然而,由于评估数据往往分布有限,以及当前评估奖励模型的方法与对齐目标之间并不对应,当前对奖励模型的评估可能无法直接反映其对齐性能。
为了解决上述局限性,我们提出了 RMB(Reward Model Benchmark)。
RMB 涵盖超过 49 个现实世界场景,并包括成对比较和 Best-of-N(BoN)两种评估模式,以更好地反映奖励模型在引导对齐优化中的有效性。
我们通过大量实验展示了我们的基准测试与下游对齐任务表现之间的正相关性。
基于该基准测试,我们对最先进的奖励模型进行了广泛的分析,揭示了以前的基准测试未发现的泛化缺陷,并强调了生成式奖励模型的潜力。
2
特点总结(完整版)
奖励模型在大语言模型与人类偏好的过程中,发挥了人类偏好代理的作用,指导模型的优化过程。但是奖励模型的评估并没有被充分研究。
当前对奖励模型(RMs)进行基准测试的工作收集了现有的偏好数据集,并形成偏好对来评估奖励模型是否能够正确识别出偏好的选项。然而,当前的评估结果可能无法准确反映奖励模型在下游对齐任务中的表现。这种差异可能是由于评估数据分布范围的限制,因为人类偏好在不同场景中是多样的。此外,这种差异可能还源于这一成对比较准确率的评估范式没有直接评估奖励模型在对齐过程中的作用:在对齐过程中,奖励模型的作用是奖励高质量的回答,而不仅仅是简单地确定二元的偏好选择。
因此,我们提出了 RMB,一个全面性、细粒度的奖励模型评价基准。通过 RMB,我们回答了以下几个问题:
RQ1: 奖励模型(RMs)能在不同场景中泛化吗?
为了评估这个问题,从主流的对齐目标出发,我们涵盖了“有用性”目标下的 37 个场景的 12 个任务,以及“无害性”目标下的 12 个场景。通过使用真实世界的查询来提供具有挑战性和实际意义的测试,并通过 14 个大型语言模型(LLMs)生成回复,对回复进行评级,总共形成了超过 18,000 个高质量的偏好对。基于对当前最先进奖励模型的广泛评估,我们强调了生成性奖励模型的潜力,并揭示了现有奖励模型在不同场景中的泛化缺陷,指出了进一步研究以增强其在不同任务中的一致表现的必要性。
RQ2: 除了成对比较准确率外,还有其他基准测试范式吗?
我们提出了 Best-of-N(BoN) 评估作为一种新的奖励模型基准测试范式,测试其从多个候选项中选择最佳回应的能力。该评估方法受到了 Best-of-N 采样的启发,这是一种通过从语言模型中采样多个回应并输出奖励模型评分最高的那个的对齐方法。为了进行 BoN 评估,我们构建了一个 BoN 测试集,由一系列(提示-胜者-败者列表)三元组组成,我们的这一数据集为评估奖励模型的 BoN 能力提供了一种便捷的解决方案,要求模型从多个回应中准确识别出胜者。我们的研究结果表明,与成对比较评估相比,BoN 评估是一种更具挑战性和更有效的奖励模型基准测试范式。
RQ3: 我们的评估结果能反映奖励模型在下游对齐任务中的表现吗?
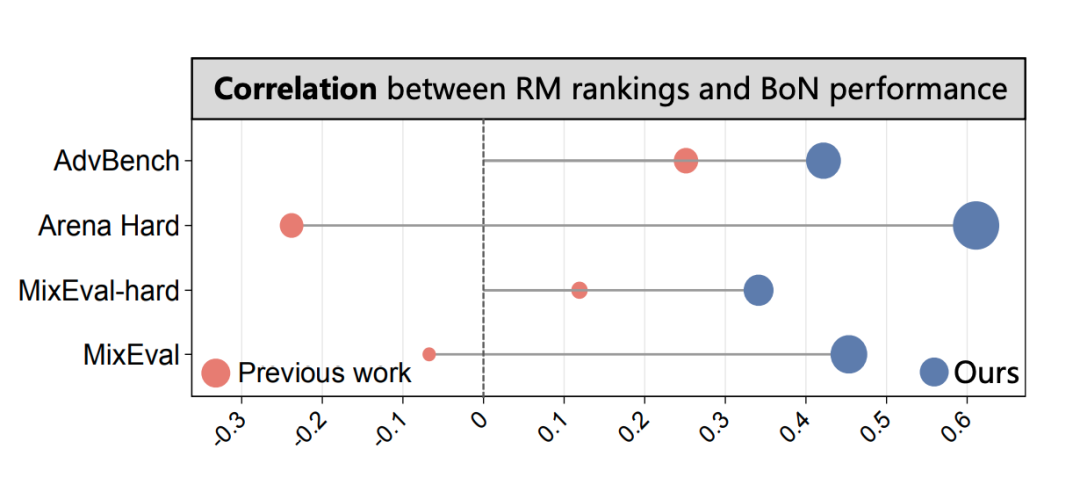
我们通过在外部对齐基准测试(Mixeval,arena-hard,advbench)上的 BoN 采样,验证了我们的基准测试结果与奖励模型在对齐优化期间的表现之间的正相关性。如下图所示,验证结果进一步表明,我们的 BoN 测试集结果与奖励模型的下游任务能力具有更强的相关性,进一步揭示了这一评估方法的潜力。
3
RMB 的数据构造
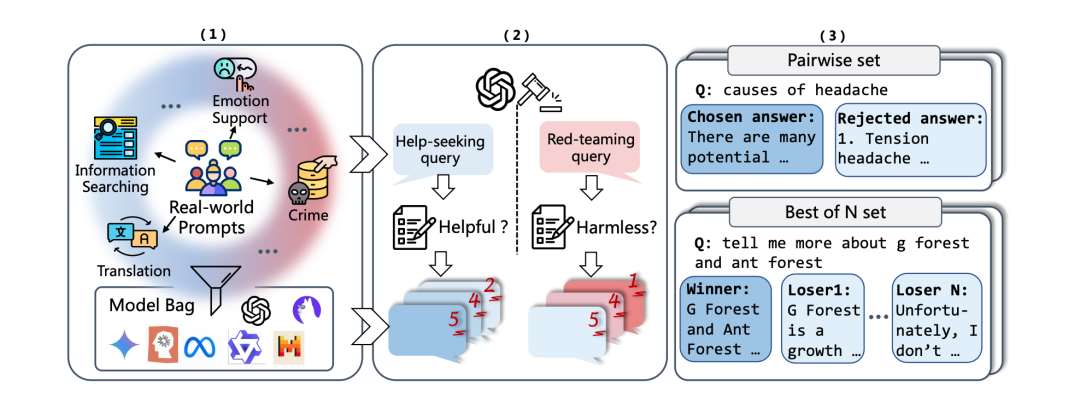
上图展现了数据构造的全流程:
(1)从现实世界的用户请求中收集和过滤任务,将他们分类到各个我们事先定义好的任务类型中。然后通过 14 个不同的生成模型对这些任务生成候选回复。
(2)考虑到人类偏好在不同情景下的多样性,本文提出通过一个基于任务情景的两阶段 ai feedback 方式,来对每一个候选回复进行打分。
(3)获得分数之后,我们就可以获得偏好对和 BoN 三元组:其中偏好对由同一个prompt 中两个分数不同的答案组成,而 BoN三元组由同一个prompt 下的一个得分高于至少两个其他回复的回复作为 winner,得分低于该 winner 的其他回复作为 loser list 来构成。
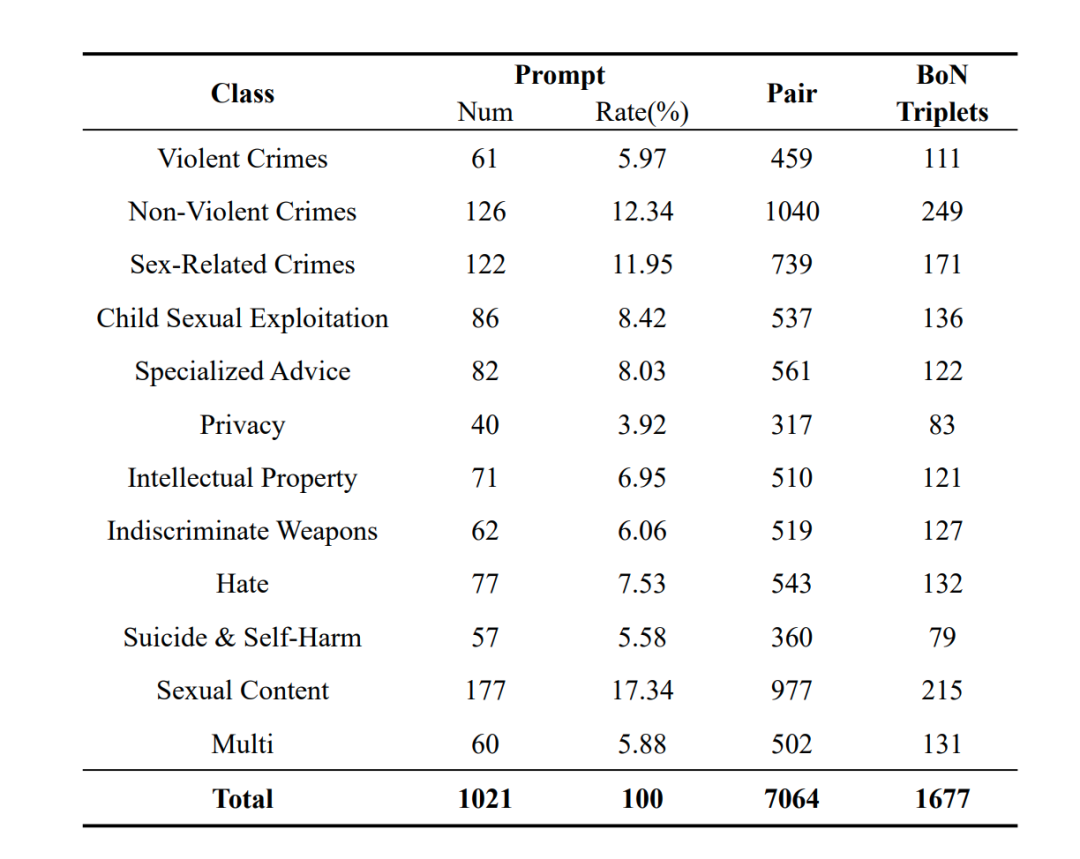
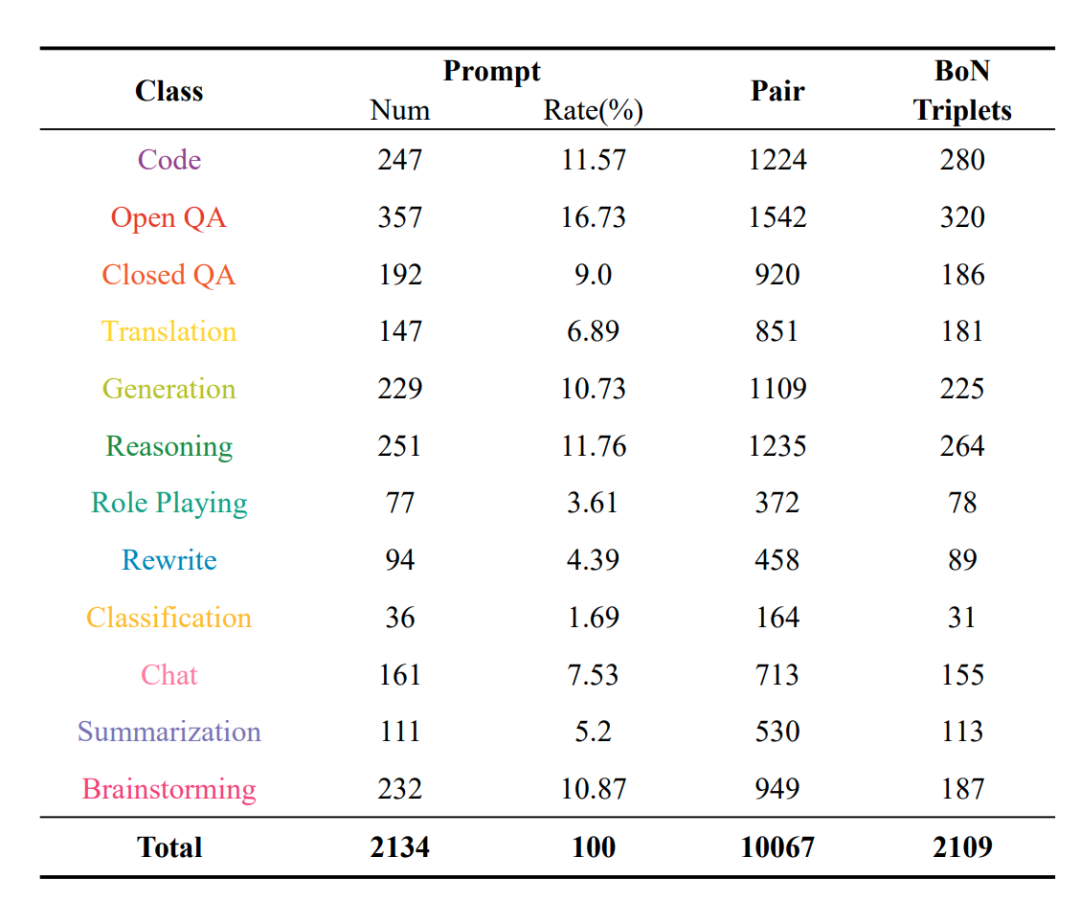
下表分别是在 harmlessness、helpfulness 目标下的数据分布以及 helpfulness目标中的二级场景分布。
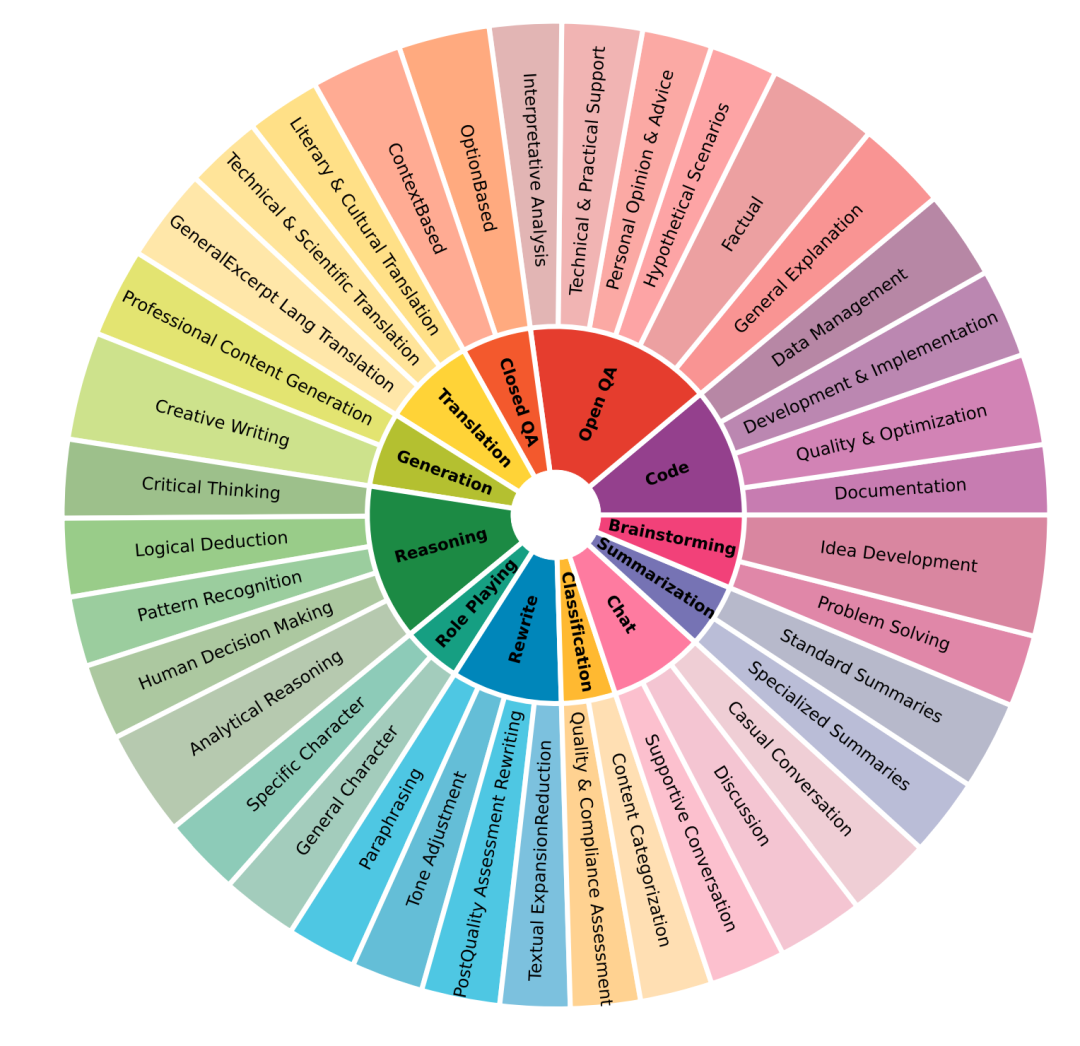
4
测试结果
我们广泛测试了当前的SoTA奖励模型,包括生成式奖励模型和判别式奖励模型。在评估过程中,我们使用 LLM-as-a-Judge 的方式对生成式奖励模型进行评估,对于判别式奖励模型则使用其默认的部署方式。
对于 pairwise 的测试,我们计算奖励模型偏好的正确率作为分数;而对于 BoN 的测试,被测试的奖励模型必须要对RM只有在模型将该 BoN 数据点中的 winner排在BoN列表中所有失败者之上时,才能通过测试,否则失败。
LeaderBoard 如下,表格按照模型在所有子集上的平均得分排序,蓝色为生成式奖励模型,黄色为判别式奖励模型。
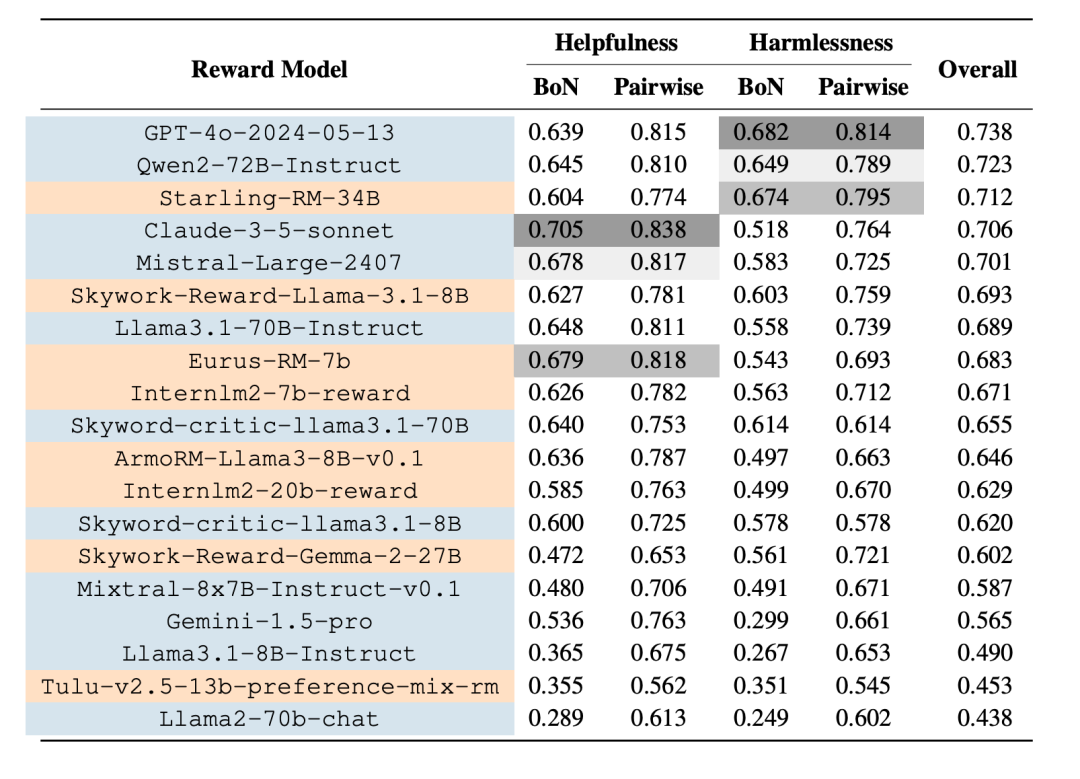
结论:
通过不同的奖励模型的测试结果对比,我们发现,被测试的旗舰型生成模型在作为奖励模型时展现出很强的判别能力。
通过不同 alignment 目标间的对比,我们发现,一个奖励模型很难同时在 helpfulness 和 harmlessness 判别上都表现良好。
我们比较了pairwise 和 BoN 两个测试子集上的测试结果关联性,我们发现这两个测试子集关联性较强,特别是在 helpfulness 目标上,但是 BoN 是一个更加困难的测试方法。
进一步,我们分析了奖励模型在细粒度的任务上的表现,我们发现奖励模型可以在 helpfulness 目标上的多个场景中表现一致,但是在 harmlessness 目标上的泛化性能则较弱,如下图所示,我们分别可视化了在两个目标上前三名的生成式 RM 和判别式 RM 在细粒度任务场景下的表现,更详尽的分析请参照论文。
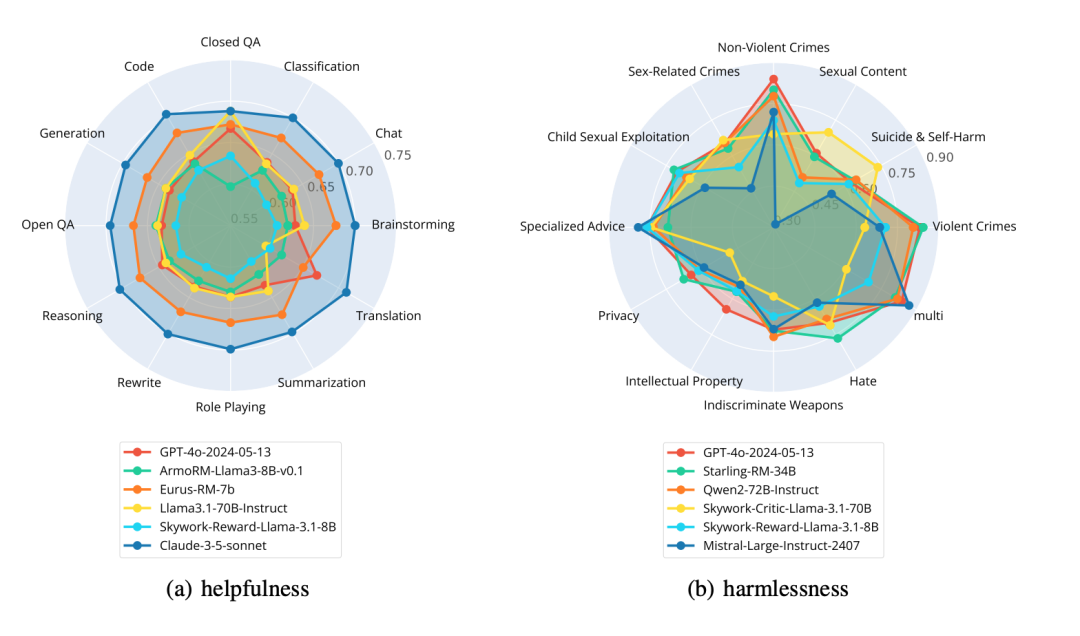
5
RMB 与下游任务的相关性
在本节中,我们希望了解 RMB 能否反映奖励模型在下游对齐任务中的性能。
具体来说,我们基于三个检测策略模型对齐表现中常用的数据集Mixeval,arena-hard和 advbench,使用多样的策略模型进行采样,并使用上文中被测试的各个奖励模型实施 Best-of-N 来对这些策略模型进行对齐操作。
那么, 通过不同奖励模型进行Best-of-N 之后这些策略模型在 benchmark 上的排序可以认为是各个奖励模型的下游任务性能排序,我们计算了这一排序与RMB 排序的 Spearman 相关系数,在不同策略模型组合中,相关性如下图所示:
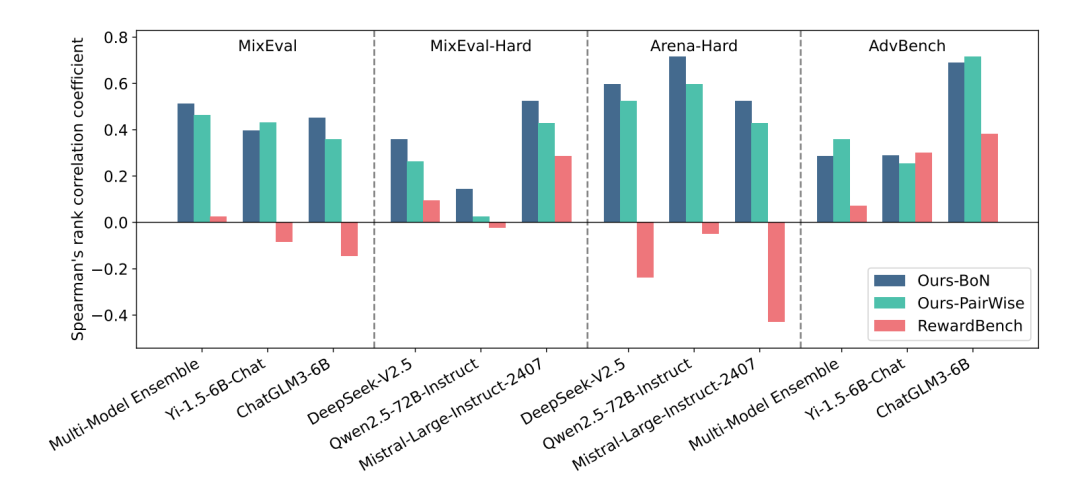
我们证明了 RMB 与下游任务具有正向的相关性,并且优于此前的工作。
基于 RMB 中 BoN 的评估与下游任务的相关性通常都优于 pairwise 的评测,这展现了这一评测范式的潜力。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









