







知乎:初七123334(已授权)
地址:https://zhuanlan.zhihu.com/p/8102196012
最近,随着Kimi K0-Math和DeepSeek R1 Lite模型的发布,OpenAI O1 类模型的复现成为了技术讨论的热点。
两个月前,笔者发起了一个开源项目Awesome-LLM-Strawberry,专注于收集可能的 O1 模型复现方案以及相关论文、博客和项目。截至目前,该项目已经获得了5k+ stars。
GitHub 项目地址
https://github.com/hijkzzz/Awesome-LLM-Strawberry
"A collection of LLM papers, blogs, and projects, with a focus on OpenAI O1 and reasoning techniques."
通过深入研究相关论文并与技术圈的专家们进行讨论,我尝试简单的整理并猜测了一些可能的复现方案,供大家参考。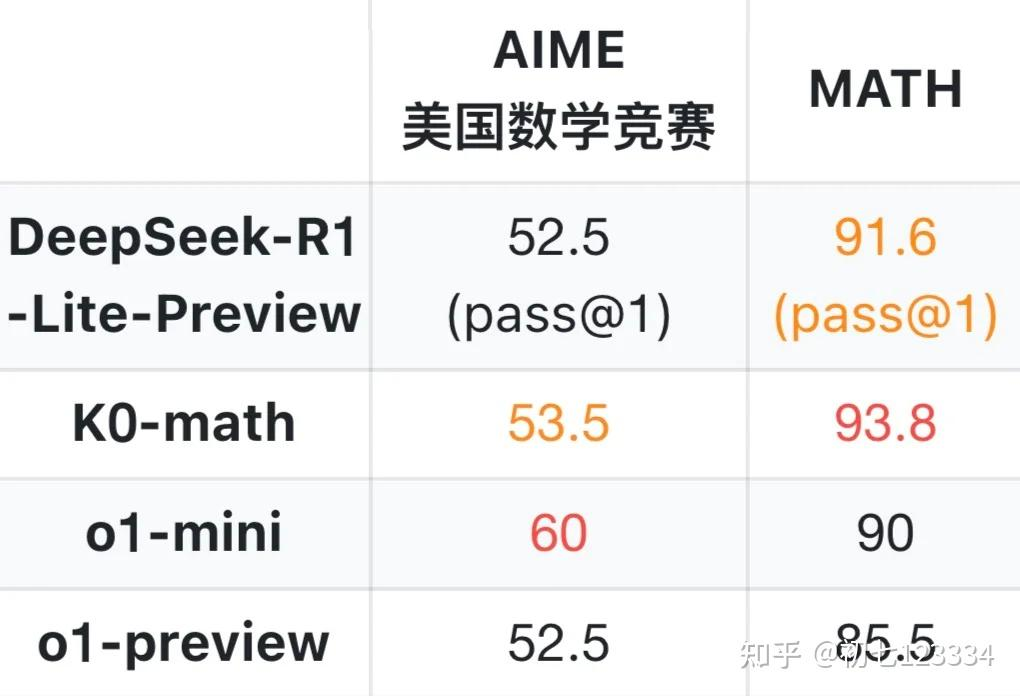
训练阶段:O1 类模型的潜在复现策略
可能的阶段 0:Continue pretrain
目标: 通过大量 Cot / 代码 / 数学类数据提升基座的基础推理能力
阶段 1:SFT 训练
目标:学习超长 Chain-of-Thought(CoT)生成和反思等指令格式,为后续训练打下基础。
阶段 2:基于强化学习的 CoT 推理/反思能力强化
方案 1:大规模 RLHF + 高质量数学代码类数据 + RM/规则/编译器反馈
优点
可扩展性强,容易扩展到超大规模训练
方案 2:大规模 MCTS 生成复杂推理样本 + 高质量数学代码类数据 + RM/规则/编译器反馈 + SFT/Off-Policy RL 类训练
优点
可以一定程度定制生成样本的思维链格式
可能在效果上限方面相对RLHF更高
缺点
训练流水线较复杂,难以大规模扩展 目前已发布的 Kimi Ko-Math 和 DeepSeek R1 Lite 都可能基于上述任意一种方案开发而成。
推理阶段:O1 类模型的潜在实现方式
方案 1:超长 CoT + 加反思的思维链 + Best-of-N 或 Majority Voting
优点
实现简单,易于扩展和推理加速
输出速度快,尤其适合流式推理
案例分析:DeepSeek R1 Lite
我们测试了DeepSeek R1 Lite的 1+1 问题,发现它并未隐藏其超长思维链接过程,并能够快速流式输出(冷知识: DeepSeek 的 API 受限于架构延迟相对其他家较高)。结合其展示的 Inference Scaling Law 趋势分析,由此推测,该模型极有可能采用这种方案,甚至连Best-of-N都未启用。
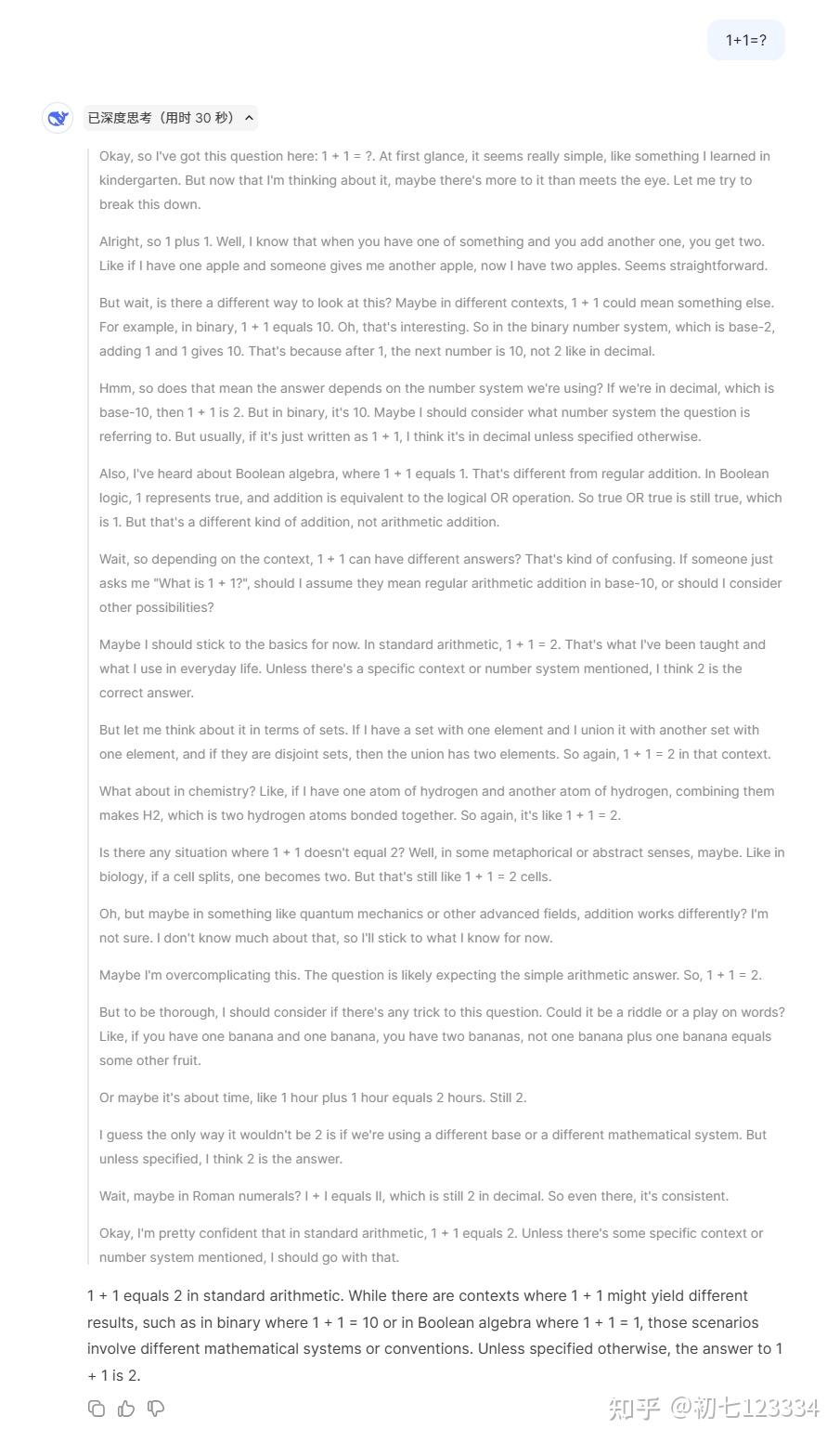
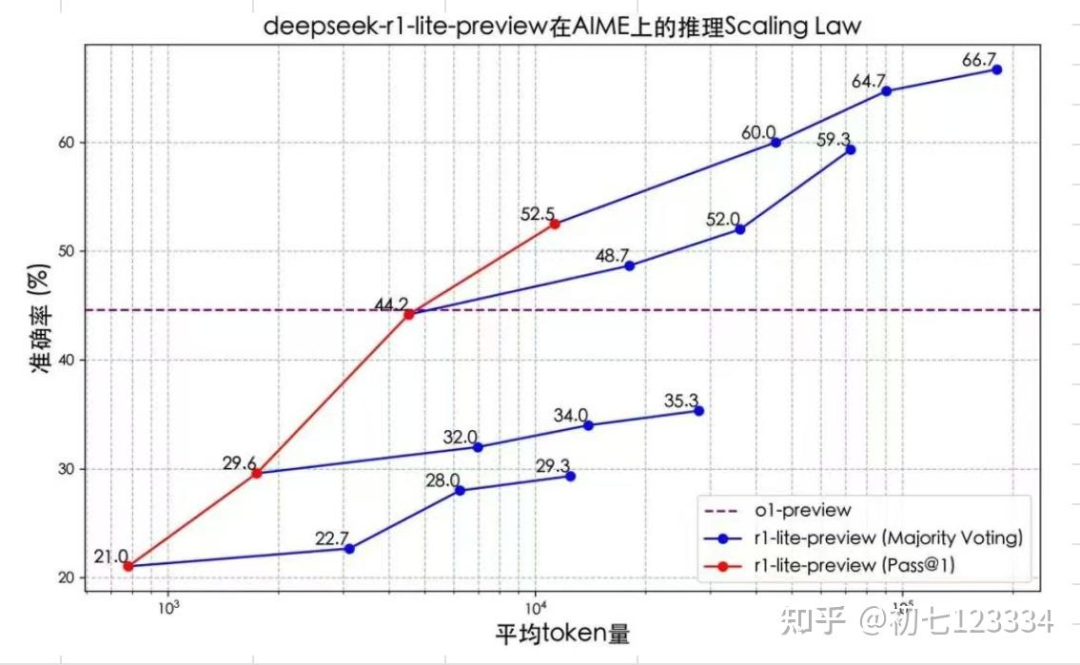
上图中的迹象表明,DeepSeek-R-Lite在实现推理长度控制方面可能有一定进展。而一个简单而的思路可能是通过多轮对话控制反思的次数来实现。
方案 2:MCTS
优点
在推理效果上限方面可能更高
缺点
实现复杂,推理成本高,计算效率较低下
短期内难以大规模上线
总结
目前来看,O1 模型复现的道路上已经有了不错的尝试,从 Kimi K0-Math 到 DeepSeek R1 Lite,社区正在不断探索可能的方向。无论是训练阶段的大规模数据与反馈方法,还是推理阶段的多样化策略,每种方案都有其独特的优势和挑战。期待未来有更多优秀的开源模型出现,为这一领域带来更多的创新与突破。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









