






大家都知道的一件事就是LLM真好用,就是太大了。咋部署才能更加高效呢?真的是个让脑阔疼的问题。
比如最近的几十万下载量Mistral-Small-24B-Instruct-2501和 Llama-3.3-70B-Instruct,以及百万下载量的DeepSeek-R1,都展现出大家对开源模型的认可和追捧。那么下载下来后,如何高效的利用上这些模型是一个值得研究的话题。
恰好,最近苏大联合华为发布的这篇survey很全面很系统的总结了100+种LLM部署的方法,下面我们来一起看看吧!
论文:Taming the Titans: A Survey of Efficient LLM Inference Serving
链接:https://arxiv.org/pdf/2504.19720
为什么LLM推理这么难?
一切问题归因于——体积大(吃内存)、算得慢(特有attn机制)。论文提到,注意力机制是最大瓶颈,它的计算复杂度是输入长度的平方。比如处理1000字的文本,计算量是100万级;而处理1万字,直接飙升到1亿级!
更头疼的是,用户希望“秒回”,但GPU显存装不下整个模型,还要兼顾多用户同时请求。这就是为什么论文说:“低延迟、高吞吐”成了LLM服务的“不可能三角”挑战。
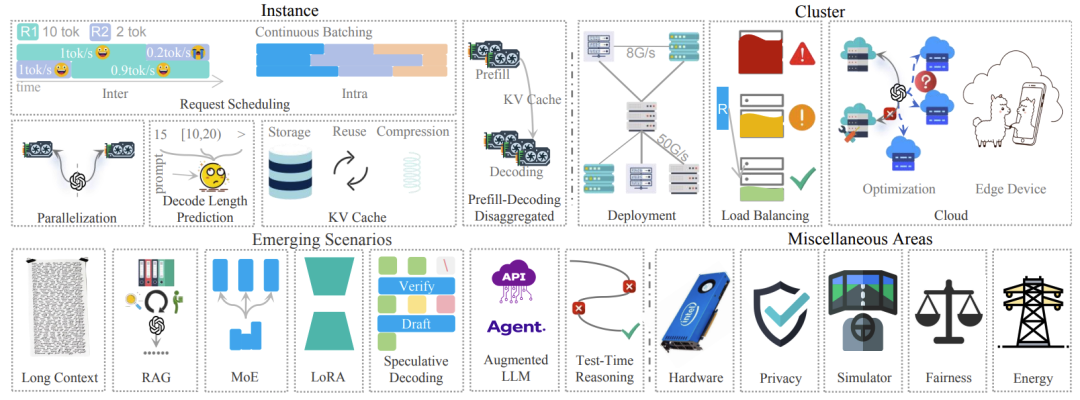
本篇文章从传统的单个实体级别(Instance)到集群级别(Cluster)的推理服务优化,以及最近比较新兴的场景与方法(长上下文、RAG、MoE、Agent等),最后为了全面还介绍了一些小众但重要方向(隐私、公平、硬件等方面)。
评价指标
一切的一切,还得先从评价指标开始说起。这里简单介绍下。
TTFT:从用户输入到生成第一个token的延迟时间 (就是响应速度,直接影响用户体验的第一印象)
TBT:连续两个token生成之间的时间间隔(输出流畅性)
TPOT:解码阶段生成每个token的平均耗时(衡量模型核心计算效率,有时候也和TBT相似)
吞吐量:每秒所有请求中生成的令牌总数(评估高负载下的系统容量)
容量:系统最大可持续吞吐量 确定性能上限(如服务器能承受的峰值请求量)
归一化延迟:总执行时间 ÷ 生成的令牌数量 综合效率指标(便于横向比较不同长度输出的资源消耗)
百分位数指标:延迟分布统计(识别系统稳定性边界,如P99=2秒意味着99%请求延迟≤2秒)
单实例优化:让一台GPU发挥200%的潜力
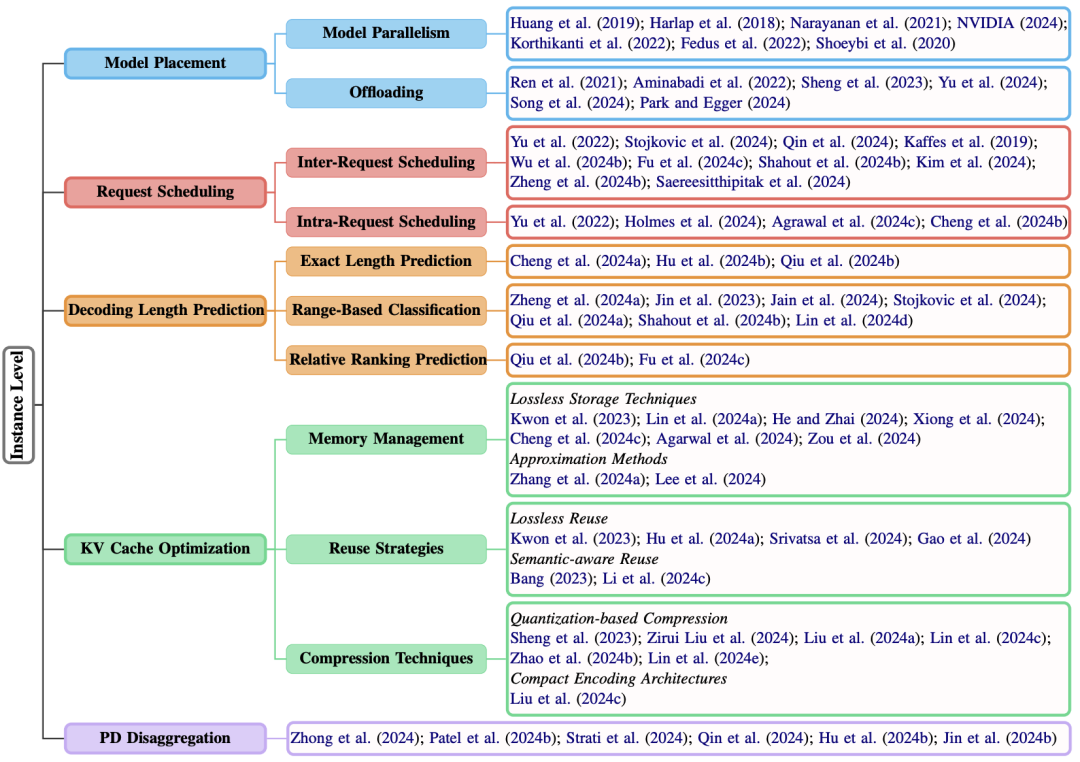
模型拆分与“搬家”
当单块GPU装不下模型时,工程师们玩起了“俄罗斯方块”——把模型拆成多个块,分到不同GPU上(Model Parallelism)。比如流水线并行(Pipeline Parallelism)像工厂流水线,每台设备只处理模型的一层;张量并行(Tensor Parallelism)则把矩阵乘法拆成碎片,多设备并行计算。 除了上述常见的外,还有序列并行(Sequential Parallelism)、上下文并行(Context Parallelism)和专家并行(Expert Parallelism)等。
当然也可以部分load到内存或者存储设备上。比如ZeRP-Offload、DeepSpeed-Inference。也可以将一些访问过多的神经元放到GPU,其他放到CPU,如PowerInfer等层级划分方法。
请求调度的“插队艺术”
Request之间的调度
目前通用的是先来先服务(FCFS)调度,如果用户A的请求要生成1000字,用户B只要10字,按“先来后到”处理,B会被“堵”到崩溃。论文提出动态调度算法,比如:
短作业优先(SJF):让生成字数少的请求插队;
多级反馈队列(MLFQ):设置不同优先级的队列;
剩余时间有限(SRTF):边解码边预测剩余的长度,更准确。
当然,上述都涉及到抢占策略,比如资源不够或者正在执行的时间太长还没结束,就需要抢占它来服务预计使用资源更短的request。
(这里预测解码长度会在下面的一个section来谈。
Request之内的调度
当来了一堆query(request)要送入模型执行,以前是需要等待上一批batch跑完再执行。而当Orca提出迭代级别调度后(continuing batching),就是每次输出一个token就执行一遍,谁结束了谁quit,然后插入新的继续执行下一个step。现在的vllm等都在用该调度。
上述也存在一个问题,每当进行新的request进行prefill操作的时候,decoding会暂停下。所以,为了解决的这样的问题,也有chunked-prefill方法和slice-level调度的提出,具体就是将prefill也切分或者设定固定长度的decoding长度来暂停并进行prefill调度。
生成长度预测
这个部分相当重要,直接决定前面request之间的调度的效果。这部分主要分为3种方法:
准确预测长度:比如通过bert或者一个小模型通过sigmoid预测一个确定的数;
预测长度范围:通过小模型预测提前划分好的一些范围区域;
预测长度相对位置:只预测该批次的所有request的相对位置。
预测相对位置其实更好理解,比预测具体长度要好,也更符合直觉。但是也有缺点,比如如果该批次的没有都进入执行阶段,那么执行下一波就得重新进行预测了,存在浪费资源情况。
KV缓存:推理加速的“临时笔记”
KVCache的存在将推理复杂度由平方降到了线性。但是涉及到存储,就会遇到以下问题:
管理
无损存储,比如PagedAttention,以及分布式KVCache处理的DistAttention;还可以offload到CPU上(FastDecode、LayerKV等);KunServe采用移出部分模型参数来放cache,该部分cache用完后用其他分布式设备的参数复原原模型参数等。
近似存储,比如采用聚类方法,将相似的cache只保留一份等。
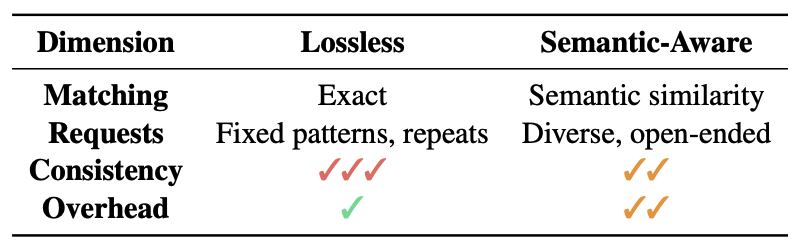
复用
无损复用:PagedAttention和Radix-Tree方法都是常用的复用方法,前者采用page-level复用,后者使用tree-based的共同前缀。
语义复用:顾名思义,如果request相近就可以直接复用全部output的cache。
压缩
量化压缩:这个方法还是很常见的,比如高精度到低精度、混合精读、针对特定channel或者token的特别压缩、以一个layer为锚点其他layer都与该锚点做差分的压缩等。
紧凑编码方法:就是用小的matrix来表示大的,这样在通道传输的时候会节省开销。
PD分离
该架构也是24年开始火的一个架构,就是将prefill和decoding分开,由于前者是计算型瓶颈后者是存储型,PD分离需要额外做的prefill处理完的token cache需要传给decoding来进行解码。这样的工作有不少,比如DistServe、Splitwise、Mooncake等。
集群作战:如何合理利用100台GPU?
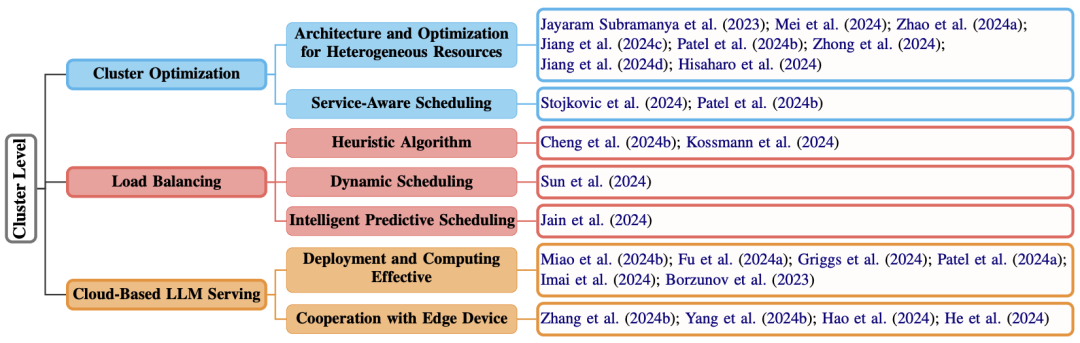 这部分主要介绍如何在一堆同样实例化模型的高效部署和调度了,主要从异构集群调度、集群负载均衡和云端部署与协作的角度来介绍。
这部分主要介绍如何在一堆同样实例化模型的高效部署和调度了,主要从异构集群调度、集群负载均衡和云端部署与协作的角度来介绍。
异构硬件协同
同构就不讲了,解决方法要么增加GPU要么用传统方法解决即可。异构才是集群高效利用常见的问题。毕竟不是所有人都能买得起统一型号的设备。
那么老旧GPU、新型AI芯片、CPU混搭怎么办?比如最大流算法(Max-Flow),将集群当做有向带权图,边为带宽,节点为GPU;还有为不同设备设置不同量化方法、不同的并行策略;以及PD分离架构中,给prefill高计算性能的GPU,给decoding高存储低计算性能的GPU等。
当然,还有针对外部环境(request的输入长度和解码长度)的设备安置方法(不同GPU频率等)。
负载均衡的“智能管家”
集群中可能出现“旱的旱死,涝的涝死”。解决方案包括:
最大最小方法:每次将request开销最大的给负载最小的机器;
动态迁移:把卡在慢GPU上的请求,“搬家”到空闲设备(如Llumnix);
强化学习调度:让AI自己学习最佳分配策略,像打游戏升级一样优化。
云端部署与协作
这部分主要是云服务部署(比如如何高效迁移已经部署正在跑的机器到其他设备上)以及手机等设备的云端协作(比如部分在手机上跑部分在云端跑、或者在身边多个人的设备上并行运行一个设备的模型推理)的相关研究。
长文本、RAG、MoE等新兴场景
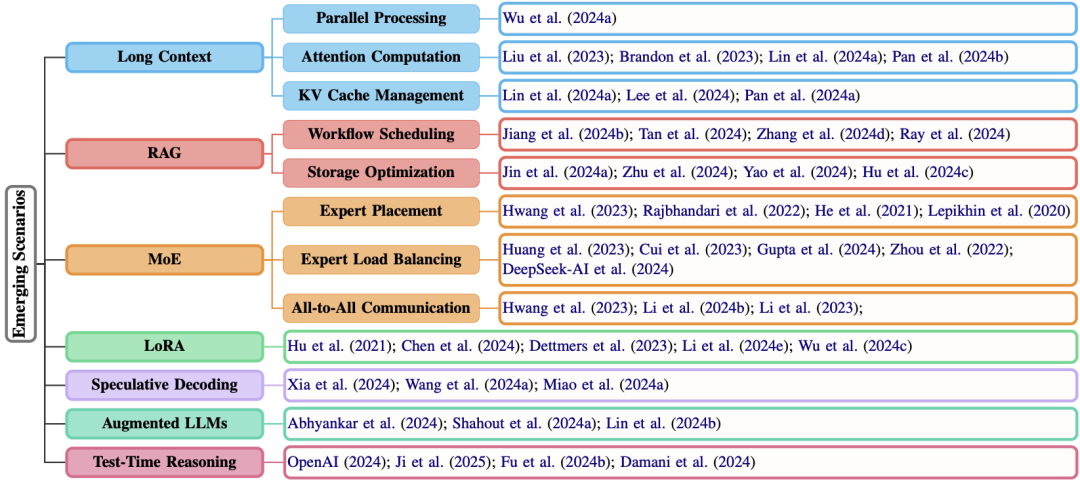
长文本的“分块切割术”
处理百万字长文本(如法律合同),传统注意力机制直接“爆内存”,KVCache的存储也是个大问题。 长文本主要分为3个部分:
如何并行:比如Loongserve的灵活序列并行方法,多设备接力处理,同时减少数据传输。
如何计算attn:将self-attn和FFN分布在多个设备上计算,以及进阶版DistAttention;将attn offload到内存进行计算的InstInfer等。
KVCache如何存储:比如动态管理上下文存储;offload到内存等。
RAG:外挂知识库的存储优化
RAG有复杂且动态得到处理流程以及同样存在KVCache的存储问题,所以解决方案主要分为两类:
工作流调度:PipeRAG的并行方法;RaLMSpec将推测解码方法用在了这里;RAGServe通过调度query和调整RAG的配置(文本切割、合成方法等)来平衡质量和延时。
存储优化:如RAGCache用知识树索引和动态推测并行方法,减少存储并加快检索速度;SparseRAG通过prefill和选择性解码来缓存,主要用在关键的token上;CacheBlend则通过选择一定比例的token进行cache,与其相似的是EPIC选择的是固定数量的每个block的前面的token。
MoE
DeepSeek-R1又又带火了MoE,它在高效推理服务的关键问题在于三点:
专家并行:比如不需额外开销的可交换并行、动态管道并行、结合专家切片的专家并行等。
专家负载均衡:每个专家被选择的频次是不一样的,这样就会导致很严重的不均衡问题。解决方法有比如将活跃的专家留在GPU,不活跃的放到CPU;动态为每个专家分配GPU;DeepSeek直接为过热的专家重新copy一份。但是这样的不均衡问题,归根结底还是来自每个token自己来选专家,如果反过来那么就不会存在这个问题了,ExpertChoice就是这么考虑的。
All-to-All通信:最耗时间的应该就是这部分了,就是专家处理的前后都有该部分存在,比如为了token选择哪些专家、专家们处理完如何快速收集。
LoRA
没错,这部分也有特有的推理服务,比如如何对拥有不同rank的模型们进行多路复用、高效调度等。这里感觉不是现在的研究重点,感兴趣可以去读读论文哈。
推测解码
推测解码的论文去年好多好多,但是关于推理服务的就一篇:SpecInfer使用tree-based的解码方法在单GPU上的offload推理。
增强式LLM
最近通过API和基于LLM的Agent都使得LLM得到了史诗级加强,但是如何调度呢。比如可以通过预测API执行时间来规划当前的服务药用的时间和资源判断要不要被强占;Parrot通过为agent的每个request设置一个tag来让调度服务知晓其拓扑结构,知道哪些优先执行完,才算完成一个agent任务。
Test-Time Reasoning
这个是当前的热点话题,但是目前只发现2篇关于其推理服务的工作。Dynasor通过跟踪reasoning过程来获取哪些该分配多少资源、哪些可以提前结束并释放资源;以及另一篇工作通过为每个问题提前判断难易度、通过内置reward model评估其最大收益来分配计算资源。
小且重要方向:硬件、隐私、能耗等
 这部分就不详细展开了,这里用简短语言介绍下:
这部分就不详细展开了,这里用简短语言介绍下:
硬件:比如如何结合HBM、DRAM、SSD的offload方法;如何在Intel GPU上的推理;如何在咱们能买得起的如3090上部署等;还有在手机端的部署、NPU上的调度等。
隐私:比如当其他人获取了你的KVCache在知道你用的是哪个LLM,那么就能完全复原你的对话。
模拟器:现在硬件太多了,不是人人都能在上面进行各种优化实验的,太费钱,所以做模拟是个很不错的选择,最近也陆续有这样的工作出来。
公平性:除了前面面向request的推理服务算法外,也应该面向每个user的服务,比如你问了很多问题都有了反馈,我问的问题,迟迟得不到回应,那么就严重影响用户体验,严严重点就是公平性问题。
能源:LLM训练和推理都太费电了,是不是有有些训练可以你在一些GPU上操作,一些比如推理可以在其他GPU上操作等,需要探索一种可持续发展的LLM系统。
未来工作
这个LLM推理服务方向其实感觉研究方向还挺多,举几个例子:
有前后依赖的request调度:比如一个任务由多个request在某种拓扑结构下完成才算结束,比如agent、RAG等。
多模态推理服务:图片处理和文字处理不是一个速度,那么如何平衡这两者中间的关系呢?
LLM辅助LLM调度:LLM这么强大,能否自己来让自己更高效呢?
前面总结的还是较为浅显,感兴趣欢迎读原文哈!希望对大家有帮助!
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

















 2304
2304

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









