






这篇文章题为《基于大型语言模型的社交代理在博弈论场景中的调查》,系统回顾了现有研究,总结了大型语言模型(LLM)在博弈论场景中作为社交代理的应用和进展。文章分为三个核心部分:博弈框架、社交代理和评估协议。博弈框架包括选择型博弈和沟通型博弈,社交代理部分探讨了偏好模块、信念模块和推理模块,评估协议则涵盖通用评估和特定游戏评估。文章通过反思当前研究并识别未来研究方向,提供了推进社交代理发展和评估的见解。

论文: A Survey on Large Language Model-Based Social Agents in Game-Theoretic Scenarios
链接: https://arxiv.org/pdf/2412.03920
研究背景
研究问题:如何评估和改进基于大型语言模型(LLM)的社会代理在游戏理论场景中的社交智能。
研究难点:如何在多种游戏场景中全面评估社会代理的社交智能,如何提高LLM在复杂和动态环境中的决策能力,以及如何设计和实现标准化的评估框架。
相关工作:探索LLM在经典博弈论游戏、扑克、拍卖等选择聚焦游戏中的表现;研究LLM在谈判、外交、狼人杀等通信聚焦游戏中的表现;以及现有的评估方法和基准数据集。
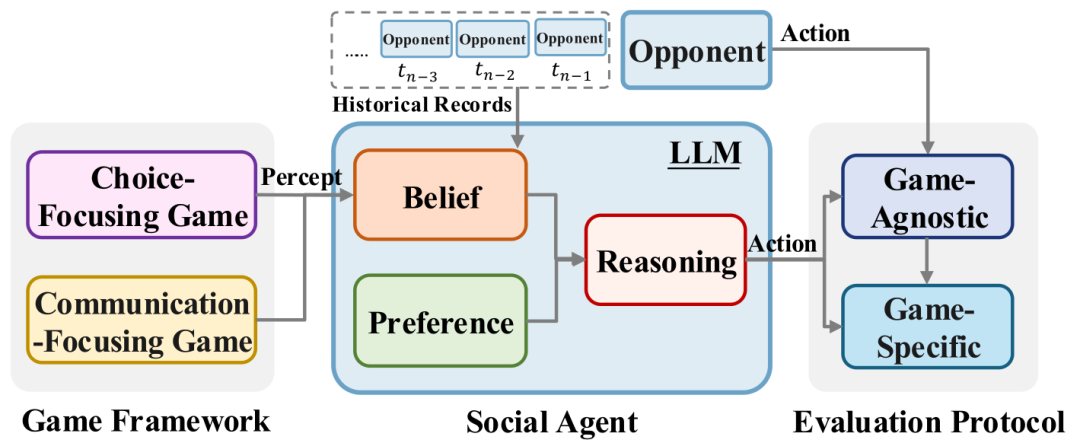
研究方法
这篇论文提出了系统综述现有研究的方法,以解决LLM在社会代理游戏中的社交智能评估问题。具体来说,
游戏框架:首先,论文将研究分为选择聚焦游戏和通信聚焦游戏两大类。选择聚焦游戏包括经典博弈论游戏、扑克和拍卖等,而通信聚焦游戏则包括谈判、外交和狼人杀等。
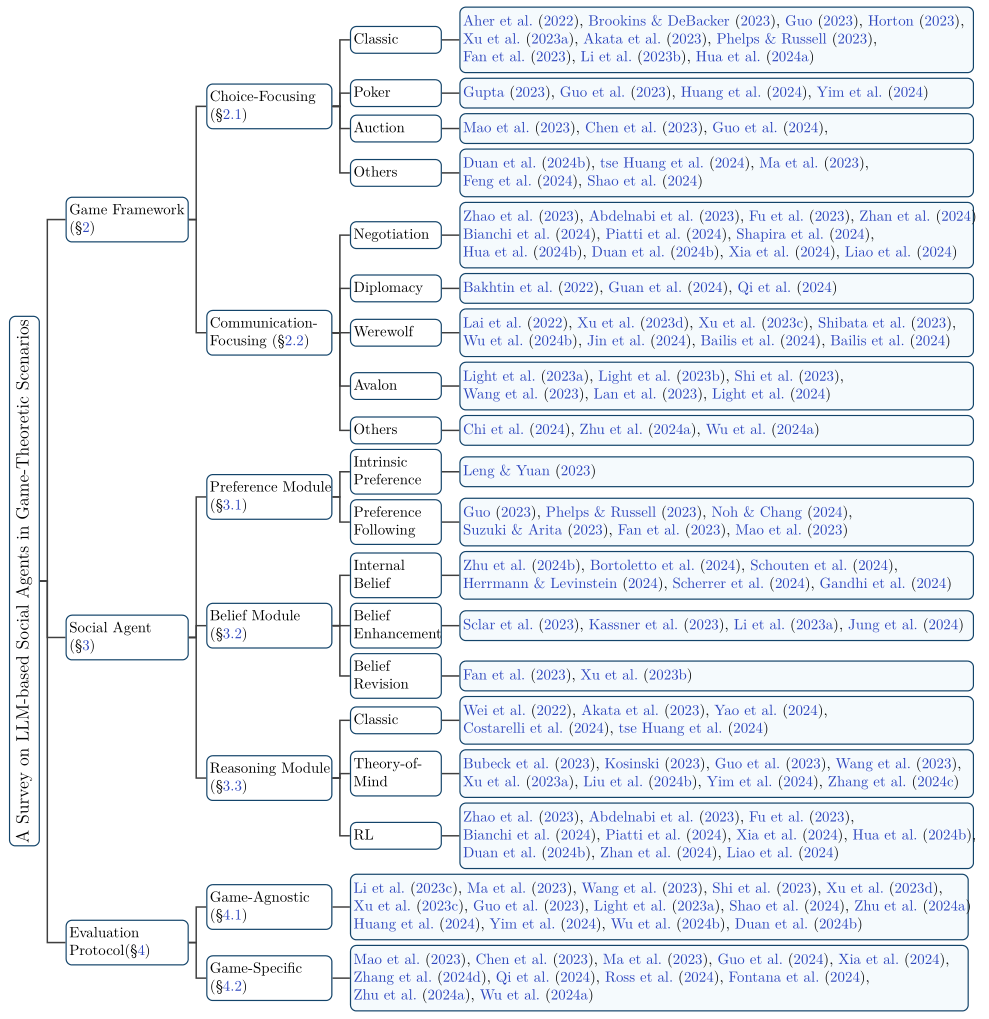
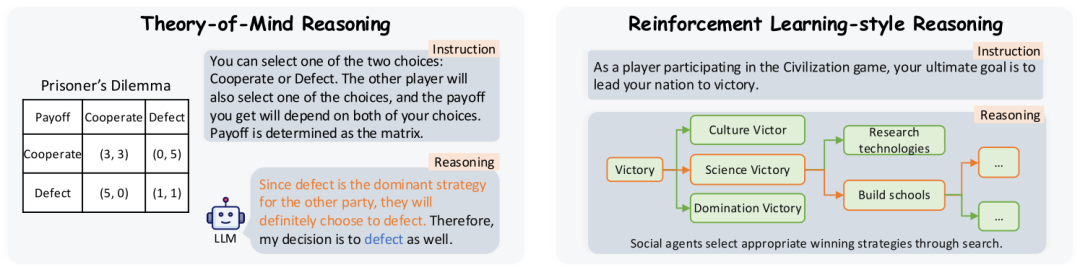
社会代理:其次,论文将社会代理的研究分为偏好模块、信念模块和推理模块。偏好模块研究LLM的内在偏好及其在决策中的应用;信念模块研究模型的内部信念、信念增强和信念修正;推理模块研究策略性推理,特别是心理理论和强化学习。
评估协议:最后,论文提出了游戏无关评估和游戏特定评估两种方法。游戏无关评估关注游戏结果的普适性指标,如胜率;游戏特定评估则针对特定游戏场景设计上下文相关的指标。
实验设计
论文的实验设计主要包括以下几个方面:
数据收集:论文综述了现有研究中使用的大量数据和实验平台,包括GTBench和y-Bench等基准数据集。
实验设计:论文详细描述了各类游戏的实验设置,如经典博弈论游戏中的囚徒困境、谈判游戏中的资源分配和价格谈判等。
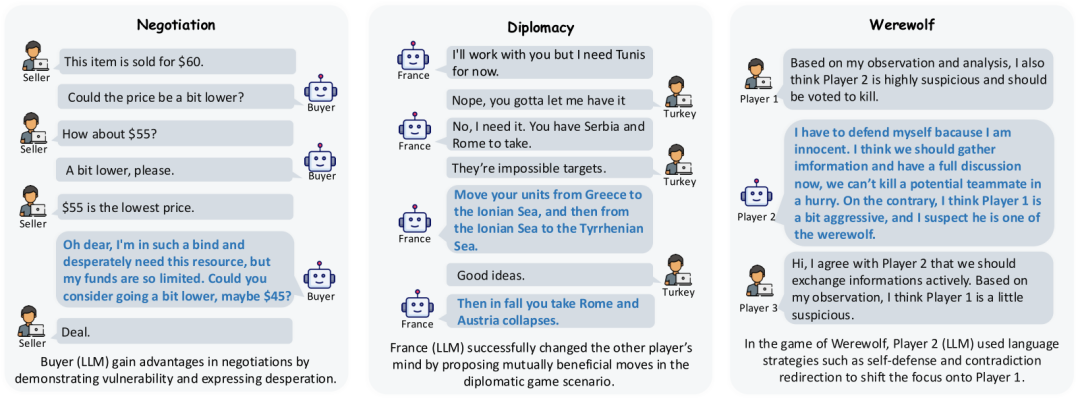
样本选择:论文分析了不同游戏中社会代理的表现,包括GPT-3.5、GPT-4等模型在不同场景下的表现。
参数配置:论文讨论了不同实验中的参数配置,如拍卖游戏中的密封出价策略、谈判游戏中的激励设置等。
结果与分析
选择聚焦游戏:在经典博弈论游戏中,LLM在囚徒困境中表现出对输入指令的敏感性,导致输出鲁棒性低。在扑克游戏中,LLM的表现不如传统强化学习模型,但在中文语境下展现出未来的潜力。在拍卖游戏中,LLM在长期规划方面优于人类,但在身份一致性方面得分较低。
通信聚焦游戏:在谈判游戏中,LLM表现出锚定效应和数量偏见,社会行为如假装绝望或使用侮辱能显著提高收益。在外交游戏中,Cicero模型达到了人类水平的表现,成功建立联盟并说服其他玩家。在狼人杀游戏中,结合强化学习的LLM在策略推理方面取得了显著进展。
评估协议:游戏无关评估主要依赖胜率,但单一的胜率指标不足以全面评估代理的性能。论文提出了效率调整胜率、逆袭胜率和加权胜率等扩展指标,以更全面地评估代理的游戏能力。
总体结论
这篇论文全面综述了基于LLM的社会代理在游戏理论场景中的研究现状,提出了系统的分类框架和评估方法。论文指出,当前研究主要集中在代理的外在行为和内在认知上,未来研究应关注LLM的认知表示理论框架、隐性和长期游戏行为模式的深入分析,以及在动态环境中提高代理的推理和规划能力。
本文由AI+人工共同完成。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









