






现有的图像生成和编辑方法就像“直男画画”——把文字提示直接怼进模型,完全不懂构图和空间关系。比如你说“猫在沙发上喝咖啡”,结果AI可能生成一只猫抱着咖啡杯坐在沙发顶上,咖啡杯还悬在空中!

论文:GoT: Unleashing Reasoning Capability of Multimodal Large Language Model for Visual Generation and Editing
链接:https://arxiv.org/abs/2503.10639v1
项目:https://github.com/rongyaofang/GoT
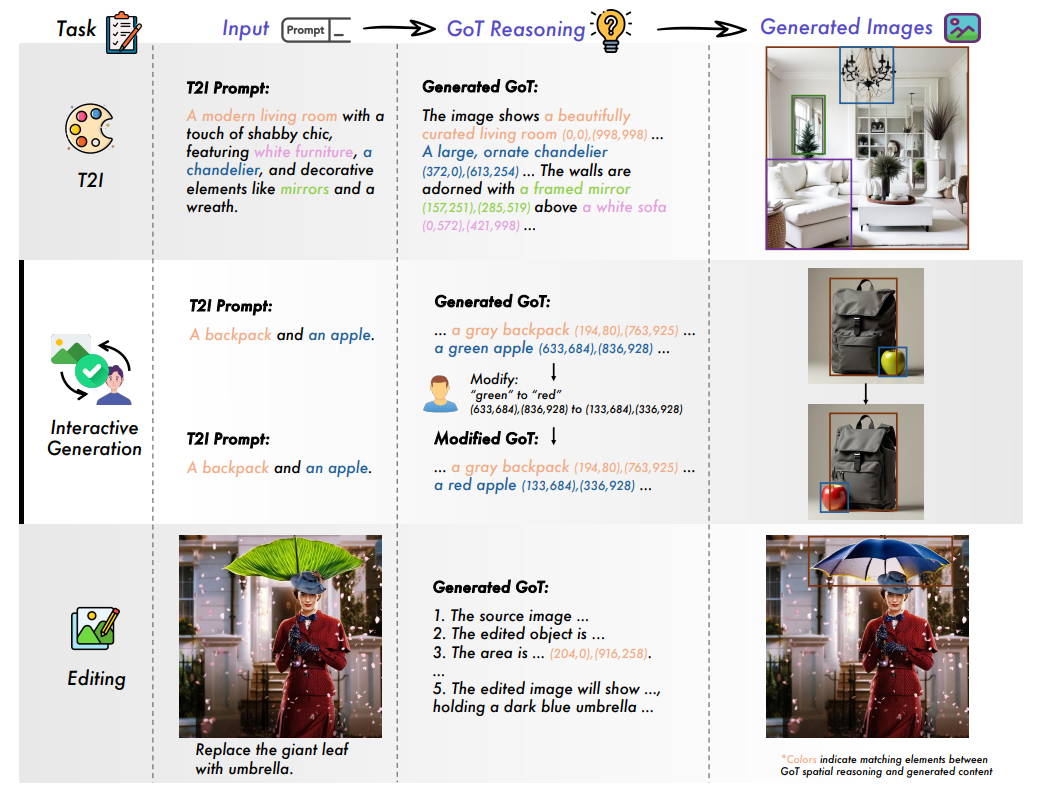
GoT(Generation Chain-of-Thought)横空出世,让AI学会“先动脑再动手”——生成图像前先输出一段包含语义关系和空间坐标的推理链条。就像老师教小朋友画画前先画草图:“猫在沙发左边,咖啡杯放右边桌子,沙发是米色的……”这下AI终于能画出符合人类脑洞的作品了!
方法
GoT的核心是让AI生成语义-空间双推理链条。比如生成“雪地里戴围巾的企鹅”时,AI会先推理:“企鹅(坐标X,Y)站在雪地中央,红色围巾(坐标A,B)绕在脖子上,背景是雪山(坐标C,D)……”
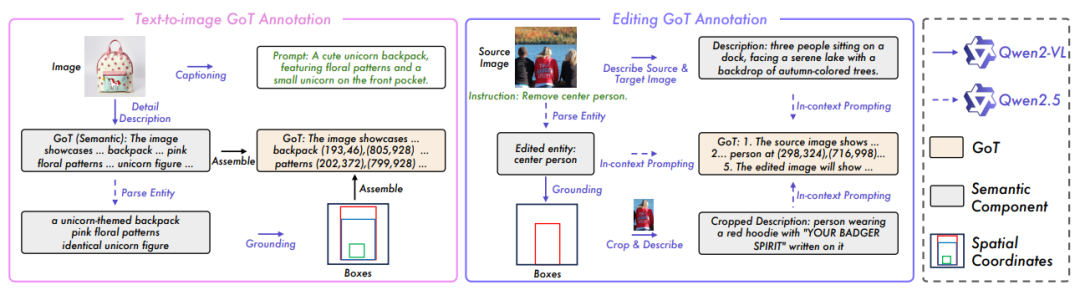
为了训练这个“推理狂魔”,作者们肝出了900万条标注数据!包含文本生成和图像编辑任务,每条数据都有详细推理步骤和坐标标注。他们甚至动用了100块A100显卡跑了一个月,堪称AI界的“基建狂魔”。
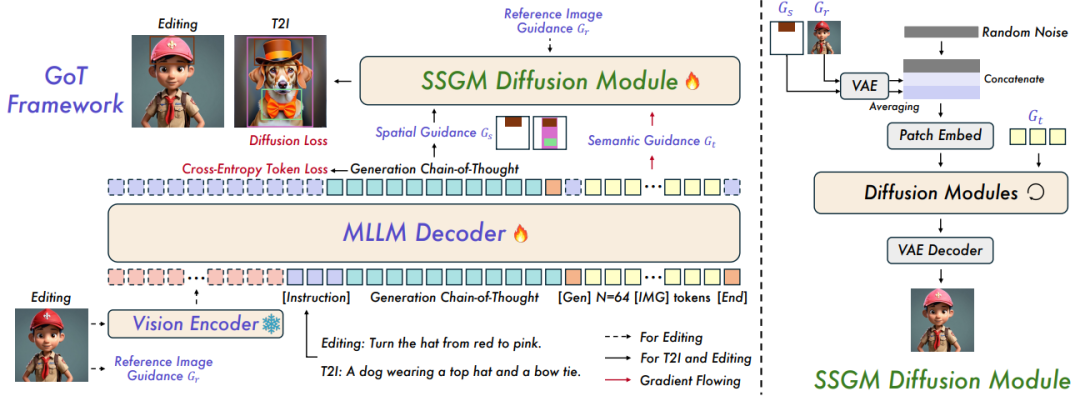
模型架构更是黑科技满满:用Qwen2.5-VL模型生成推理链条,再通过语义-空间引导模块(SSGM) 指导扩散模型生成图像。简单说就是“文科生负责写剧本,理科生负责拍电影”,配合得天衣无缝!
实验
文本生成:从“灵魂画手”到“细节控”
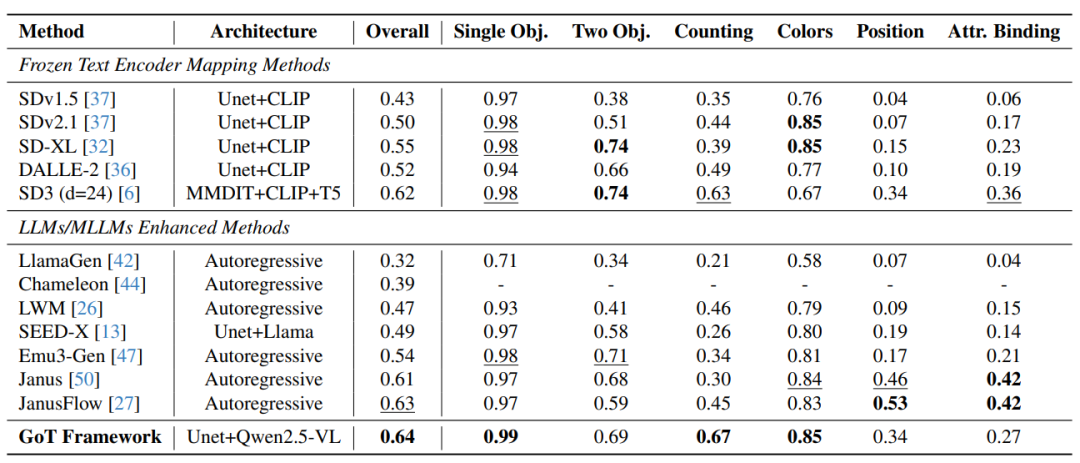
在GenEval基准测试中,GoT在复杂场景生成(多物体、颜色绑定、空间位置)全面碾压传统方法!比如“数数任务”得分0.67,比CLIP系方法高出一大截,终于不用再担心AI把“三只猫”画成“猫三头”了。
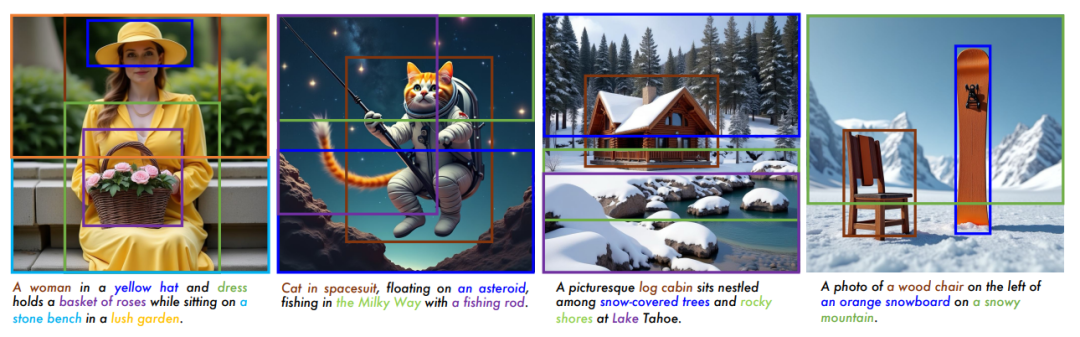
交互编辑:“哪里不对改哪里”
用户可以直接修改推理链条!比如把“戴红围巾的企鹅”改成“戴蓝帽子的企鹅”,AI会立刻调整对应坐标和描述重新生成,就像给AI发微信:“亲,这里改一下呗~”

图像编辑:“PS大师”上岗
在Emu-Edit等基准测试中,GoT的CLIP-I得分0.864登顶,连“替换树叶为雨伞”这种高难度操作都能精准完成。更绝的是支持多轮编辑:“先给猫戴帽子→再把背景换成星空→最后加个彩虹”,妥妥的甲方快乐机!
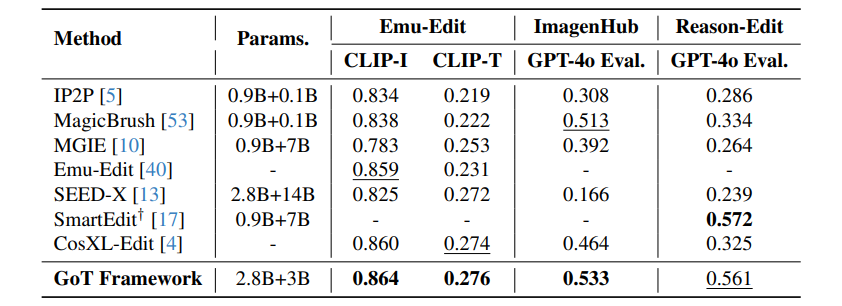

消融实验:“拆开看看为啥牛”
作者把模型拆得明明白白:加入SSGM模块后,图像编辑性能直接翻倍;完整框架+预训练后,效果更是坐上火箭。

结论
GoT通过给AI装上“思维导图”外挂,让图像生成从“直男式输出”变成“逻辑控创作”。无论是把“文字脑洞”变成精美图片,还是实现“指哪改哪”的精准编辑,GoT都展现出了碾压级优势。想象一下,未来做设计海报时,只要对AI说:“把LOGO左移10像素,标题换成金色,背景加星空…”——打工人狂喜!
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









