






人类的聪明之处在于能“分步骤解决问题”。比如算一道数学题,我们会先列公式、再分步计算,最后验证结果。而传统的AI模型更像“直觉派选手”,直接输出答案,但面对复杂任务容易出错。 论文:Why Reasoning Matters? A Survey of Advancements in Multimodal Reasoning
论文:Why Reasoning Matters? A Survey of Advancements in Multimodal Reasoning
地址:https://arxiv.org/pdf/2504.03151
这篇论文指出,让模型学会“推理”(比如分步骤思考、自我修正)是提升其能力的关键。例如,Chain-of-Thought(思维链)技术让模型像学生写作业一样展示解题过程,不仅提高答案准确性,还能让人类理解模型的“脑回路”。
多模态推理的难点:当模型同时看图和读文字
想象一下,你看到一张“猫在沙发上”的图片,但文字描述是“狗在睡觉”。人类能轻松判断矛盾,但模型可能会混乱——这就是多模态推理的挑战:融合视觉与语言信息,处理矛盾或缺失。
论文提到,模型需要解决三大难题:
信息冲突(比如图文不一致)
空间关系理解(判断物体位置)
幻觉控制(避免“无中生有”,比如把沙发上的猫说成老虎)。
这些能力需要模型既能“看细节”,又能“逻辑自洽”。
两大技术路线:训练优化 vs 实时推理
为了提升推理能力,研究者分成了两大门派:
门派一:课后补习班(Post-training)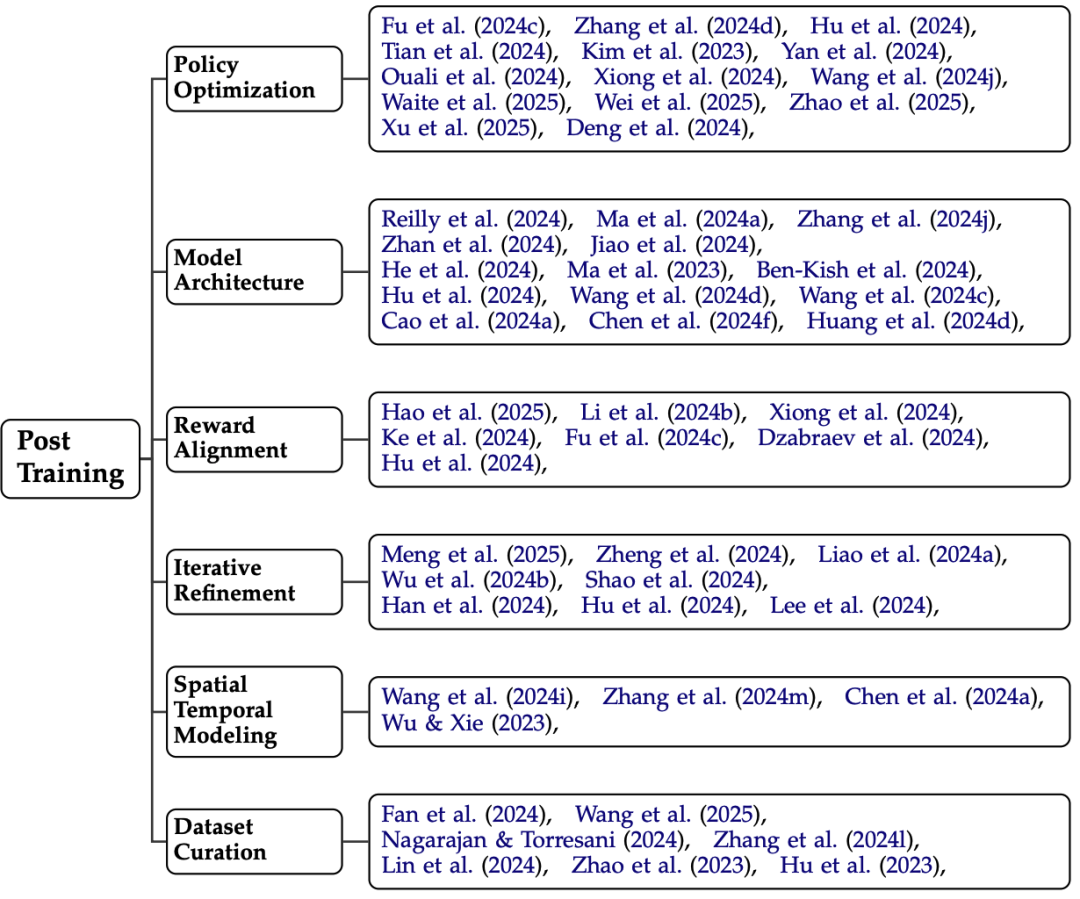
目标:通过额外训练让模型变得更聪明。
方法:比如用强化学习“发奖状”,鼓励它生成更合理的推理路径;或者模仿人类解题步骤(模仿学习)。
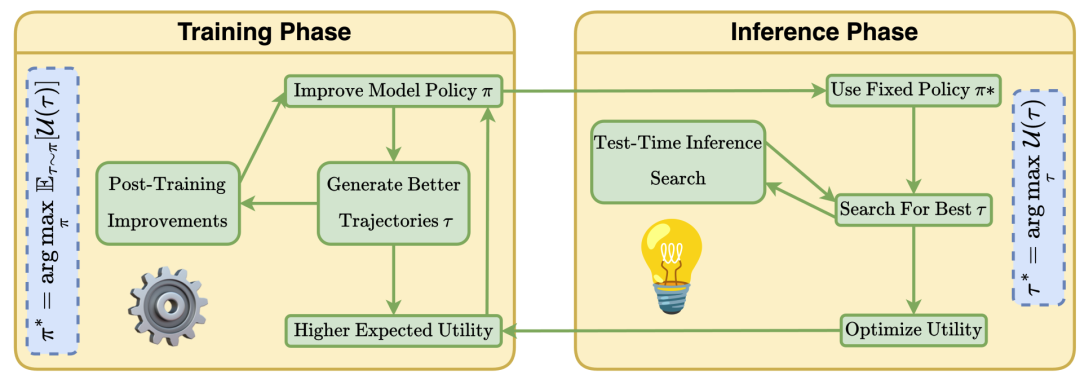
门派二:考场现学现卖(Test-time Compute)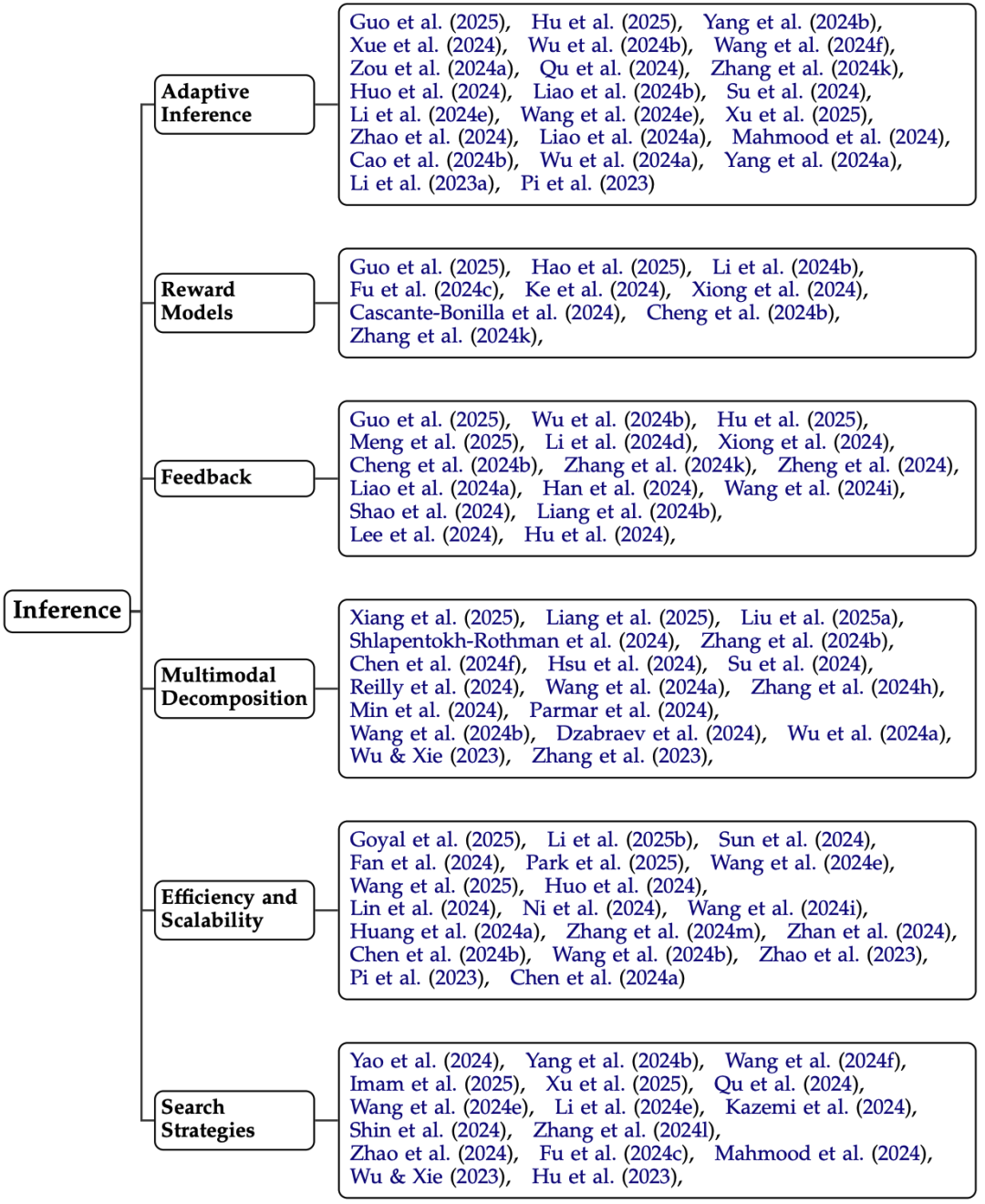
目标:不修改模型参数,在答题时动态优化。
方法:比如生成多个解题思路(类似“头脑风暴”),再选最优答案;或用蒙特卡洛树搜索(MCTS)模拟“试错过程”。
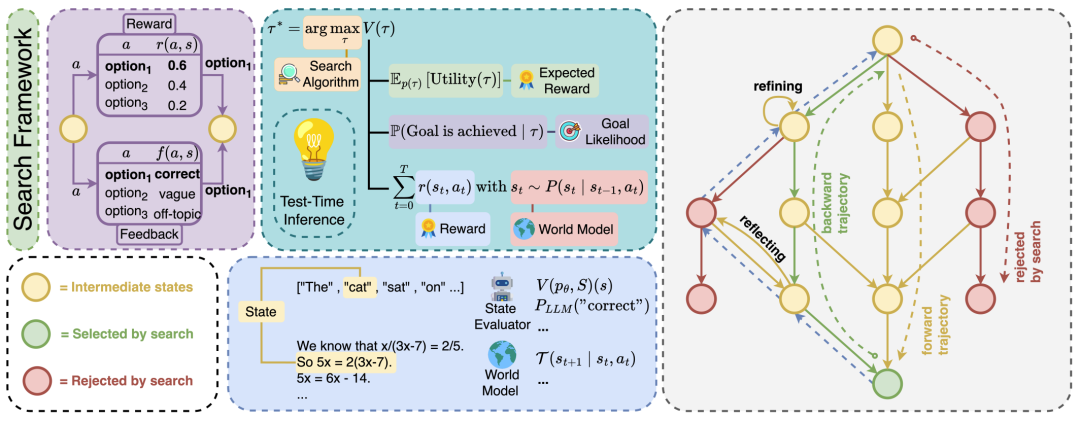
数据集与评估
要检验模型的推理能力,需要设计“高难度考题”。论文列举了多类数据集:
时空推理题:比如视频问答,要求模型分析动作顺序(人类正确率90%,模型仅15%)。
反事实推理:比如问“如果电视关着,画面会怎样?”考验逻辑想象力。
自我修正题:让模型从错误中学习,比如先答题再根据反馈修改。
这些数据集像“奥数竞赛题”,专门测试模型的薄弱环节。
未来展望
论文指出了几个关键方向:
视觉奖励机制:让模型从图像细节中自主总结规律(比如通过“放大图片”找线索)。
动态交互能力:不仅能看静态图,还要理解视频中的连续动作。
减少依赖人类标注:用自动化方法生成高质量训练数据。
未来的AI可能像“侦探”,能主动观察、推理,甚至预测未发生的情景。
实际应用
教育:AI家教能分步骤讲解题目,指出学生错误。
医疗:结合医学影像和病历文本,辅助诊断。
自动驾驶:实时分析路面视频和传感器数据,预判风险。
内容创作:生成图文高度匹配的广告或故事。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









