






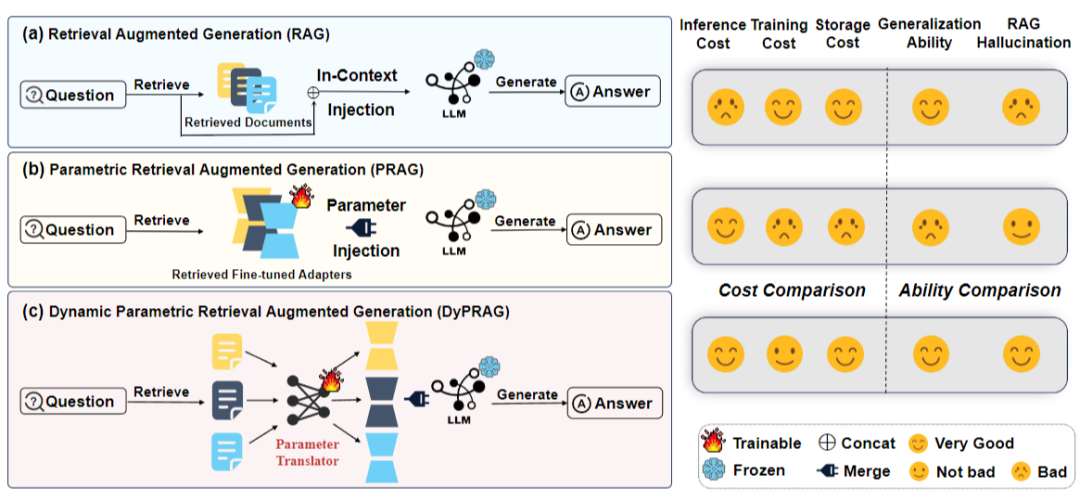
检索增强生成(RAG)通过从外部源检索相关文档并将其合并到上下文中来增强大语言模型(LLMs)。虽然它通过提供事实文本提高了可靠性,但随着上下文长度的增长,显著增加了推理成本,并引入了具有挑战性的RAG幻觉问题,这主要是由于LLM中缺乏相应的参数知识造成的。
参数化RAG (PRAG)通过离线训练将文档嵌入大模型参数有效地降低推理成本。然而其高昂的训练和存储成本以及有限的泛化能力,极大地限制了其实际应用。
我们提出动态参数化RAG,在推理时将文档知识动态转化为模型参数知识,能有效补充相应知识。并且能即插即用无缝和RAG结合,提升模型知识内化水平同时减少RAG幻觉的发生。
论文:Better wit than wealth: Dynamic Parametric Retrieval Augmented Generation for Test-time Knowledge Enhancement
链接:https://arxiv.org/pdf/2503.23895
项目:https://github.com/Trae1ounG/DyPRAG
编辑:深度学习自然语言处理 公众号
方法
DyPRAG的核心思路在于训练一个轻量的参数转换器来建模从文档->参数的潜在映射,仅需要少量的训练数据就能有效学习到泛化性极强的转换器,在推理时几乎不会引入额外的计算开销且能提升模型性能,最少只需要2MB存储开销。
实验
分布内QA实验
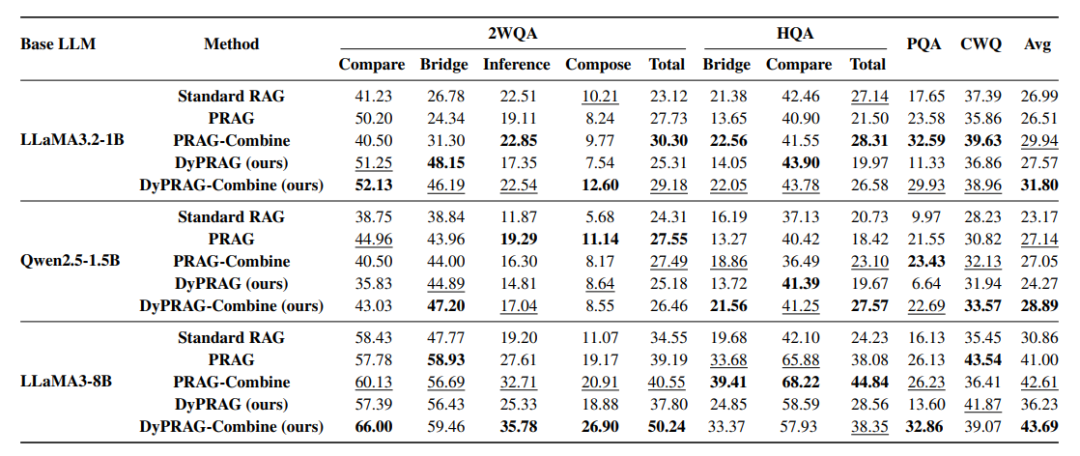
在多个问答数据集上训练参数转换器并进行实验,DyPRAG表现出极优的性能:
DyPRAG能有效注入参数知识:对比RAG,在没有提供任何文档拼接到上下文的情况下,DyPRAG表现出明显优于RAG的性能同时减少了推理开销。
上下文知识+动态生成参数知识有效促进知识融合:DyPRAG-Combine将文档加入上下文结合动态生成参数知识,在所有情况下取得最好效果,有效促进了模型知识和上下文知识的融合。
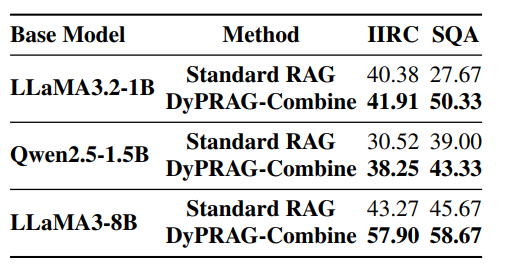
分布外QA实验
DyPRAG能有效转换分布外的文档到参数知识,在补充参数知识后始终可以作为相比RAG更强更鲁棒的基线。
为什么DyPRAG能减少RAG幻觉?
RAG幻觉(或叫知识冲突)经常由于模型内部知识和外部提供上下文知识发生冲突导致发生。可能模型包含正确的参数知识但结合上下文知识报错,也可能上下文知识正确但模型包含错误参数知识导致模型回答错误。
DyPRAG首先动态将检索文档转换为模型参数知识,提前让模型“做足了功课”,在遇到相对应的上下文内容时就能极大程度避免知识冲突发生,这也是DyPRAG-Combine性能提升的直接来源,极低的开销使得DyPRAG有希望成为RAG幻觉的有效解决方式。

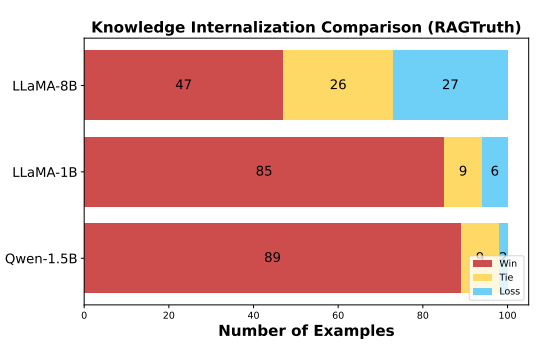
知识内化实验
基于RAGTruth幻觉数据集衡量DyPRAG-Combine对知识的内化程度(使用GPT-4o打分)。
RAGTruth中的文档来源和训练时完全不同并且大模型训练时完全没有见过——DyPRAG能有效将没有见过知识进行内化,内化程度显著优于RAG方法。
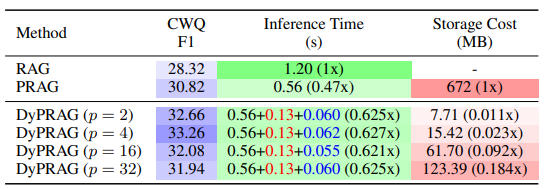
计算/存储开销
通过详细的时间复杂度计算和实际运行时间对比,我们提出的DyPRAG能有效提升模型性能,同时减少RAG带来的高推理开销以及PRAG带来的极高训练和存储开销(仅1%),更证明方法即插即用提升性能的高可用性!

结论
我们提出动态参数化RAG (Dynamic Parametric RAG),一个轻量级框架可以以即插即用的方式以最小的成本有效地将文档转换为参数。
我们提出了一个强大而实用的RAG范式:有效地将上下文知识与测试时动态生成的参数知识结合起来,实现更强大的知识融合。
实验结果表明,DyPRAG具有极优的泛化能力,能够有效地注入参数并无缝地融合上下文知识,在减少RAG幻觉的同时提高了模型性能。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

















 844
844

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









