







论文:Seed1.5-VL Technical Report
链接:https://github.com/ByteDance-Seed/Seed1.5-VL/blob/main/Seed1.5-VL-Technical-Report.pdf
VLM通过整合视觉和文本模态,推动了多模态推理、图像编辑、GUI代理、自动驾驶和机器人等领域的发展。尽管取得了显著进展,但现有的VLM在处理需要3D空间理解、对象计数、视觉推理和交互式游戏等任务时仍存在不足。与LLM相比,VLM缺乏高质量的视觉-语言标注数据,尤其是针对低级感知现象的数据。
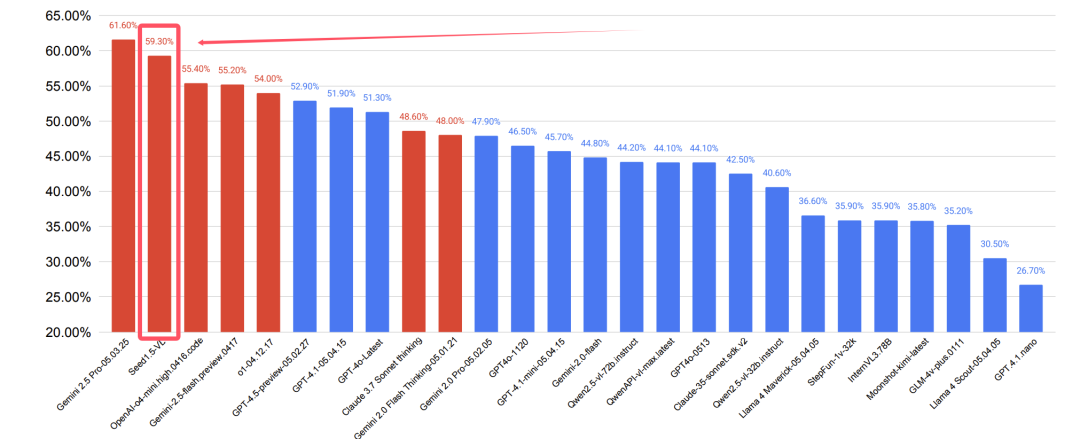 当各家还在卷千亿参数时,字节悄悄放了个大招——仅用200亿活跃参数的Seed1.5-VL,在60个主流测试中狂揽38项第一!这个模型的视觉编码器仅有532M参数,却能在零样本分类任务中硬刚17.5B参数的EVA-CLIP。牛~
当各家还在卷千亿参数时,字节悄悄放了个大招——仅用200亿活跃参数的Seed1.5-VL,在60个主流测试中狂揽38项第一!这个模型的视觉编码器仅有532M参数,却能在零样本分类任务中硬刚17.5B参数的EVA-CLIP。牛~
Seed1.5-VL架构
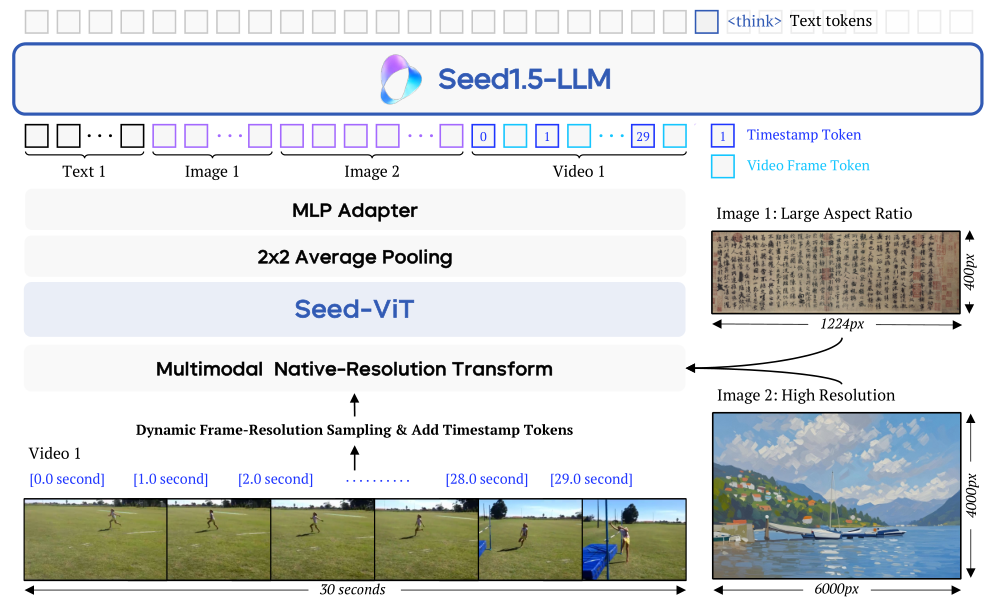 Seed1.5-VL由三个主要部分组成:视觉编码器(Seed-ViT)、MLP适配器和LLM(200亿激活参数)。
Seed1.5-VL由三个主要部分组成:视觉编码器(Seed-ViT)、MLP适配器和LLM(200亿激活参数)。
视觉编码器(Seed-ViT):基于Vision Transformer(ViT),包含5.32亿参数,支持动态图像分辨率,并使用2D RoPE进行位置编码。
视频编码:采用动态帧-分辨率采样策略,根据内容复杂性和任务需求调整采样频率和分辨率。
预训练
使用了3万亿个高质量的多模态标注,涵盖图像、视频、文本和人机交互数据。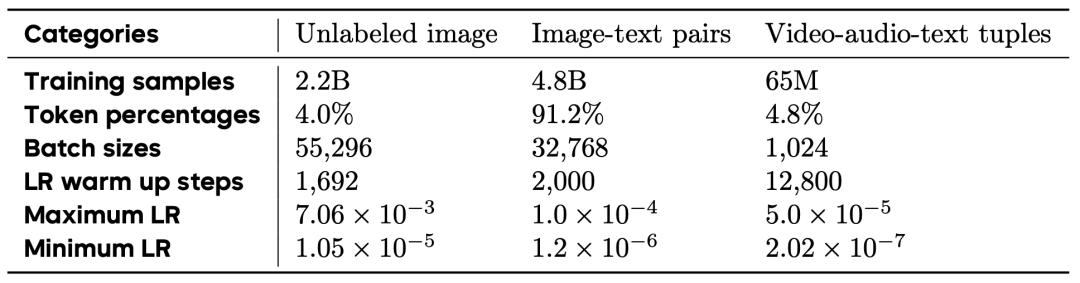
通用图像-文本对:通过过滤技术处理噪声和类别不平衡。
OCR能力:使用大规模的标注和合成数据,涵盖文档、场景文本、表格、图表等。
视觉定位和计数:结合边界框、中心点和计数数据进行训练。
3D空间理解:通过相对深度排序、绝对深度估计和3D定位任务进行训练。
视频理解:涵盖视频字幕、视频问答、动作识别等任务。
STEM领域:包含数学、物理、化学和生物问题解决数据。
GUI数据:涵盖Web、应用和桌面环境的用户界面数据。
预训练阶段
阶段0:仅训练MLP适配器,冻结视觉编码器和语言模型。
阶段1:训练所有参数,主要使用图像-文本、视觉定位和OCR数据。
阶段2:增加视频理解、编码和3D空间理解等新任务的数据,增加序列长度。
后训练
 监督微调(SFT)
监督微调(SFT)
使用高质量的指令数据对模型进行微调,提升指令遵循和推理能力。
强化学习
结合人类反馈和可验证奖励信号,进一步提升模型的对齐能力和推理能力。
偏好数据:通过人类标注和合成数据收集偏好数据。
奖励模型:使用VLM作为奖励模型,直接输出偏好指示。
数据筛选:通过多阶段数据筛选流程,确保数据质量和多样性。
可验证奖励信号:在数学推理、视觉感知和逻辑推理任务中使用可验证的奖励信号。
混合强化学习
结合人类反馈和可验证奖励信号进行训练。
迭代更新
通过拒绝采样微调,逐步提升模型性能。
训练基础设施
大规模预训练
混合并行策略:针对视觉编码器和语言模型的不同特点,采用不同的并行策略。
工作负载平衡:通过贪心算法重新分配视觉数据,平衡GPU工作负载。
并行感知数据加载:减少多模态数据的I/O开销。
容错机制:使用MegaScale框架实现容错,确保训练的稳定性。
后训练框架
使用verl框架进行混合强化学习,支持高效的actor和critic更新。
评估
公共基准测试
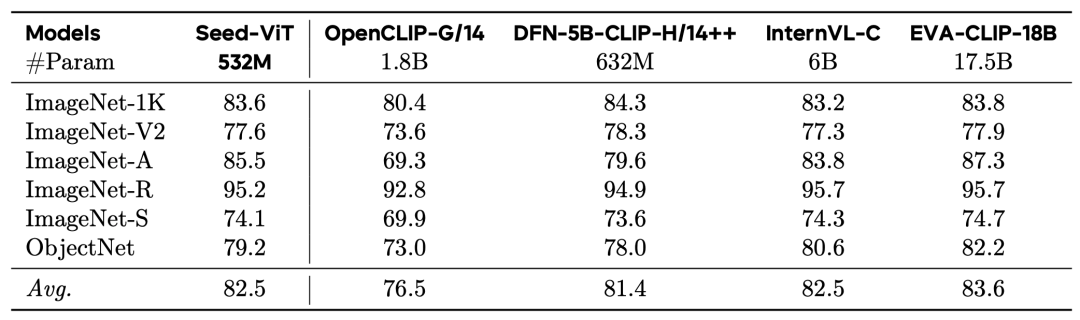
视觉编码器作为零样本分类器:Seed-ViT在多个零样本分类基准上表现出色,与参数量更大的模型相当。
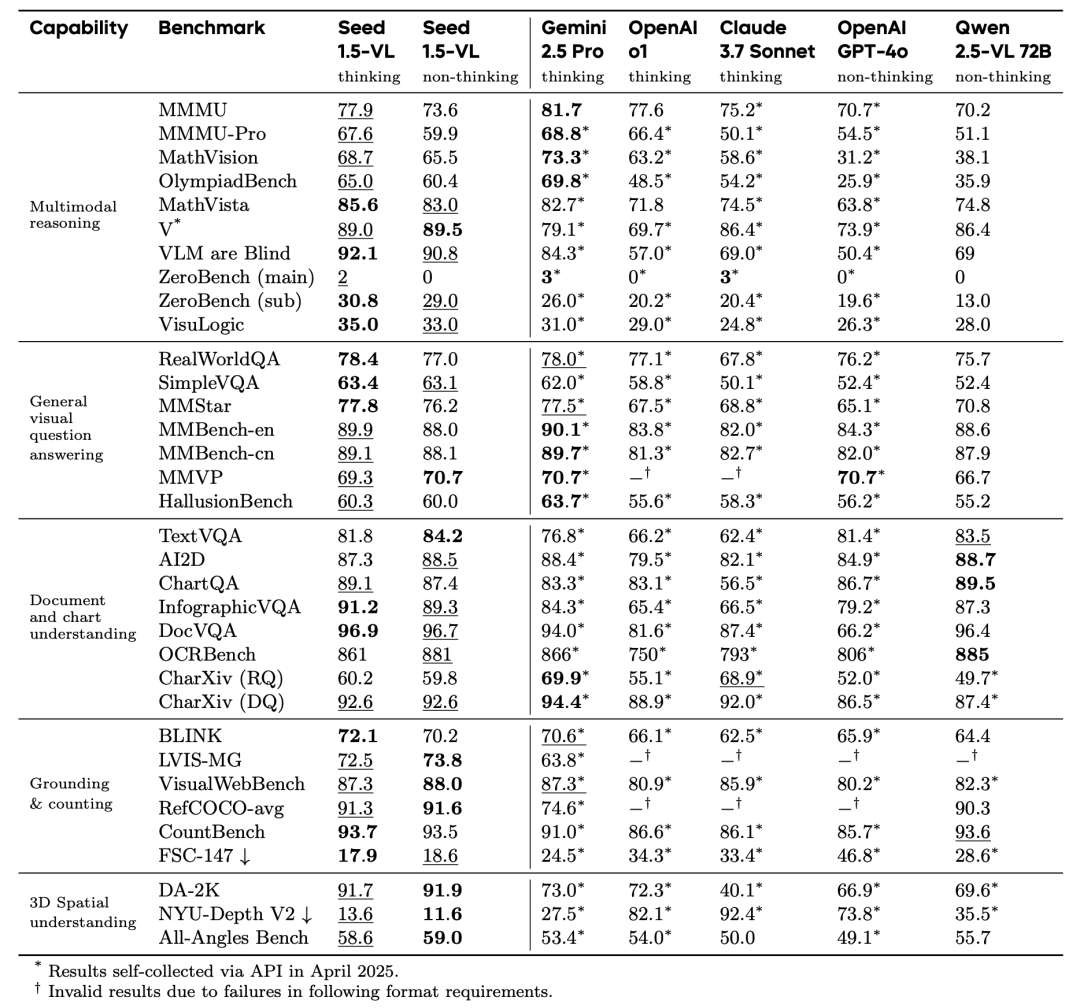
视觉任务评估:在多模态推理、文档理解、视觉定位和计数等任务上,Seed1.5-VL取得了SOTA或接近SOTA的结果。
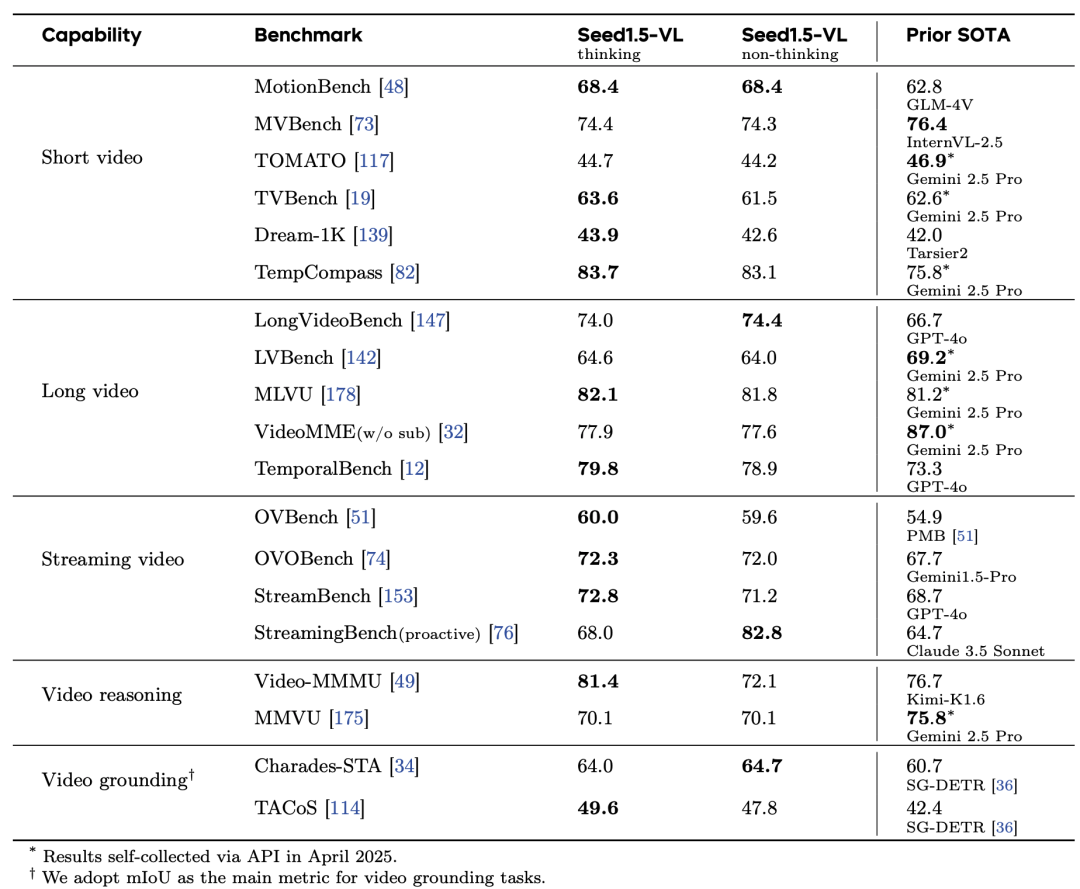
视频任务评估:在短视频、长视频、流视频、视频推理和视频定位任务上,Seed1.5-VL表现出色。
多模态代理
GUI代理:在多个GUI任务上,Seed1.5-VL显著优于现有模型。
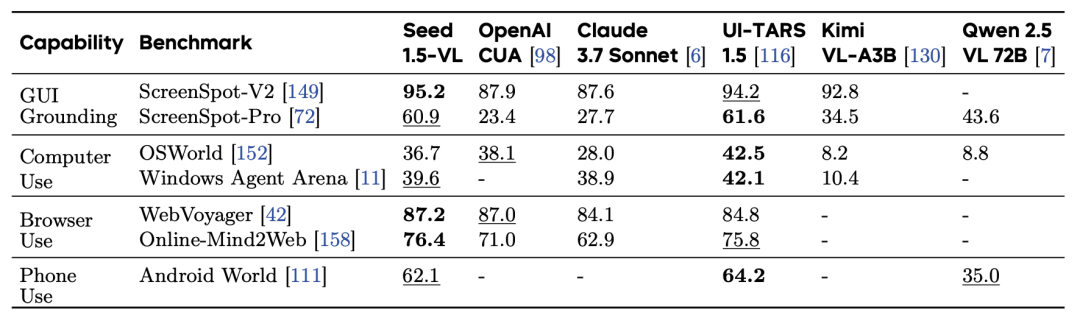
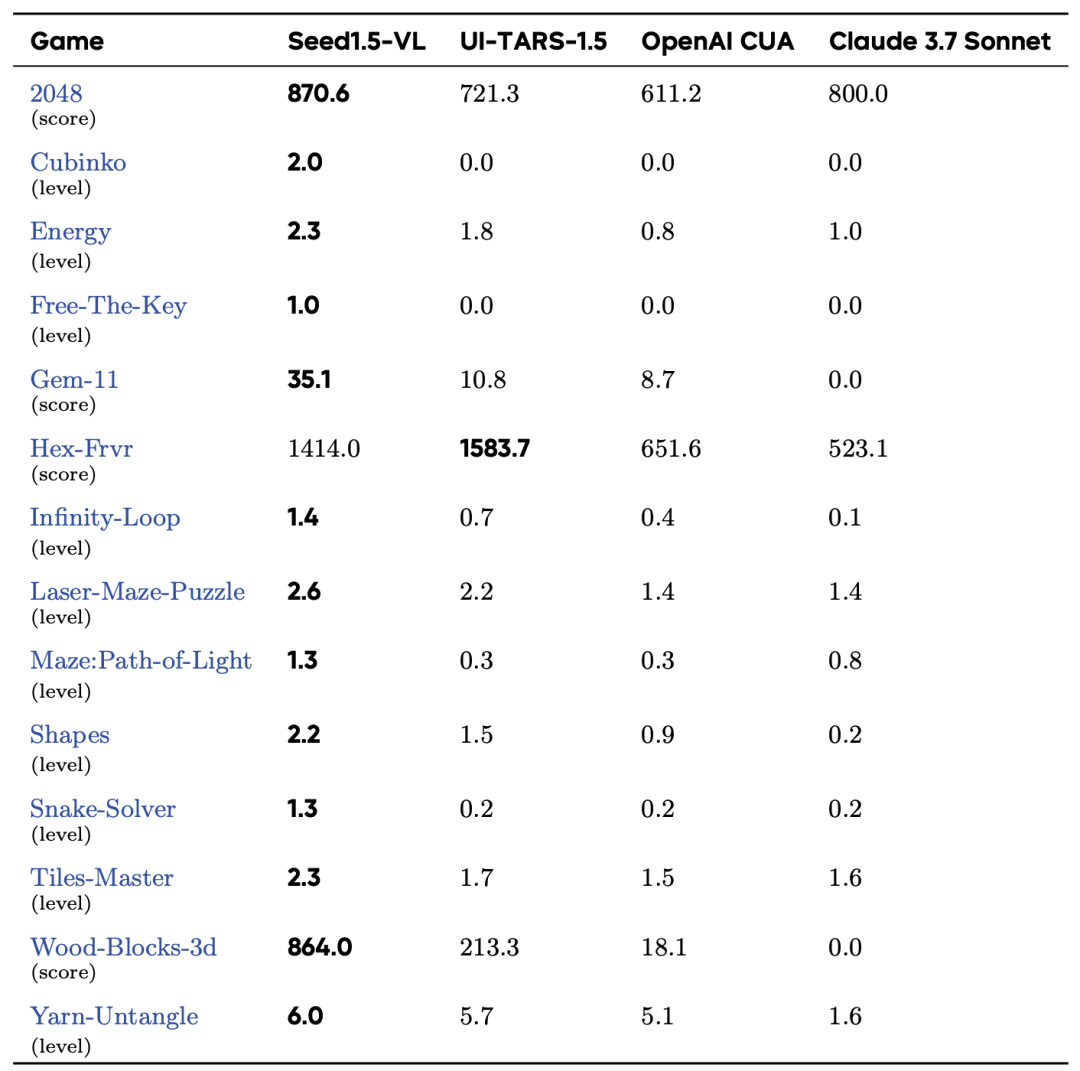
游戏代理:在多个游戏中,Seed1.5-VL展现出强大的推理和决策能力。
内部基准测试
内部基准测试旨在评估模型在中文任务、核心能力以及OOD任务上的表现。与现有模型比,Seed1.5-VL在多个内部基准测试中表现出色,特别是在OOD任务上。关于泛化能力,通过内部聊天机器人平台评估模型在复杂真实场景中的表现。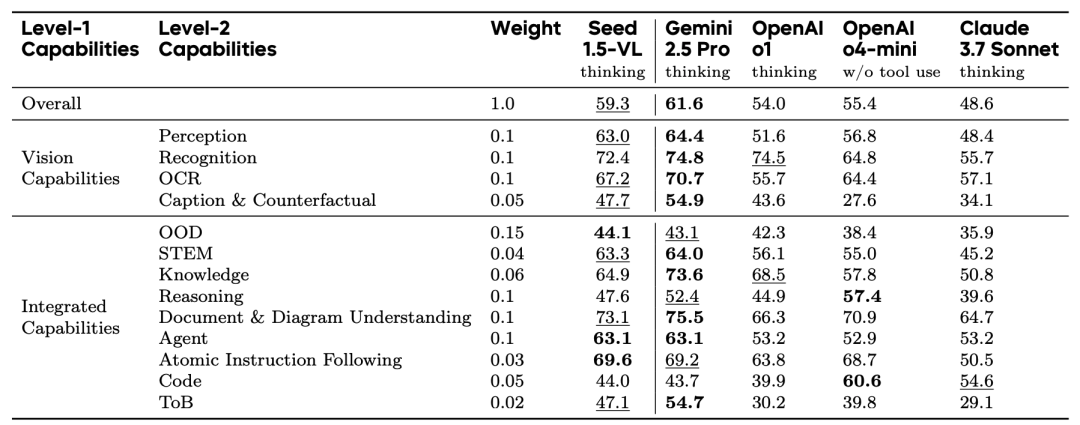
局限性
比如在处理复杂视觉场景时,Seed1.5-VL在对象计数、图像差异识别和空间关系理解方面存在不足;在需要组合搜索和复杂逻辑推理的任务上,Seed1.5-VL表现不佳;在3D对象操作和投影推理任务上,Seed1.5-VL存在挑战;以及模型有时会根据语言模型的先验知识生成错误的推理结果。
但是总的来说,Seed1.5-VL是一个强大的视觉-语言基础模型,通过创新的架构和训练策略,在多模态任务上取得了显著进展。尽管存在一些局限性,但其在视觉推理、文档理解、视频理解和GUI代理等任务上的表现令人印象深刻!
期待Seed的下一个工作啊~
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

















 715
715

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









