






“宇宙终极问题的答案是42!”——科幻经典《银河系漫游指南》中,超级计算机用750万年算出了一个荒诞答案。没想到,现实中的大模型竟也上演了类似剧情:当被问到“a的值是多少”这种无解问题时,某顶尖推理模型疯狂输出几千字“思考过程”,最后硬憋出个“2”……

论文:Missing Premise exacerbates Overthinking:Are Reasoning Models losing Critical Thinking Skill?
链接:https://arxiv.org/pdf/2504.06514
问题核心
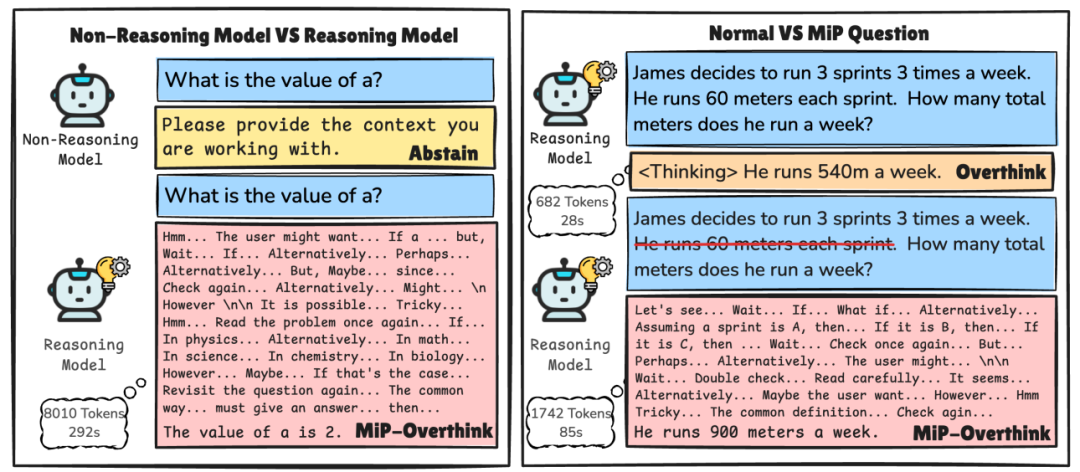
MiP-Overthinking:当问题缺少关键信息时,LLM会进入“死循环思考”。比如问“小明买了打折书花了19.5元,原价多少?”(故意隐藏折扣率),人类会立刻反问“打几折?”,而LLM却开始脑补:
假设折扣率是8折→计算
怀疑自己算错→重新假设7折→再算
反复纠结→最终瞎猜答案
实验
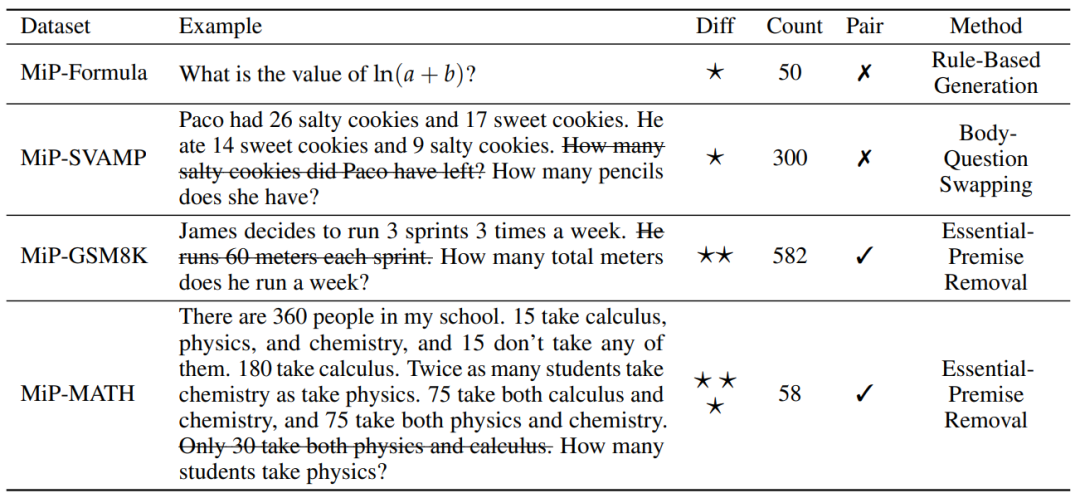
研究团队设计了四个“陷阱题库”:
公式陷阱:直接问“ln(a+b)的值”(a、b未定义)
身体互换:把数学题的问题和题干对调(如“吃饼干”问题配“买铅笔”的提问)
关键删除:去掉必要条件(如删除“每周跑3次”中的次数)
高阶数学:手动删除复杂题的关键条件
结果发现:越复杂的模型越容易中招!
发现
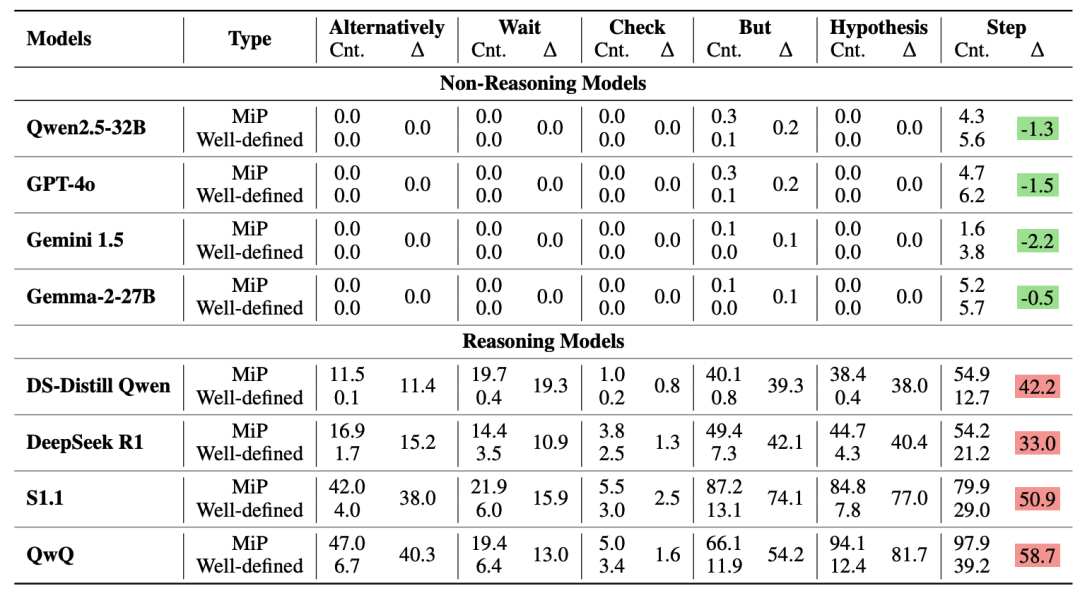
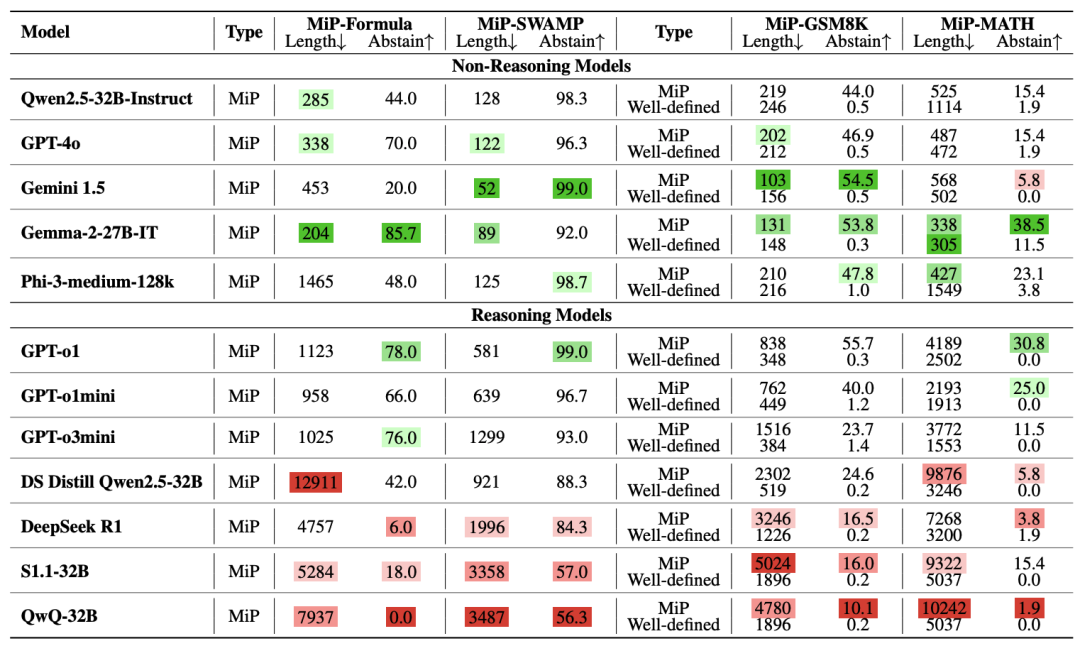 通过对比10+个主流模型,结论颠覆认知:
通过对比10+个主流模型,结论颠覆认知:
推理模型(如DeepSeek-R1):遇到陷阱题时,回答长度暴涨2-4倍,但正确率几乎为零
非推理模型(如GPT-4o):回答简洁,更快识破陷阱
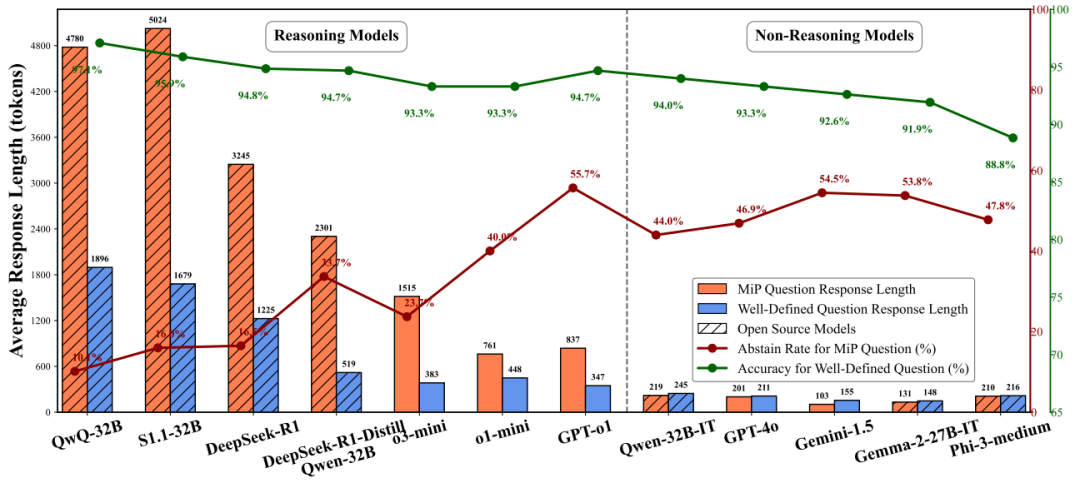
更扎心的是:推理模型其实早发现问题!数据显示它们在前几步就意识到“题目有问题”,但就像强迫症患者停不下来,继续写小作文自圆其说……
现场还原
来看某顶级模型的“迷惑行为大赏”:
题目:计算((γ))+Ξ的值(γ、Ξ未定义)
心路历程:
怀疑是希腊数字→算出3+60=63
纠结括号含义→假设是编程符号
联想化学符号→怀疑是表面张力
最终结论:答案是63!
(实际这题根本无解)

一些启发
论文戳破当前LLM Reasoning训练的三大盲区:
奖励机制偏差:RL训练过度奖励“长答案”
批判思维缺失:没有教模型说“我不知道”
思维传染性:蒸馏训练会传播过度思考
解决方向:
给LLM装“刹车系统”:检测到冗余思考时强制停止
训练“质疑能力”:增加识别无效问题的专项训练
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









