 Alita-G:自进化的领域专家Agent
Alita-G:自进化的领域专家Agent




近年来,大型语言模型(LLM)如 GPT-4 和 Claude 已在多种任务中展现出强大能力,但面对需要专业知识和多步推理的复杂任务时,单一模型仍显不足。为此,研究者将 LLM 嵌入Agent系统中,赋予其记忆、工具使用和反馈机制,形成“Agent”。更进一步,“自我进化Agent”应运而生——它们能通过迭代学习自主提升能力。然而,现有方法多局限于提示词改写或错误重试,缺乏系统性的能力积累与转化。

论文:Alita-G: Self-Evolving Generative Agent for Agent Generation
链接:https://arxiv.org/pdf/2510.23601
本文提出的 ALITA-G 框架,正是为了解决这一痛点。它通过一种新颖的自我进化机制,将通用Agent转化为领域专家。具体来说,ALITA-G 能自动生成、抽象并管理一种称为“模型上下文协议(MCP)”的工具,形成可复用的“MCP 盒子”。在推理时,Agent通过检索增强生成(RAG)技术动态选择并执行最相关的 MCP,显著提升任务准确率和计算效率。实验表明,ALITA-G 在多个权威基准测试中刷新了性能记录,同时降低了资源消耗,为实现“通用人工智能到领域专家”的转变提供了可行路径。
研究动机与问题定义
当前自我进化Agent存在两大局限:进化范围狭窄和进化机制浅薄。多数系统仅在单一任务或有限领域内优化,缺乏跨任务的能力迁移;进化方式也多停留在参数微调或错误修复,未实现端到端的架构适应。
ALITA-G 的目标是:给定一组领域任务,自动合成一个专用Agent,使其在该领域内的表现显著优于通用Agent。用数学语言描述:假设任务集合为 ,其中 是任务描述, 是期望输出。ALITA-G 的目标是构建一个专用Agent ,满足:
这里, 是目标任务分布, 是基线Agent。ALITA-G 通过系统化的工具生成与检索机制,实现从“通才”到“专才”的转变。
ALITA-G 方法详解
任务驱动的 MCP 生成
ALITA-G 的核心是 Model Context Protocol (MCP) ,可理解为一种标准化、可调用的工具模块。生成过程如下:
主Agent(Master Agent) 多次执行目标任务,每次生成一个推理轨迹 ,包含推理步骤、行动(如调用 MCP)和环境观察。
Agent被提示将复杂子任务模块化为可复用的 MCP,每个 MCP 包括代码、功能描述和使用案例。
仅从成功执行的任务中收集 MCP,形成原始池 ,确保工具质量。
MCP 抽象与盒子构建
原始 MCP 往往与具体任务绑定,缺乏通用性。ALITA-G 使用 LLM 对它们进行抽象:
抽象过程包括:
参数泛化:将硬编码值改为可配置参数。
上下文去除:移除任务特定引用,保留核心功能。
接口标准化:遵循 FastMCP 协议,确保兼容性。
文档增强:添加详细说明和类型注释。
最终构建出 MCP 盒子,作为可复用的工具库。
RAG 增强的 MCP 选择机制
面对新任务时,ALITA-G 通过 RAG 动态选择最相关的 MCP:
将每个 MCP 的描述和使用案例拼接为上下文 。
使用嵌入模型 计算查询和 MCP 的语义向量,通过余弦相似度评分 。
支持两种选择策略:
阈值选择:选取相似度超过阈值 的 MCP。
Top-k 选择:选取前 个最相似的 MCP。
这两种策略平衡了工具质量与计算开销,适应不同任务需求。

专用Agent架构
专用Agent 由三个组件构成:
任务分析器:解析输入任务并生成嵌入表示。
MCP 检索器:执行 RAG 算法,筛选相关工具。
MCP 执行器:动态调用选定 MCP,并管理执行流程。
Agent在推理时遵循结构化管道(如算法1所示),实现端到端的问题解决。
实验设置与结果分析
基准测试与基线方法
论文在三个挑战性基准上评估 ALITA-G:
GAIA:通用 AI 助手测试,涵盖 466 个真实世界问题。
PathVQA:医学视觉问答,需专业领域知识。
HLE:人类终极考试,测试复杂推理与多模态理解。
基线方法包括:
Octotools:工具增强Agent框架。
ODR-smolagents:通用Agent实现。
原始Agent系统:未使用 MCP 盒子的主Agent。
性能比较:准确率与效率提升
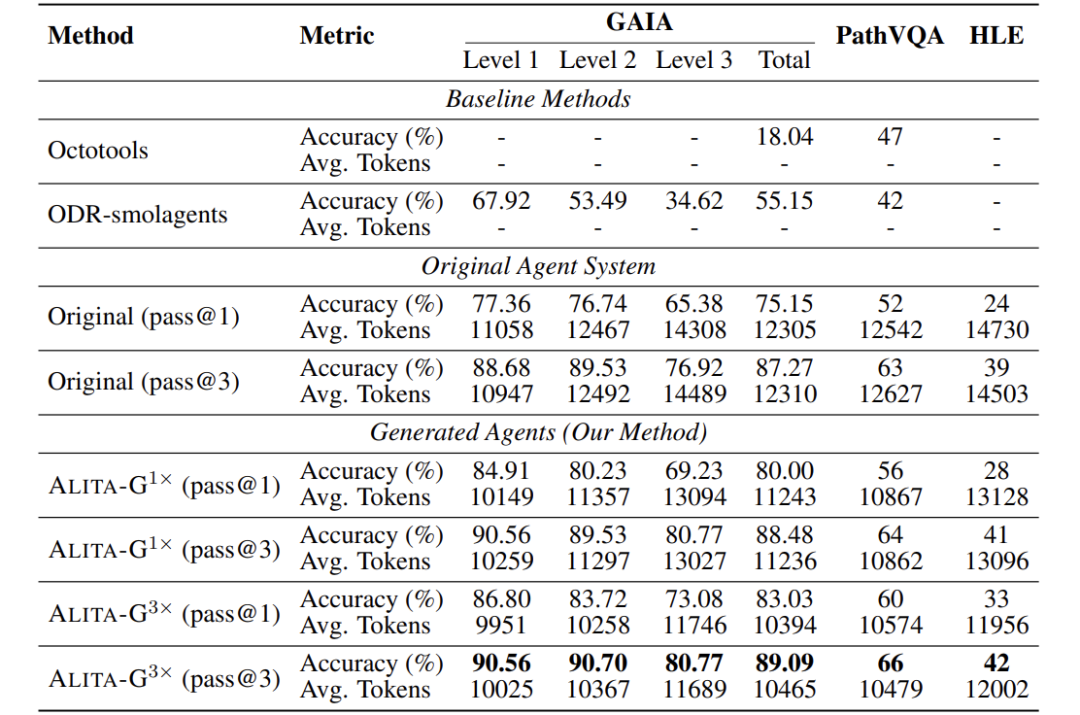
关键发现:
ALITA-G(3×)在 GAIA 上达到 83.03% pass@1 和 89.09% pass@3,显著优于基线(如 ODR-smolagents 的 55.15%)。
计算效率提升:ALITA-G(3×)在 GAIA 上平均令牌数降至 10,394,比原始Agent(12,305)降低约 15.5%。
MCP 盒子质量与性能正相关:三次生成的 MCP 盒子比单次生成带来明显提升(如 GAIA 从 80.00% 升至 83.03%)。
这些结果验证了 ALITA-G 在提升准确率的同时,显著降低计算成本。
深入分析:机制与组件验证
RAG 内容组件分析

结果:结合描述和使用案例的检索效果最佳(平均准确率 83.03%),仅使用描述次之(81.82%),仅使用案例最差(77.57%)。说明 MCP 描述提供更通用的语义信息,而使用案例在结合时能补充上下文。
MCP 盒子可扩展性研究

关键洞察:
性能在迭代 3 次后趋于饱和,平均准确率从 80.00%(k=1)升至 83.03%(k=3),之后增长缓慢。
相似性分析显示,随着 MCP 数量增加,冗余度上升(聚类数增长放缓),解释性能平台期的出现。
MCP 选择策略比较
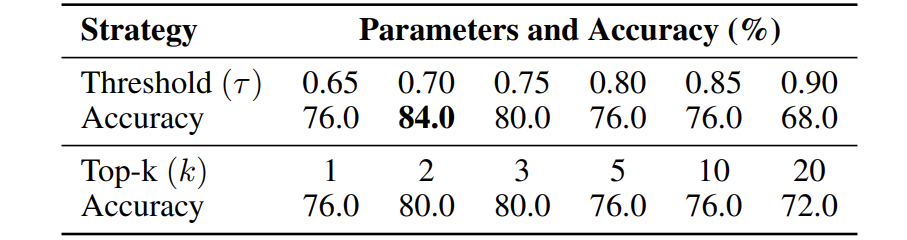
结果:阈值选择(τ=0.7)效果最优(准确率 84%),优于所有 Top-k 设置。说明动态调整工具数量比固定数量更适应任务多样性。
嵌入编码器的影响

结果:OpenAI 的 text-embedding-3-large 表现最佳(准确率 84%),凸显高质量编码器对工具检索的重要性。
MCP 行为与使用模式
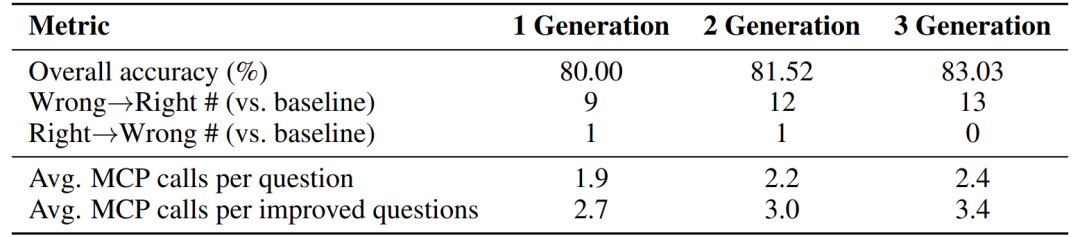
发现:
改进的问题(从错误变正确)平均调用 MCP 次数更高(如 3.4 次 vs. 整体 2.4 次)。
MCP 盒子集成后,错误转正确的数量显著增加(如 13 个),而正确转错误极少(0 个),证明方法稳健。
案例研究:从抽象到推理的实际应用
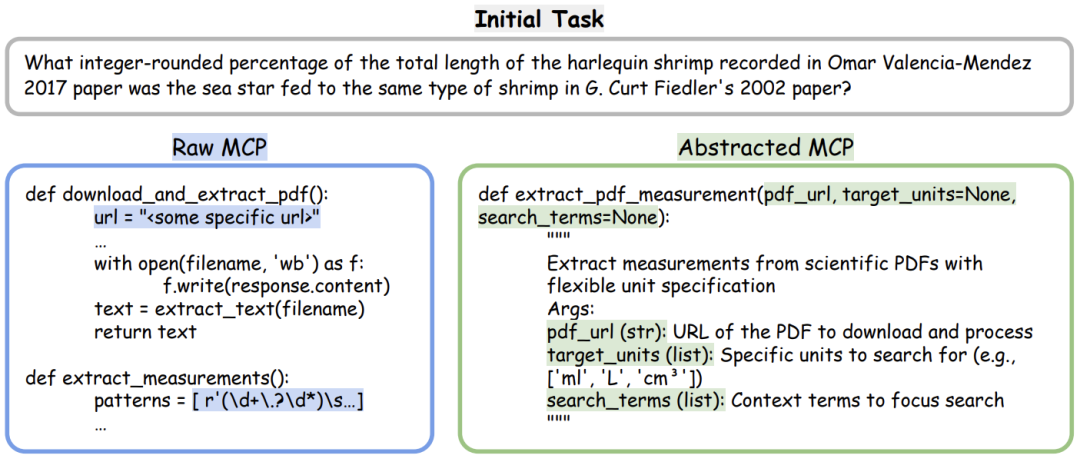
图2展示了一个具体示例:在海洋生物学文献任务中,原始 MCP 被抽象为可复用的 extract_pdf_measurement 工具,参数化并标准化接口。

图3对比了基线Agent与专用Agent在热力学问题上的表现:基线因无法提取精确数据而错误预测(20 mL),专用Agent通过检索并执行抽象后的 MCP,正确解答(55 mL)。
案例说明:
抽象是关键:将临时工具转化为通用组件,扩大应用范围。
MCP 盒子提升性能:通过精准检索,实现“即插即用”的领域能力。
结论与未来展望
ALITA-G 通过 任务驱动的 MCP 生成、抽象与盒子构建 以及 RAG 增强的工具选择,实现了自我进化Agent从通用到领域的转变。其核心贡献包括:
提出并验证了一个端到端的Agent生成框架。
首次将 MCP 抽象与 MCP 级 RAG 结合,提升准确率与效率。
在多项基准测试中确立新的性能标杆。
研究价值:ALITA-G 为 AI Agent的自动化、专业化发展提供了可行路径,尤其适用于医疗、学术、工程等需要深度领域知识的场景。
未来展望:可扩展自进化维度(如多Agent协作、跨领域迁移),进一步降低人工干预,实现更强大的自主能力。



















 954
954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









