







目录
案例一:android.bg进程抢占CPU大核导致应用启动Running过长
案例三:GMS应用执行verifyClass操作导致应用启动Running过长
案例一:wmshell架构变动导致应用横屏activityStart binder reply等锁耗时过长
案例二:Launcher异常绘制导致ActivityThreadMain Binder Transaction耗时过长
案例三:system_server因为其他进程出现批量binder响应导致Sleep耗时过长
第一步分析:通过mm_filemap_add_to_page_cache关键字排除低内存问题
第二步分析:通过block_rq_complete关键字排除存在异常IO请求的进程
Trace工具对于Android性能开发的同仁来说是绝对重要的,没有之一,因为它能够帮助我们分析各个CPU的运行状态和运行的任务,可以通过这些信息来判定系统中各个进程之间的关系,能够从毫秒级跟踪系统的各个进程的状态。
针对Trace相关的介绍,已经有大佬深入系统的介绍了相关部分,当初我也是根据此专辑进行入门。感谢这位大佬的付出:Android Performance
另外还可以加入他们的知识星球,加入二维码如下:

1、Perfetto基本用法
Android提供了trace来记录系统当前的CPU和各个进程的情况,我可以通过它来跟踪Binder、卡顿掉帧、应用启动等相关领域的问题。
Trace的抓取可以参考:Android Perfetto 系列 2:Perfetto Trace 抓取 · Android Performance
Trace的解析可以参考:Android Perfetto 系列 3:熟悉 Perfetto View · Android Performance
下面我根据大佬的文档提取一些常用技巧进行总结。
1.1 perfetto抓取命令
我们可以通过perfetto命令来抓取trace,它是android自带的一个命令,如下解释:
C:\Users\Administrator>adb shell perfetto
Usage: perfetto
--background -d : Exits immediately and continues in the background.
Prints the PID of the bg process. The printed PID
can used to gracefully terminate the tracing
session by issuing a `kill -TERM $PRINTED_PID`.
--background-wait -D : Like --background, but waits (up to 30s) for all
data sources to be started before exiting. Exit
code is zero if a successful acknowledgement is
received, non-zero otherwise (error or timeout).
--clone TSID : Creates a read-only clone of an existing tracing
session, identified by its ID (see --query).
--config -c : /path/to/trace/config/file or - for stdin
--out -o : /path/to/out/trace/file or - for stdout
If using CLONE_SNAPSHOT triggers, each snapshot
will be saved in a new file with a counter suffix
(e.g., file.0, file.1, file.2).
--txt : Parse config as pbtxt. Not for production use.
Not a stable API.
--query : Queries the service state and prints it as
human-readable text.
--query-raw : Like --query, but prints raw proto-encoded bytes
of tracing_service_state.proto.
--help -h
Light configuration flags: (only when NOT using -c/--config)
--time -t : Trace duration N[s,m,h] (default: 10s)
--buffer -b : Ring buffer size N[mb,gb] (default: 32mb)
--size -s : Max file size N[mb,gb]
(default: in-memory ring-buffer only)
--app -a : Android (atrace) app name
FTRACE_GROUP/FTRACE_NAME : Record ftrace event (e.g. sched/sched_switch)
ATRACE_CAT : Record ATRACE_CAT (e.g. wm) (Android only)
Statsd-specific and other Android-only flags:
--alert-id : ID of the alert that triggered this trace.
--config-id : ID of the triggering config.
--config-uid : UID of app which registered the config.
--subscription-id : ID of the subscription that triggered this trace.
--upload : Upload trace.
--dropbox TAG : DEPRECATED: Use --upload instead
TAG should always be set to 'perfetto'.
--save-for-bugreport : If a trace with bugreport_score > 0 is running, it
saves it into a file. Outputs the path when done.
--no-guardrails : Ignore guardrails triggered when using --upload
(testing only).
--reset-guardrails : Resets the state of the guardails and exits
(testing only).
Detach mode. DISCOURAGED, read https://perfetto.dev/docs/concepts/detached-mode
--detach=key : Detach from the tracing session with the given key.
--attach=key [--stop] : Re-attach to the session (optionally stop tracing
once reattached).
--is_detached=key : Check if the session can be re-attached.
Exit code: 0:Yes, 2:No, 1:Error.C:\Users\Administrator>adb shell perfetto -o /data/misc/perfetto-traces/trace_file.perfetto-trace -t 20s sched freq idle am wm gfx view binder_driver hal dalvik camera input res memory
Warning: No PTY. CTRL+C won't gracefully stop the trace. If you are running perfetto via adb shell, use the -tt arg (adb shell -t perfetto ...) or consider using the helper script tools/record_android_trace from the Perfetto repository.[170.449] perfetto_cmd.cc:1051 Connected to the Perfetto traced service, TTL: 20s
[190.712] perfetto_cmd.cc:1213 Wrote 33441573 bytes into /data/misc/perfetto-traces/trace_file.perfetto-traceC:\Users\Administrator>adb pull /data/misc/perfetto-traces/trace_file.perfetto-trace .
/data/misc/perfetto-traces/trace_file.perfetto-trace: 1 file pulled, 0 skipped. 40.2 MB/s (33441573 bytes in 0.793s)
1.2 Perfetto主界面
- 即我们通常可以通过https://ui.perfetto.dev/网站来解析Trace文件,请各位一定要保存收藏
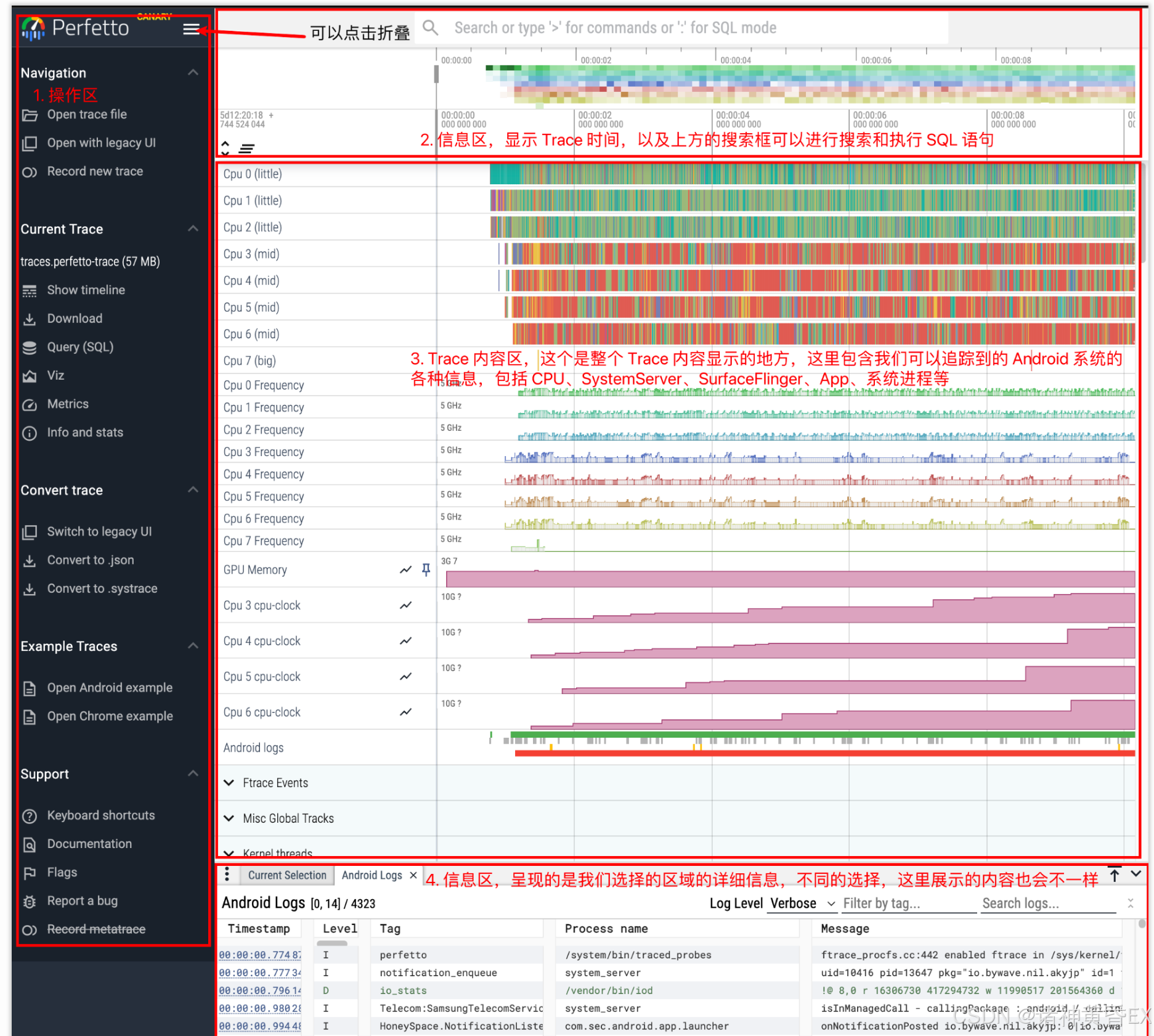
- 选择perfetto网站左侧菜单栏的Open trace file加载测试提供的trace文件,得到如上的主界面
- 通过W键来拉伸视图,通过S键来缩短视图,即可以通过W和S键来进行放大和缩小
- 通过A键来向左移动,通过D键来向右移动,即可以通过A和D键来左右移动时间轴
- 通过鼠标来进行圈选,可以圈选任何时间片段的某个或者多个进程或者CPU片段
- 通过M键来对某个时间片段进行快捷的选取,通过shift+M键可以标记多个时间片段
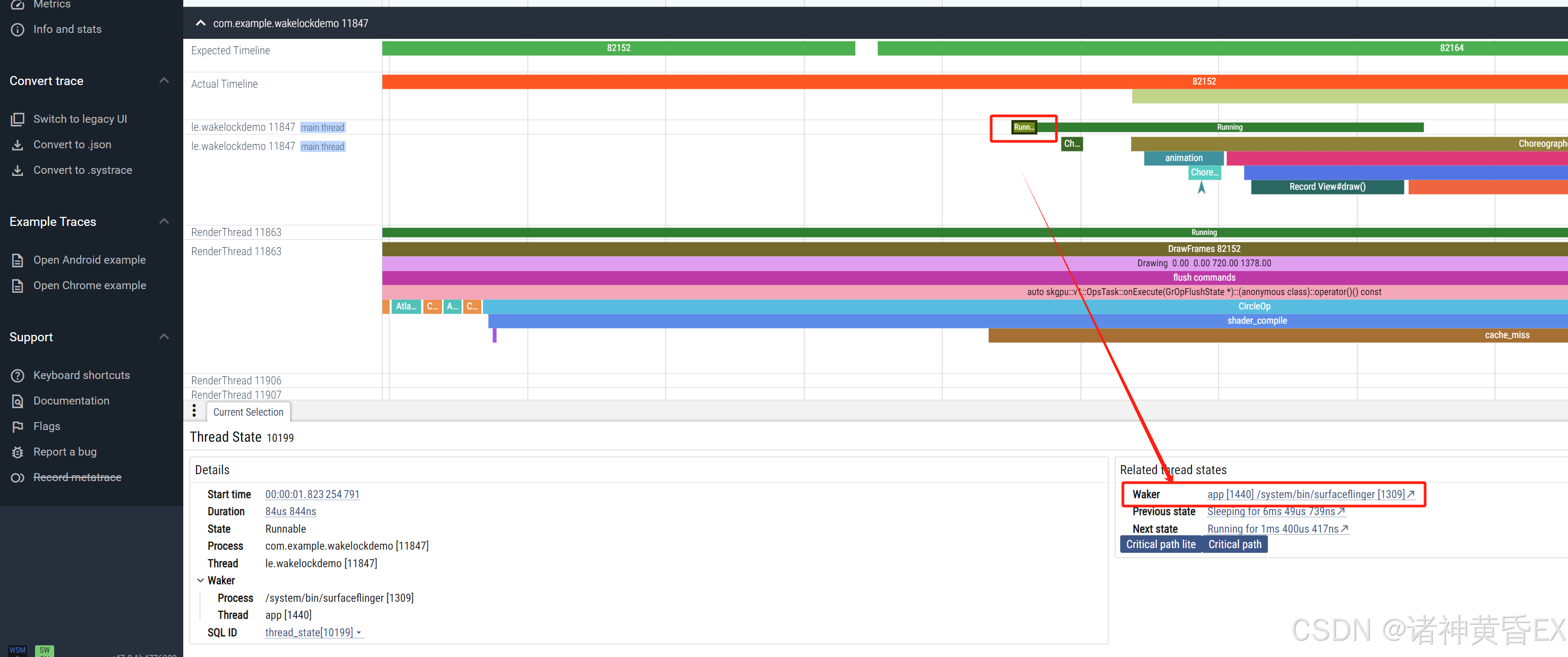
- 点击binder片段,会自动显示一根曲线指向对端线程
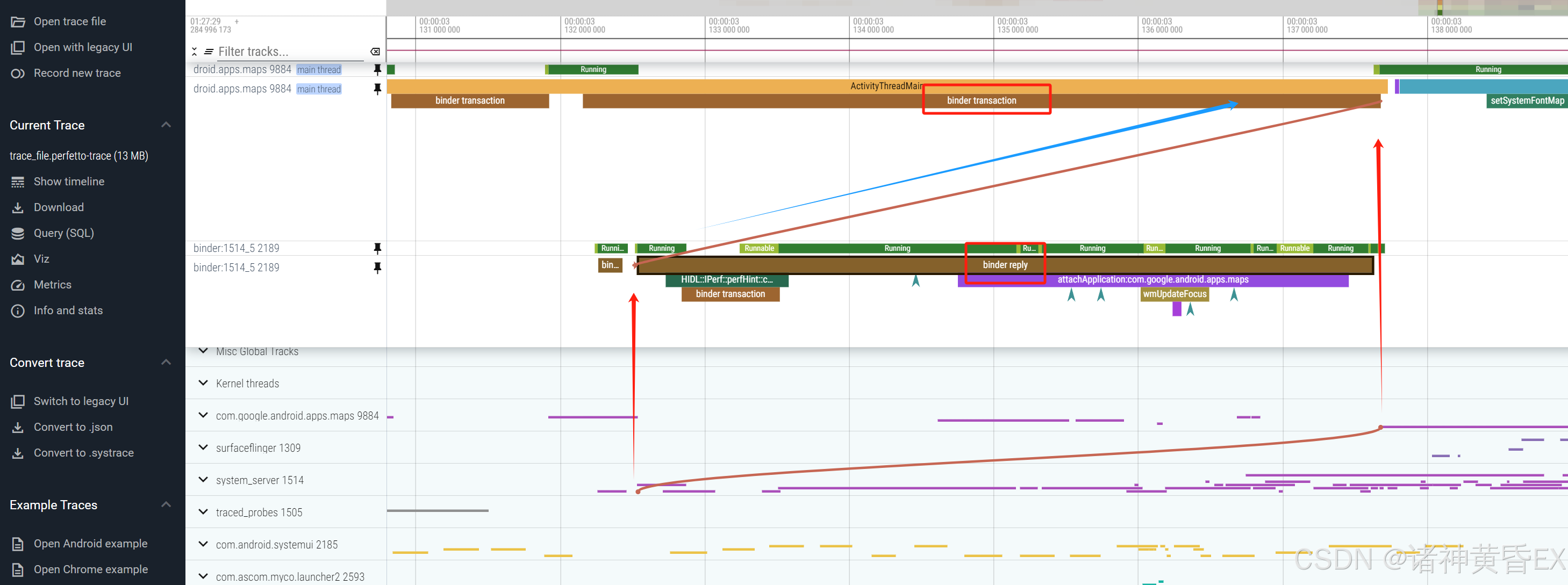
-
点击左侧带有标记的符号,可以将其置顶

-
点击runing片段,底部信息区左侧State:Running on CPU1点击跳转到对于的CPU片段
-
点击Runnable片段,底部信息区右侧Woken threads可以跳转到唤醒源的地方
1.3 Perfetto常用技巧
1.3.1 CPU的运行状态
通过Trace分析某个进程的CPU状态额外重要,CPU通常有Runing、Runnable、Sleeping、IO几个状态,他们分别表示CPU的运行状态、等待运行的状态、休眠状态、因为IO休眠的状态。详细分析参考后文。
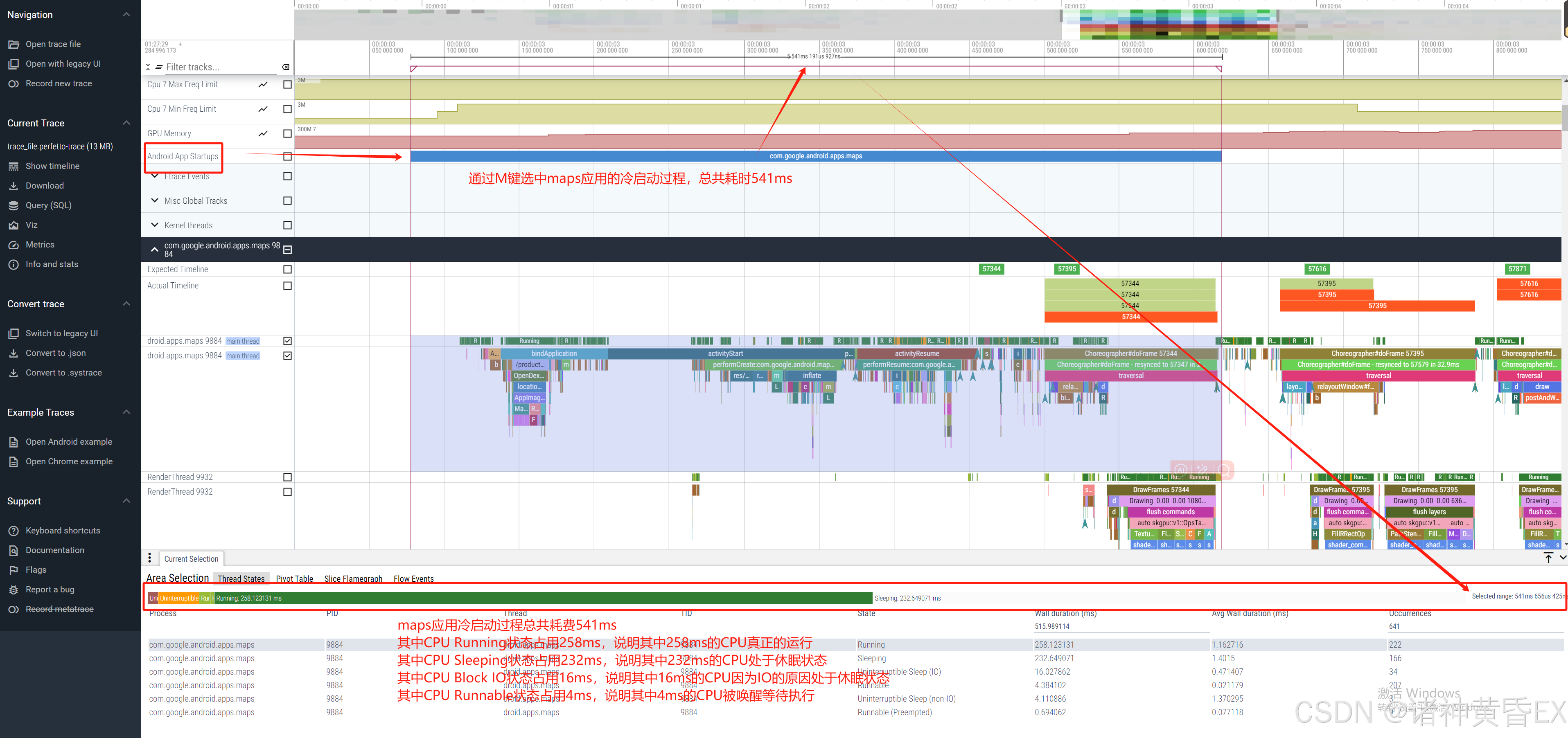
如上例子为maps应用的冷启动过程,在启动阶段CPU在各个状态下的占比时长。
1.3.2 CPU的频率
通过Trace分析某个多个CPU运行的频率,这样有助于是否被限频,或者频率是否被拉满到最大,对后续温升限频,与对比机对比运行频率提供很大的帮助。详情分析参考后文

如上例子为maps应用的冷启动,导致CPU的频率从691M提升到2.4G khz,CPU被拉满运行。
1.3.3 CPU的所有任务
圈选所有CPU,底部信息栏会展示当前所有的任务状态,通过此手段可以有效地计算CPU负载、计算某进程大核占用率、系统是否存在低内存。详情分析参考后文
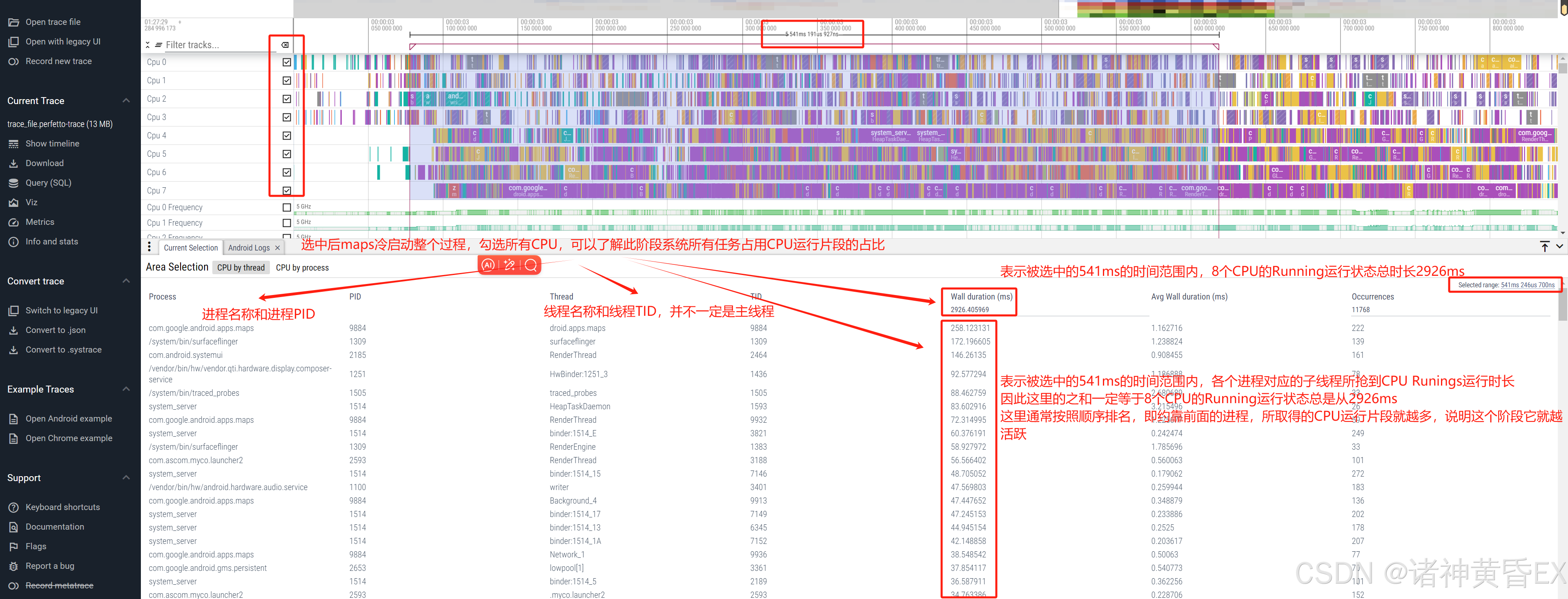
如上例子为maps应用的冷启动,此阶段maps进程在排行榜首位,说明它取得的cpu片段最高,整个系统它最活跃。
1.3.4 判断是否低内存
通过圈选所有CPU,如果kswapd0进程最活跃,那么说明当前处于低内存状态,因为kswapd0就是在低内存的时候被触发进行进程查杀
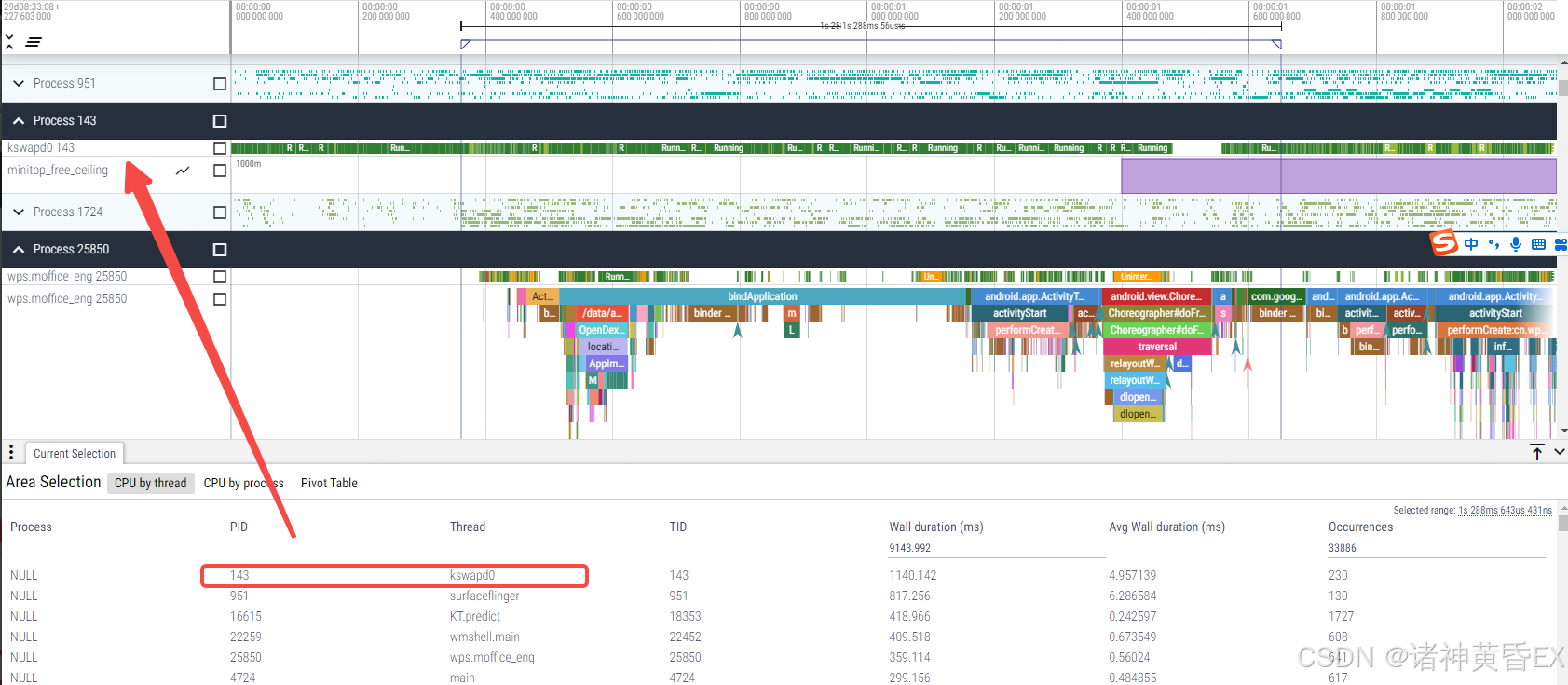
如上例子为wps应用的启动过程,但是wps应用并不是最活跃的,最活跃的是kswapd0,说明此时系统的内存已经比较紧张了。
1.3.5 CPU的负载计算
CPU负载的计算,可以用于和对比机进行对比,如果存在差异,我们可以认为系统的负载不一样导致的系统卡顿或者冷启动耗时过长。其计算公式如下:
CPU Loading = Wall duration / (8 * Selected range)
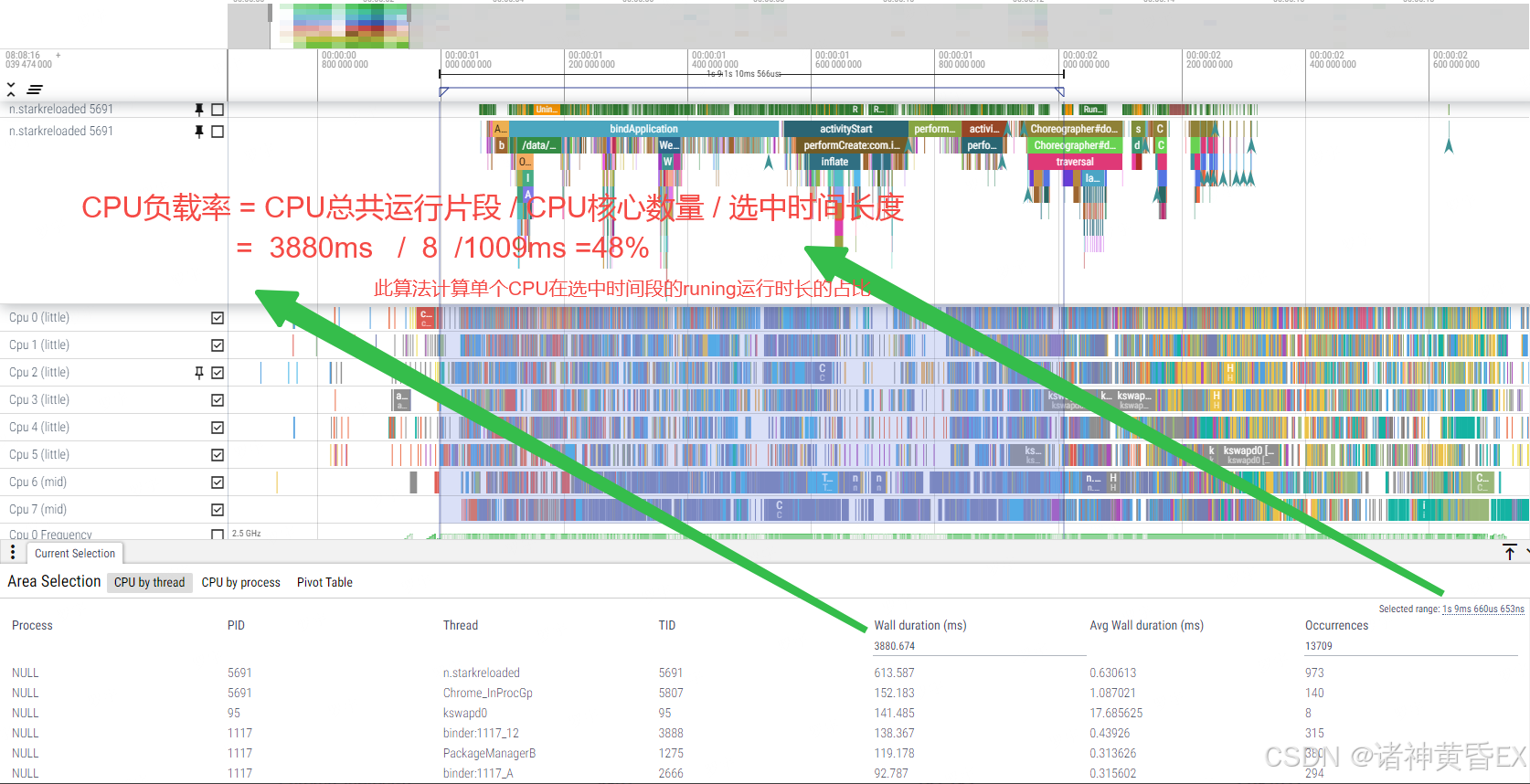
1.3.6 查看某进程是否运行在大核
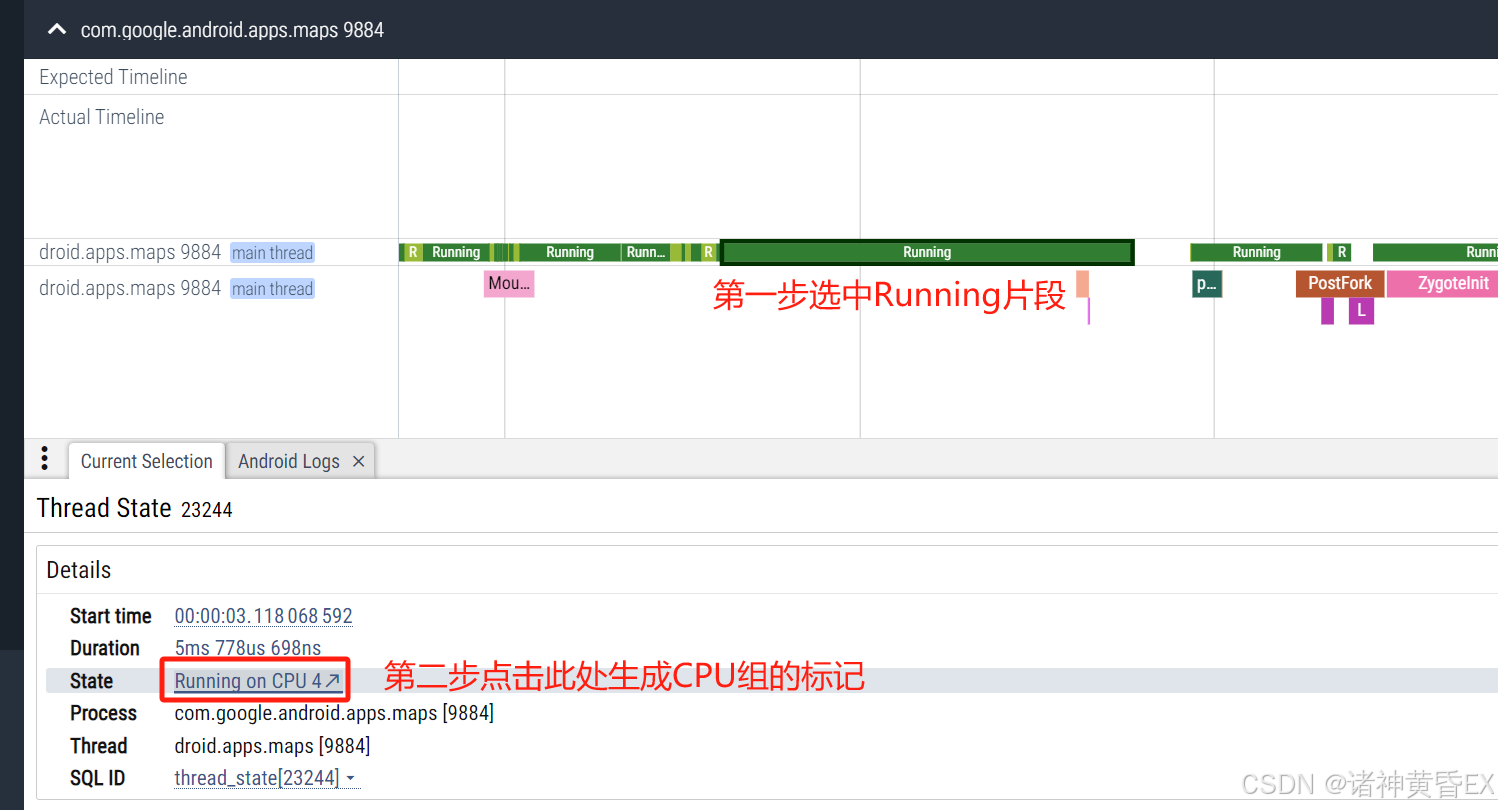
可以通过点击指定进程的runing片段,然后点击底部信息栏的Runing on CPUX会在对于的CPU片段生成一个标记,将鼠标移动到这个标记上面,就会隐藏其他的进程,高亮当前进程,来判断该进程整个过程大部分时间处于哪个CPU,通常CPU6和CPU7就是大核。
注意:具体大核不同平台不一致,需要去查找芯片手册
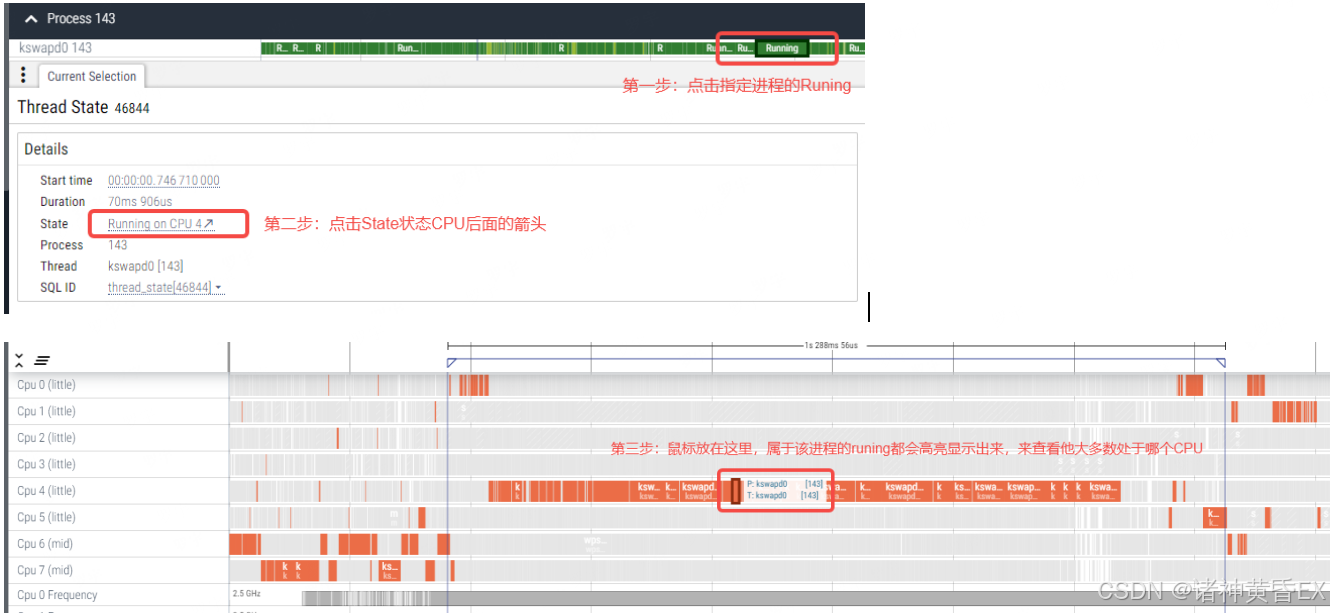
如上例子通过选取进程143的Runing片段,从图中可以看出143进程大部分时间运行在CPU4,非大核。
1.3.7 CPU的大核占用率计算
跟CPU负载计算一致,我们可以针对某个进程,分别选取所有CPU的总运行时长,和大核所在的CPU(PS:通常CPU6和CPU7是大核)的总运行时长。在与对比机进行对比的时候,如果大核占用率存在明显的差异,我们可以考虑考虑存在摆核或者其他进程抢占问题存在。其公式如下:
CPU 大核占用率 = 大核运行此应用主线程Wall duration / 所有CPU运行此应用主线程Wall duration
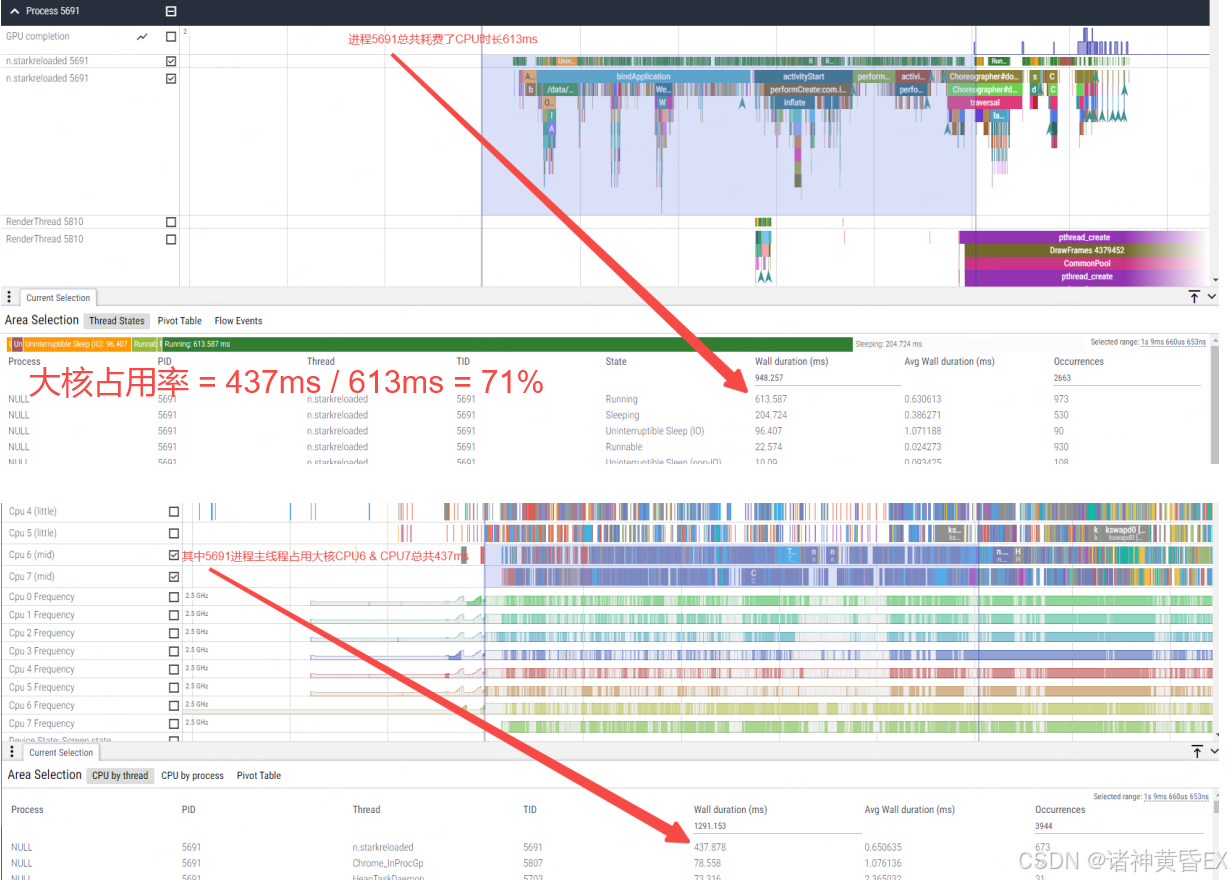
2、应用启动问题分析
有些应用的启动过程本身都耗时特别长,可能长达几秒或者10秒,有些应用的启动过程耗时比较段,可能短至300ms都能启动。因此针对这类问题,通常需要有一台对比机进行对比,通过某些应用或者多个应用的启动来分析设备的性能问题。
Perfetto + trace来分析应用启动问题简直不言而喻。因为Perfetto解析trace文件之后,如果此阶段存在应用的启动,那么必定会有一个Android App Startups,如下为maps应用的启动过程:
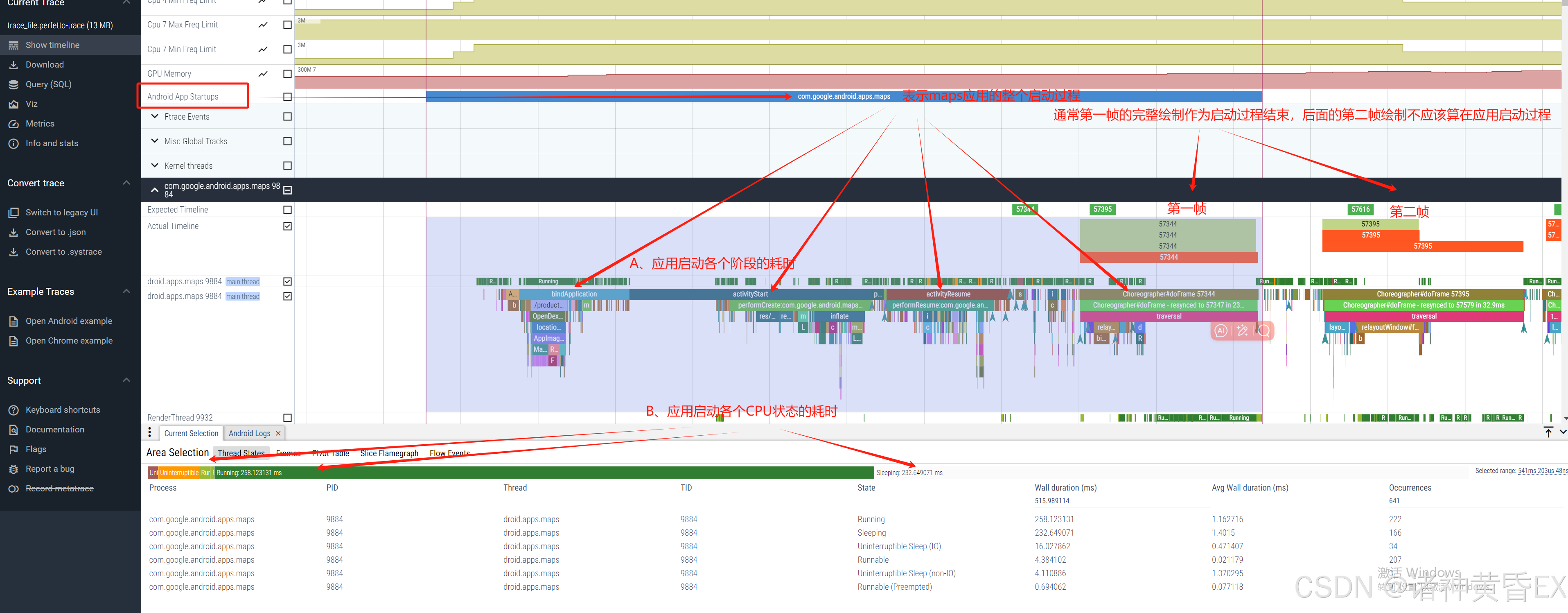
如上例子为maps应用的启动过程,其启动流程会依次经历:
ZygoteInit
ActivityThreadMain
bindApplication
activityStart
activityResume
Choreographer#doFrame
PS:正常情况下以第一个Choreographer#doFrame作为结束点
如下依次介绍一下我们的分析思路:
- 和对比机确认启动阶段耗时是否存在差异?
- 和对比机确认CPU的运行状态是否存在差异?
- 和对比机确认CPU运行的频率是否存在差异?
- 和对比机确认CPU系统负载是否存在差异?
- 和对比机确认是否存在低内存?
- 和对比机确认是否存在其他进程抢占CPU资源?
3、卡帧丢帧问题分析
参考链接:Android Systrace 基础知识 - SurfaceFlinger 解读 · Android Performance
4、CPU运行状态分析
4.1 Running
参考链接:Systrace 线程 CPU 运行状态分析技巧 - Running 篇 · Android Performance
参考链接:https://online.mediatek.com/apps/quickstart/QS00157#QSS03759
参考链接:https://online.mediatek.com/apps/quickstart/QS00157#QSS03735
如上链接已经详细的对CPU Running状态做了比较深入的介绍。因此如果和对比机存在明显的Running差异,那么可以认为CPU的执行能力不够,或者存在高负载情况影响了CPU的执行能力。
4.1.1 应用启动场景
如下为MTK官方网站针对应用启动场景因为Running的原因的分析思路
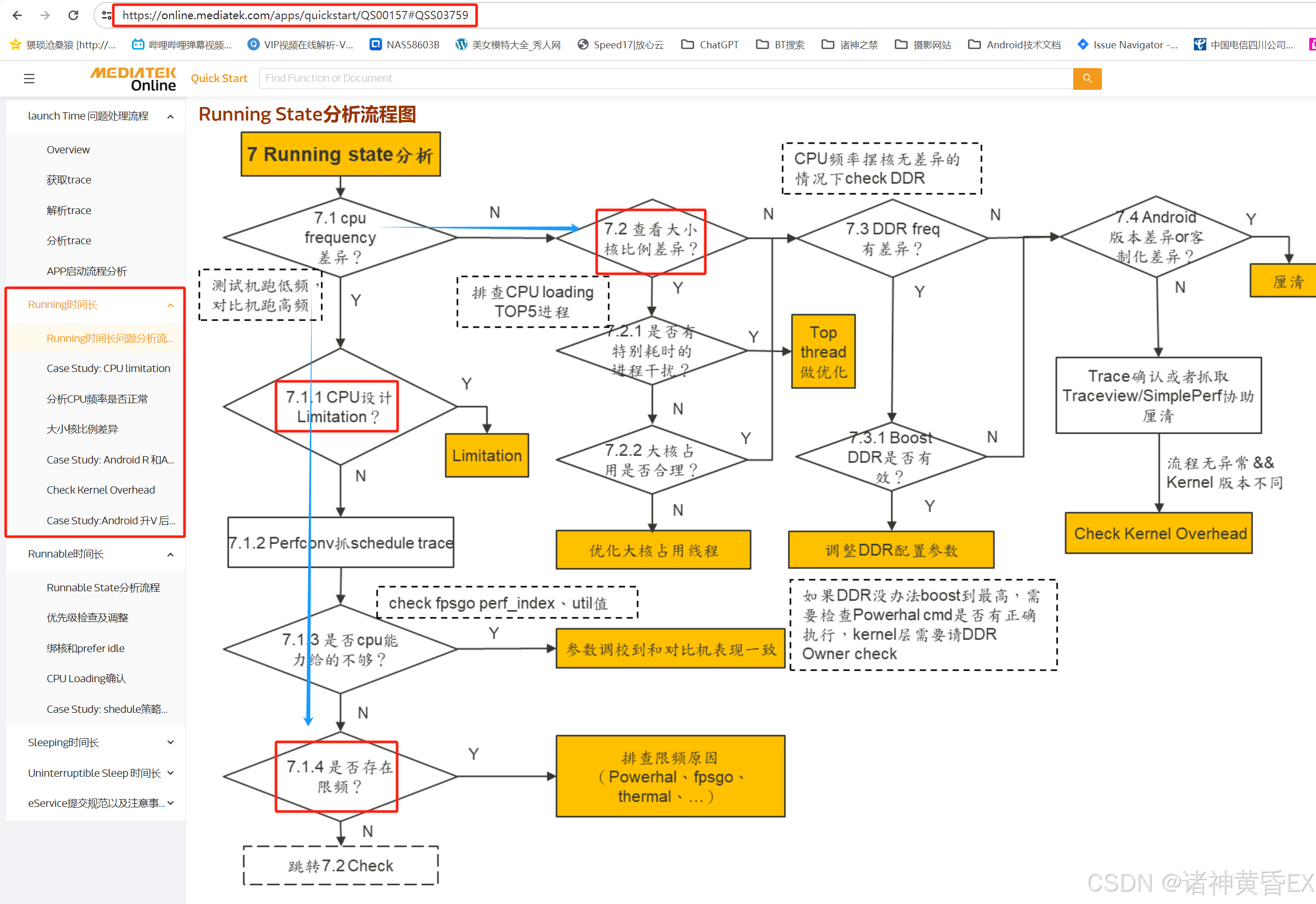
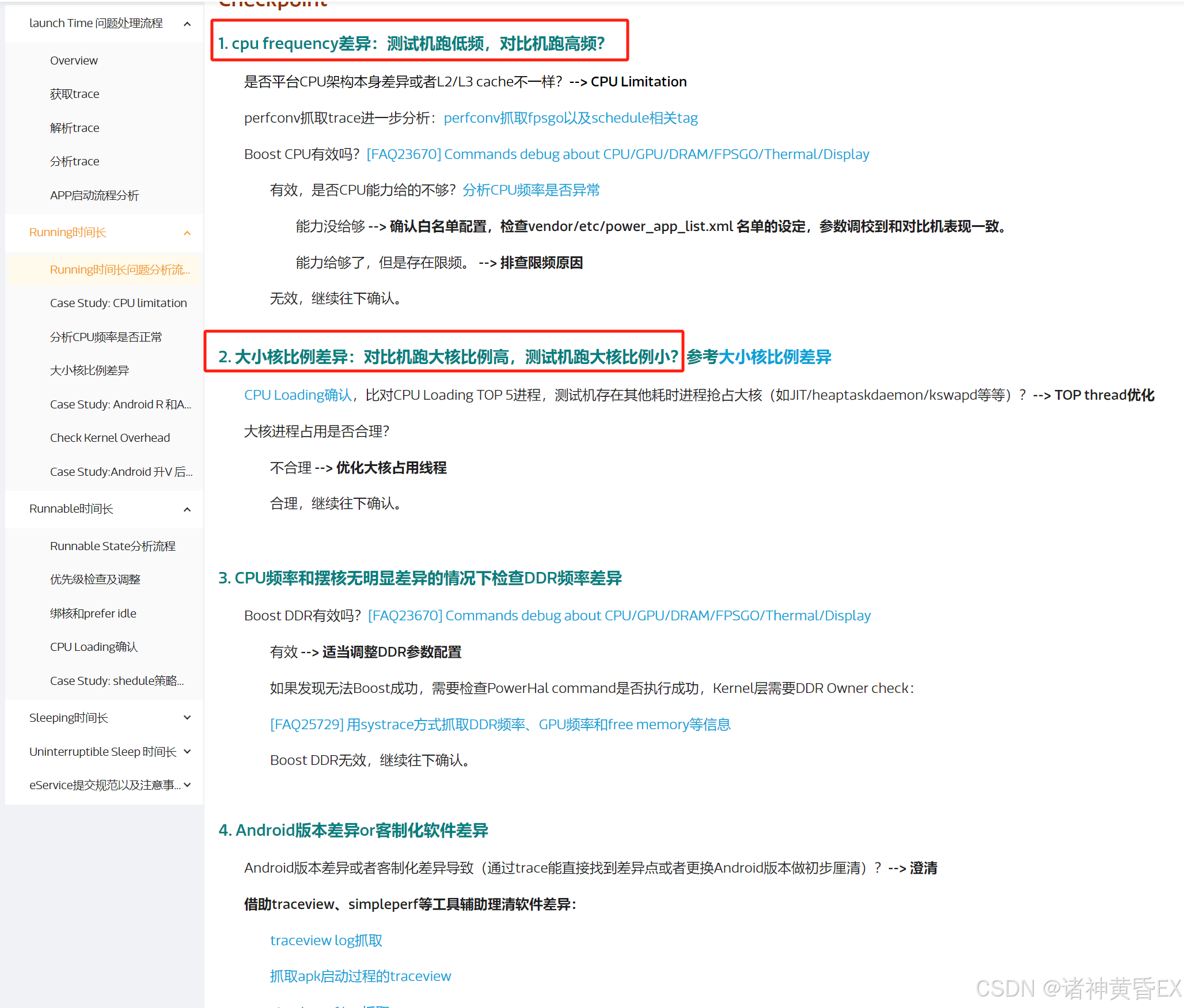
总结如下:
- 和对比机的CPU频率是否处于同一水平?
- 是否存在频率限制,是否存在温升限频率,针对单个进程提升CPU频率
- 是否存在其他进程抢占,大核占用率是否一致?
- 系统负载是否一致,是否存在优化空间?
- DDR没有遇到过,不是很熟悉
4.1.2 卡帧掉帧场景
如下为MTK官方网站针对卡帧丢帧场景因为Running差异的分析思路
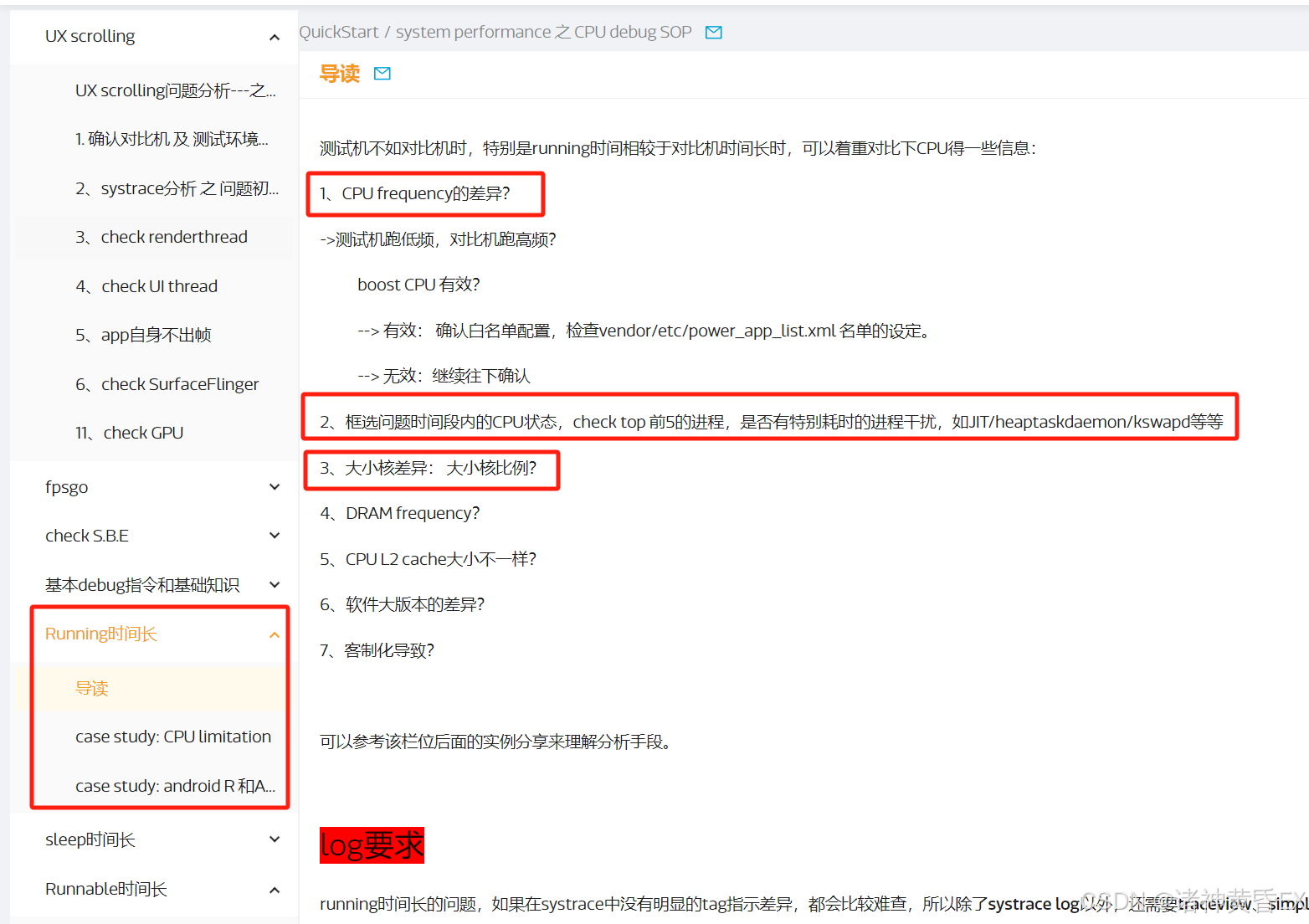
总结同应用启动场景
案例一:android.bg进程抢占CPU大核导致应用启动Running过长
通过和对比机check CPU运行状态和计算CPU大核占用率可以发现存在差异,圈选CPU所有任务可以发现system server进程的android.bg线程排行首位导致
案例二:应用编译模式不一致导致应用启动Running过长
通过和对比机check 应用启动的各个阶段,发现bindApplication阶段存在大量dex2oat操作。应用的dex2oat状态不同会影响代码的执行效率,等级越高执行速度越快(everything>speed>speed-profile>verify),但相对执行的dex2oat本身的执行也耗时。
dex2oat参考链接:https://online.mediatek.com/apps/quickstart/QS00111
针对此类问题有如下方案:
- MTK方案,在每次应用冷启动期间尝试执行dex2oat,尝试4次,参考DexOptExtImpl.java
- 展锐方案,Unipnp框架下的一个feather,逻辑跟mtk功能一致,参考DexOptimizeScene.java
- Android原生方案,设备空闲时自动进行后台dex2oat,这种方式触发的条件比较苛刻(灭屏待机+充电+间隔24小时),参考BackgroundDexOptService.java
案例三:GMS应用执行verifyClass操作导致应用启动Running过长
部分应用trace上看到大量verifyClass流程,校验的类路径都是com.google.android.gms.xxx,分析发现这些类都属于gmscore的插件apk,例如ads dynamite。通过trace发现,做校验类所在apk的路径大多数是/data/user_de/0/com.google.android.gms/app_chimera/m/0000X/xxx.apk,这些apk都属于com.google.android.gms的插件apk

综上分析,解决方案就是首次开机完成后,对gmscore的secondary apk做dex2oat预编译优化,生成插件apk的oat文件,让class_linker.cc中的verifyclass方法走不耗时的verifyClassFromOat
services/core/java/com/android/server/pm/PackageManagerService.java
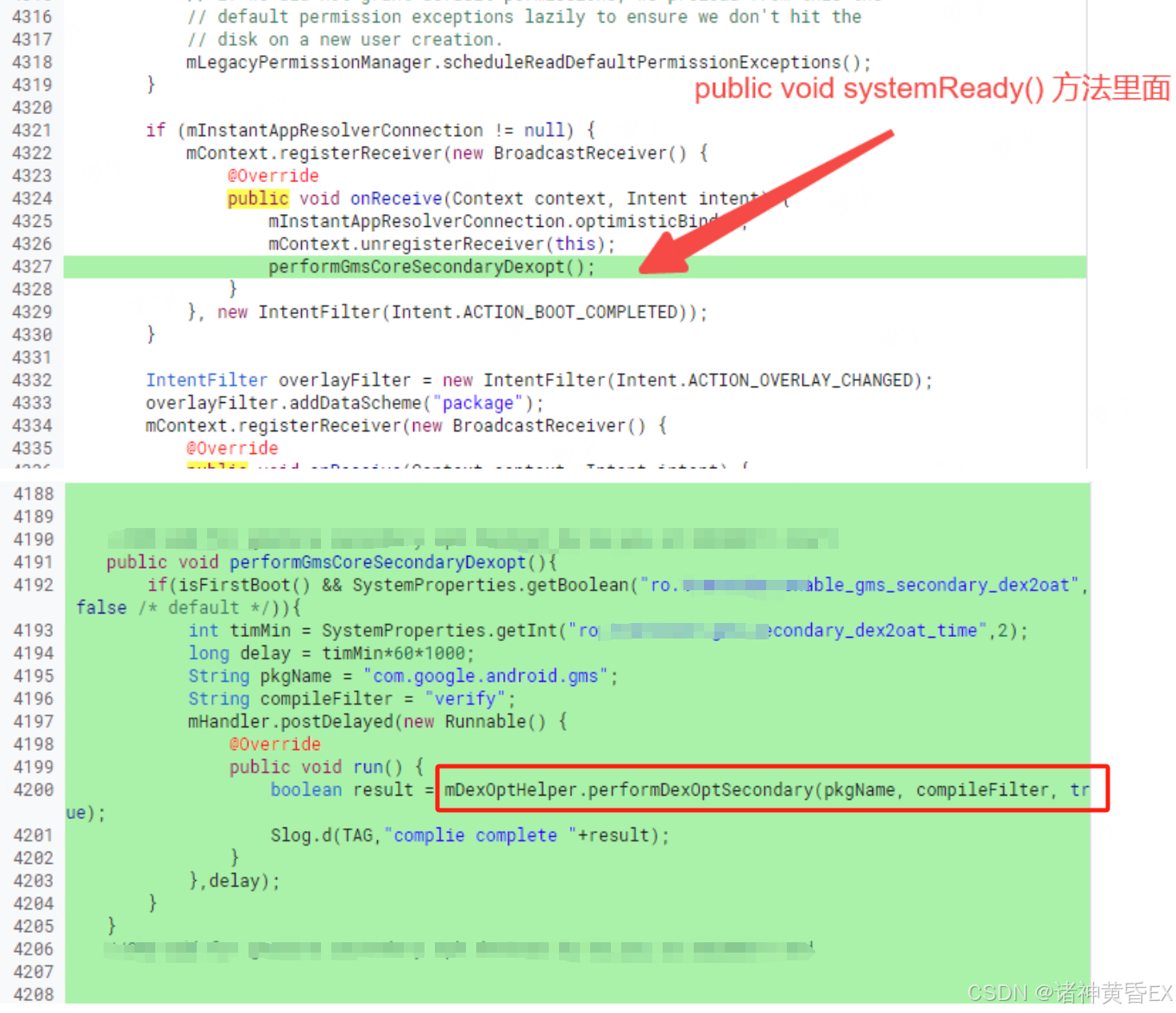
使用adb shell dumpsys package com.google.android.gms的输出结果说明此方案有效
案例四:温升限频导致游戏掉帧
问题描述:原神在环温25度情况下游戏,会出现掉帧
原因分析:因为板温过高导致CPU频率被限制

4.2 Runnable
参考链接:Systrace 线程 CPU 运行状态分析技巧 - Runnable 篇 · Android Performance
参考链接:https://online.mediatek.com/apps/quickstart/QS00250#QSS02568
参考链接:https://online.mediatek.com/apps/quickstart/QS00157#QSS03735
如上链接已经详细的对CPU Runnable状态做了比较深入的介绍。因此如果和对比机存在明显的Runnable差异,那么可以考虑CPU Loading负载及Task schedule调度策略有关系。
4.2.1 应用启动场景
如下为MTK官方网站针对应用启动场景因为Runnable的原因的分析思路
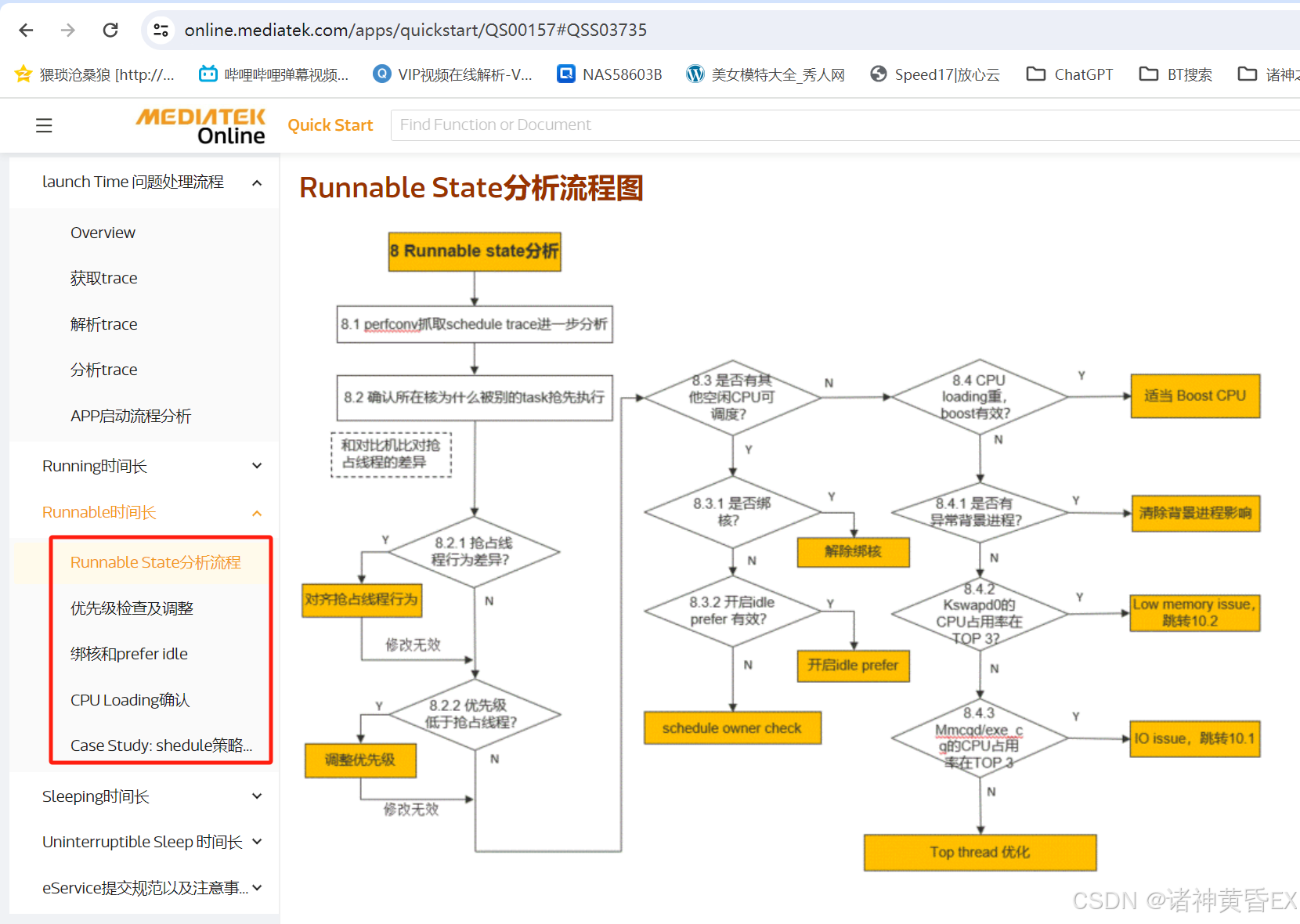
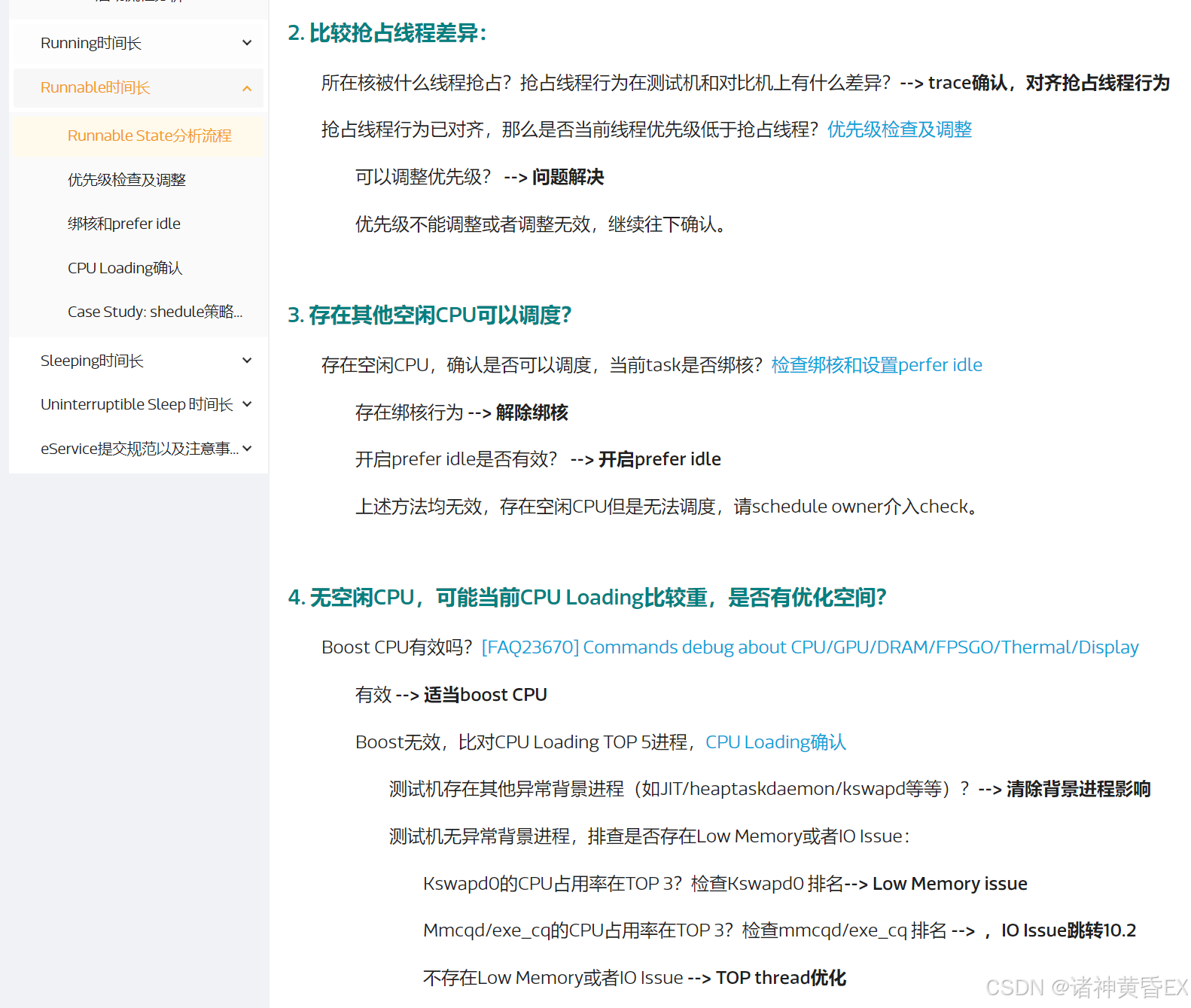
总结如下:
-
是否存在其他线程抢核,大核占用率是否存在差异?
-
是否存在绑核行为,能否提升该进程的优先级?
-
计算CPU的负载,看是否存在优化空间?
4.2.2 卡帧丢帧场景
如下为MTK官方网站针对卡帧丢帧场景因为Runnable差异的分析思路
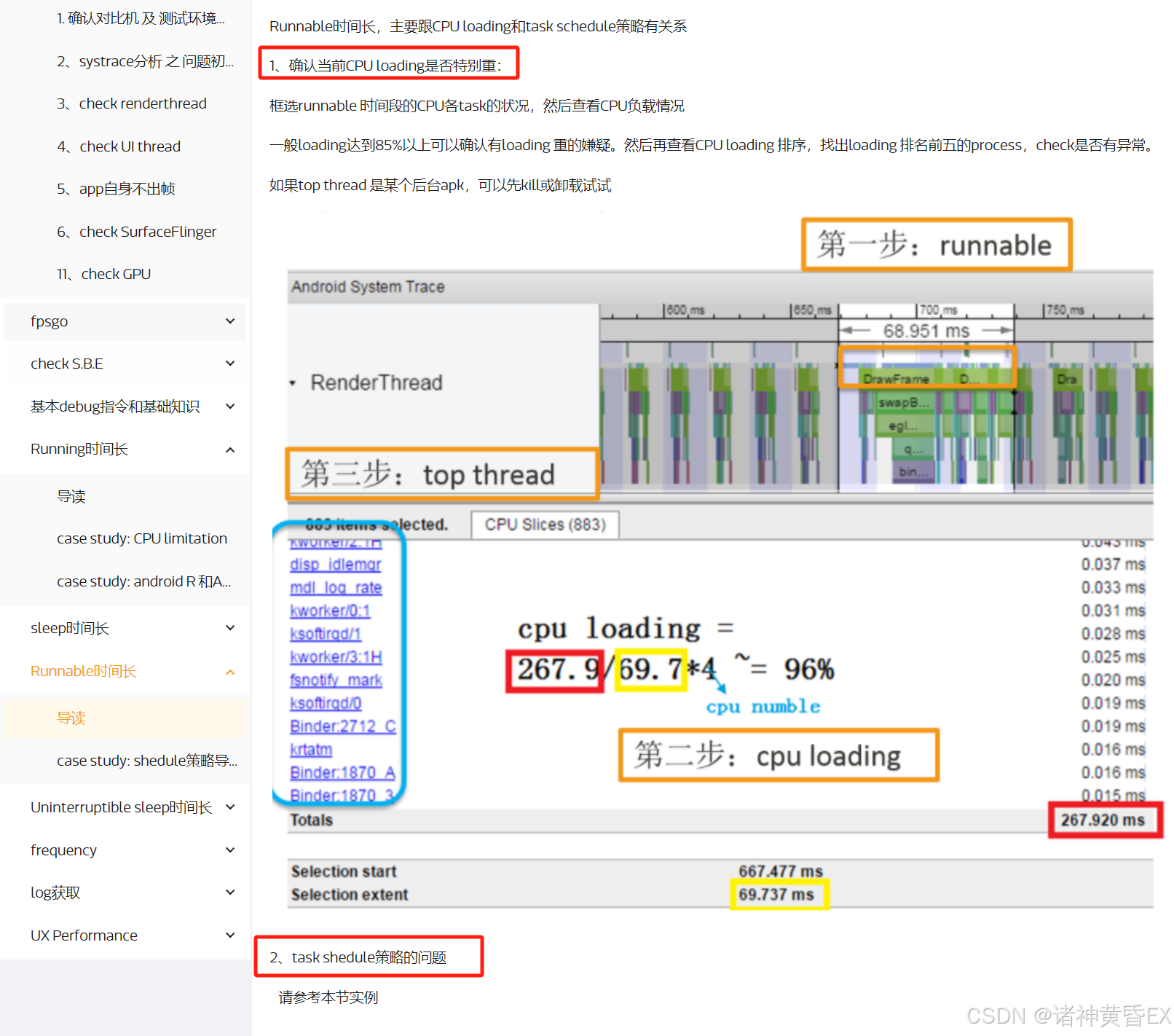
总结如下:
- 计算CPU的负载,是否存在优化空间?
- 从调度策略方向考虑,能否对主线程/SF线程进行绑大核?
案例一:开机后负载高导致应用启动慢
问题描述:TOP应用主观体验,重启后相机、设置、Chrome、WhatsApp、TikTok、youtube、Twitter等应用进行冷启动卡顿、启动时间较慢
原因分析:主要是开机的时候后台起来的进程较多,导致负载重,响应较慢,这是一个典型的高负载场景
解决方案:配置powerhal相关参数,提升对于应用的优先级和亲和力

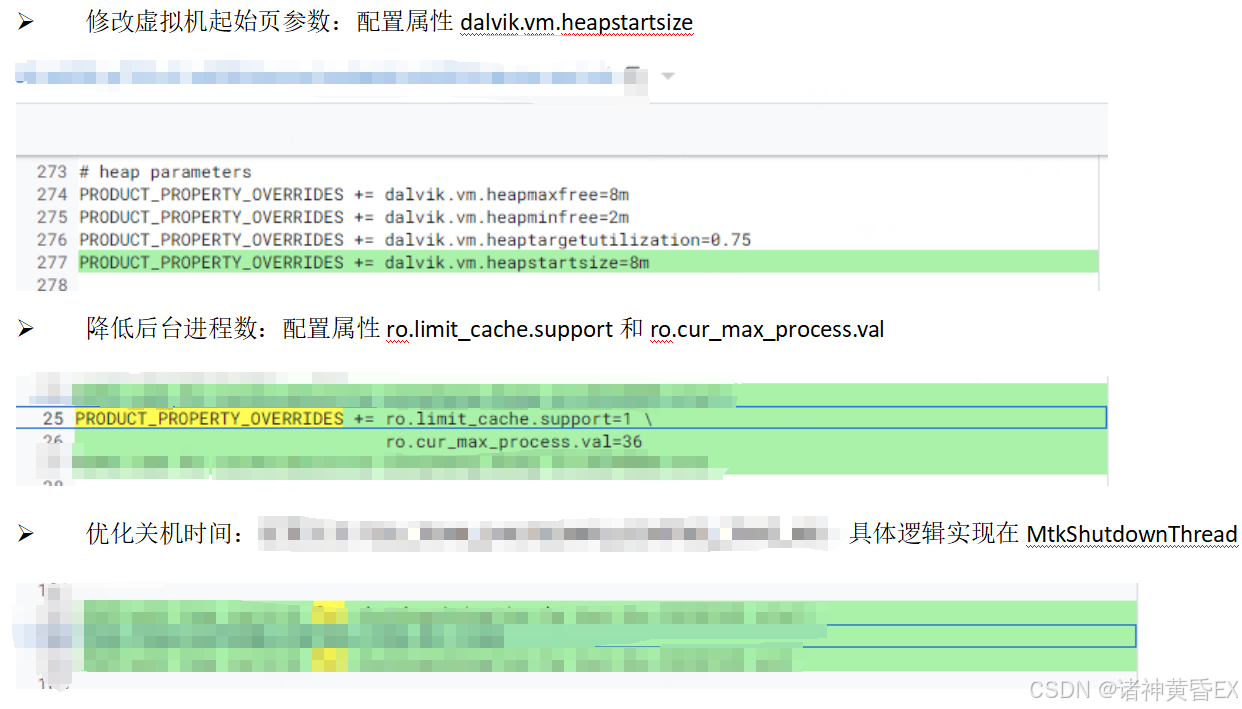
案例二:性能参数重新适配优化CPU均衡能力
问题描述:多个应用冷启动测试数据均差于对比机(红米13C)50ms以上
原因分析:CPU频率未拉满,且主要跑在小核;触摸滑动后提频时长不足,可能造成卡顿;内存读写速率较差;kswapd活跃且抢占大核资源
解决方案:修改各类参数和调度策略
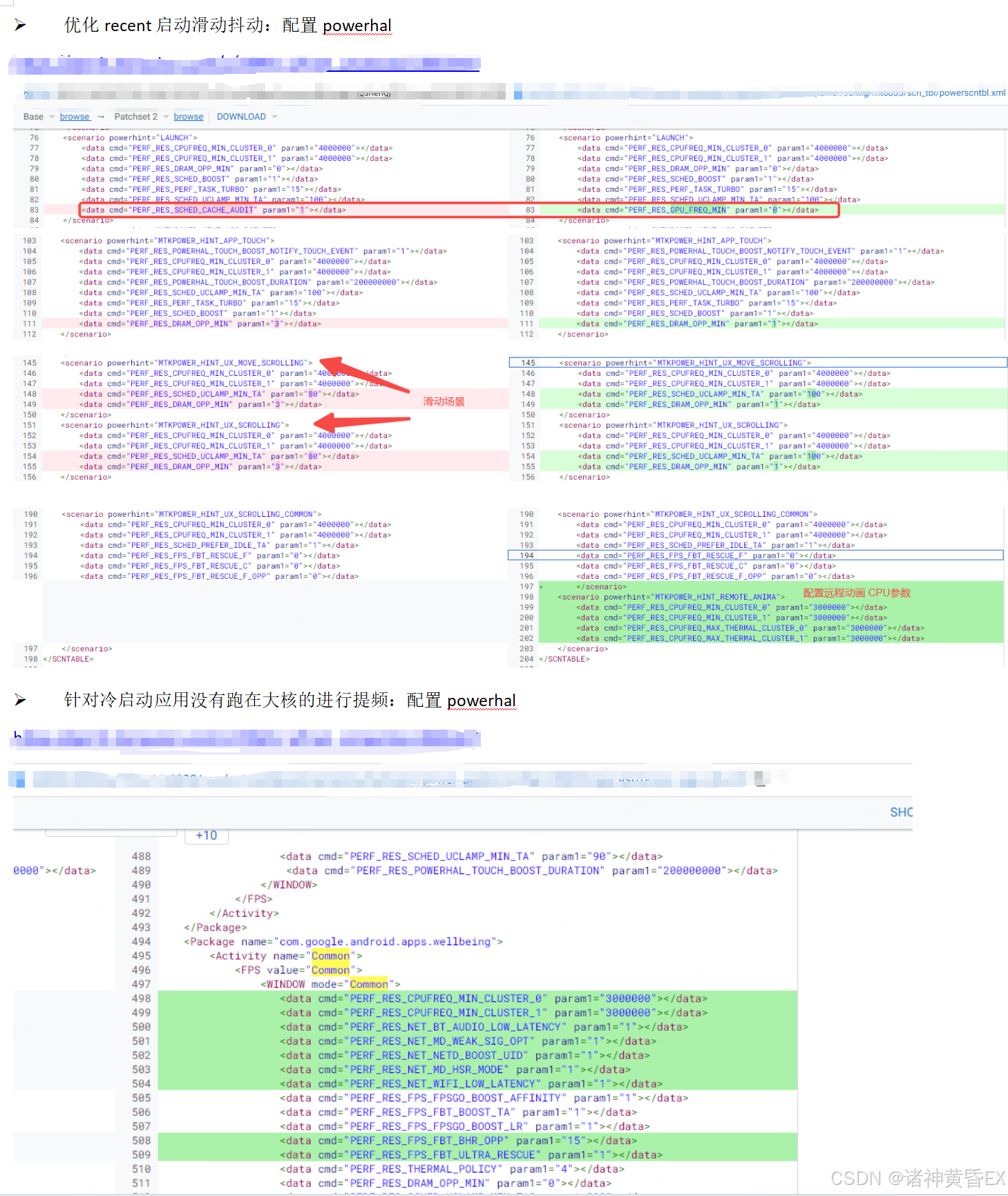
4.3 Sleep
参考链接:CPU 运行状态分析技巧 - Sleep 和 Uninterruptible Sleep 篇
参考链接:https://online.mediatek.com/apps/quickstart/QS00157#QSS03773
参考链接:https://online.mediatek.com/apps/quickstart/QS00250#QSS02562
应用启动场景和丢帧卡帧场景,MTK的分析思路都是去寻找唤醒源
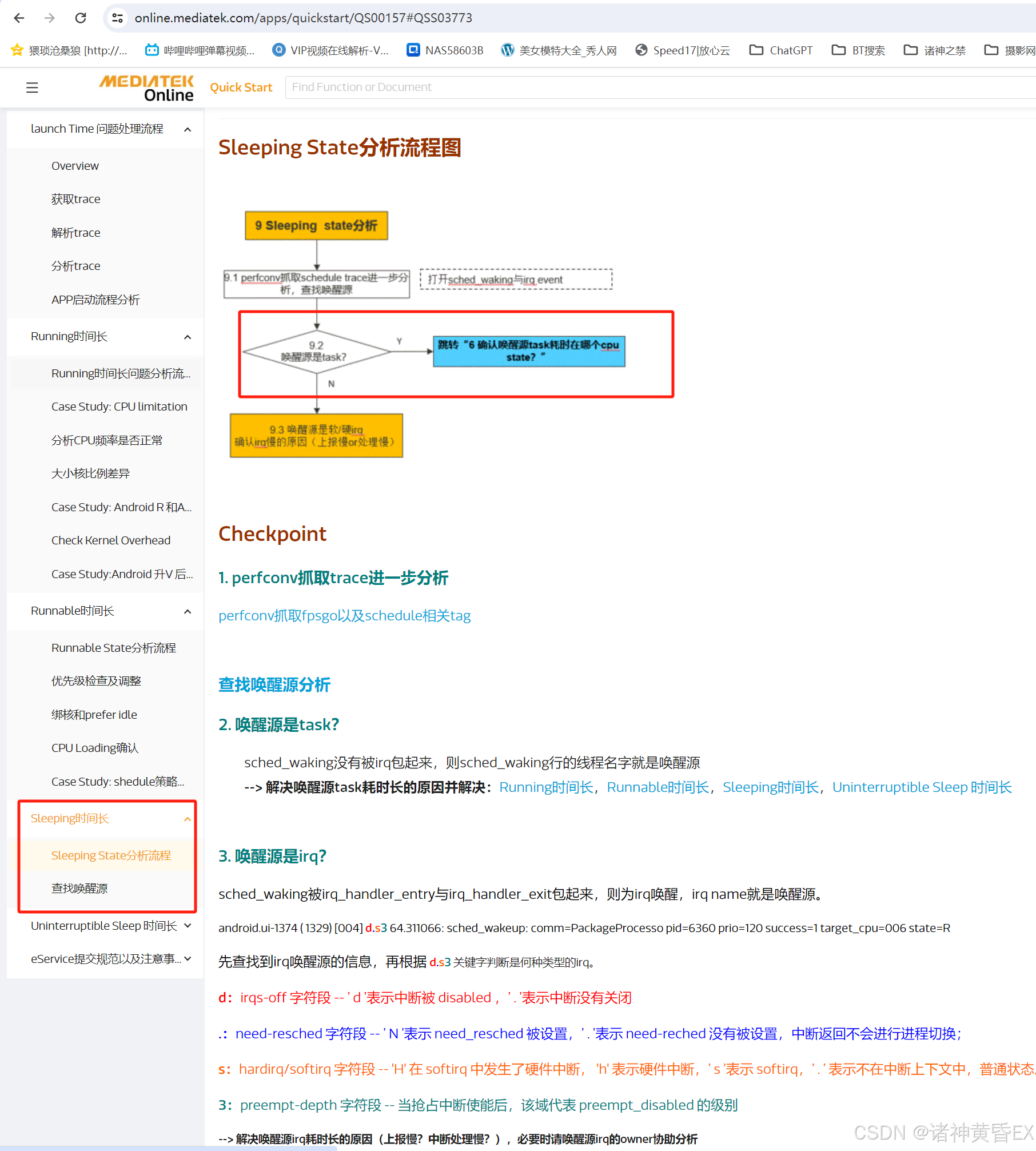
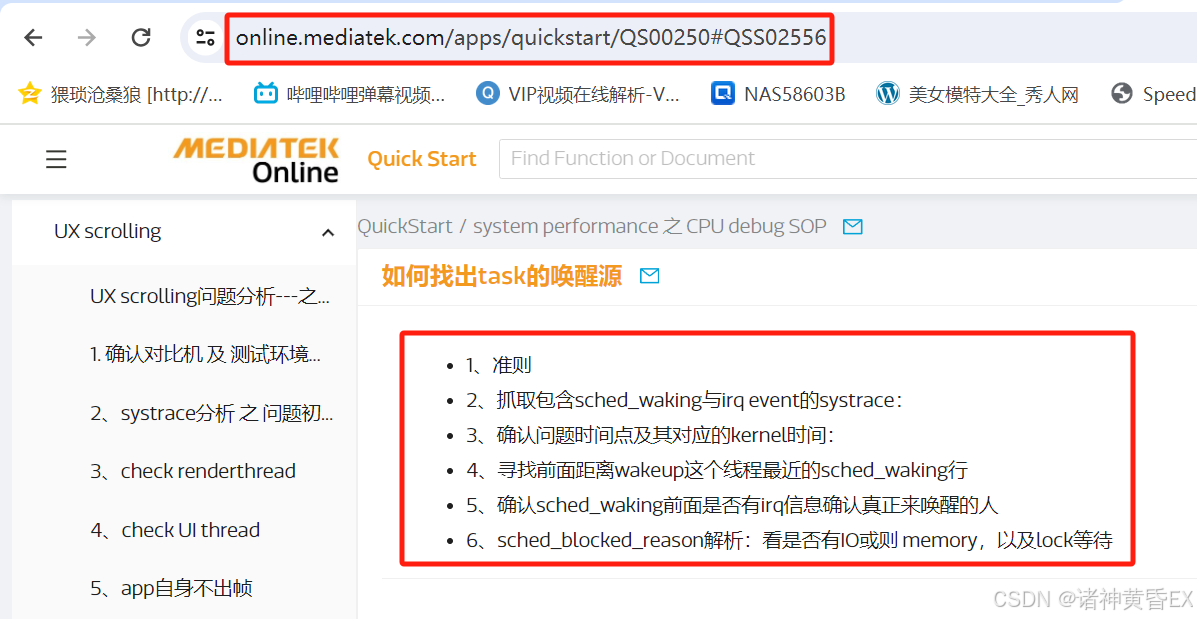
总结如下:
-
MTK官方文档介绍的去查找唤醒源,唤醒源的查找方式可以参考1.2节。但在实际问题处理中感觉此方法并没有太大的作用
-
根据经验来看,系统调用、内核函数、锁等待、binder调用等都可能让线程进入sleeping状态,所以导致问题的原因可能很分散且不止一个,这类耗时没有通用的优化方案,只能结合具体问题深入分析找到异常点,同时优化整机性能,项目上最常见的是卡binder导致的sleeping耗时
案例一:wmshell架构变动导致应用横屏activityStart binder reply等锁耗时过长
应用横屏在activityStart阶段,有一个长约300ms的binder transaction耗时而对比机没有,binder reply在等锁,持锁端为system_server的另一个binder线程,该binder线程正在做updateGlobalConfiguration的reply操作,发起端是systemui::wmshell.main。最终确认是U上wmshell架构变化导致,推动systemUI解决。
案例二:Launcher异常绘制导致ActivityThreadMain Binder Transaction耗时过长
在ActivityThreadMain阶段,测试的binder transaction耗时明显比对比机长很多,对端操作都是system_server:attachApplication。但是测试机有一段明显的lock contention等锁耗时,持锁端是system_server:android:anim,可以看到测试版本上该线程多一个android.os.Handler:com.android.server.wm.WindowSurfacePlacer$Traverser(绘制准备流畅)。最终确认是Launcher的问题,应用启动时绘制所有页面的应用图标。
案例三:system_server因为其他进程出现批量binder响应导致Sleep耗时过长
应用整个启动过程中,测试机sleeping耗时比对比机多200ms。测试机上很多的binder耗时都比对比机更长,对端均是system_server,可以看到system_server的binder在执行次数是对比机的倍数,且大多数的binder都在响应一个应用demoThread(所属进程为Lazada)的transaction,而对比机没有这种现象,这种情况就需要排查binder调用端所属进程的异常行为。
4.4 IO
参考链接:https://online.mediatek.com/apps/quickstart/QS00157#QSS03741
参考链接:https://online.mediatek.com/apps/quickstart/QS00250#QSS02608
Block IO耗时主要涉及三类情况:内存问题、IO问题(包括文件系统、物料)、某进程自身逻辑请求IO占用过高等场景
4.4.1 低内存导致IO异常增高
在内存不足的时候,系统会频繁通过申请swap空间访问磁盘(filepage页被换出,需要重新从磁盘读取),导致IO数据量请求升高。此时可以通过trace中增加如下两个节点来判断是否内存问题:
mm_filemap_add_to_page_cache ->把文件映射到页缓存
mm_filemap_delete_from_page_cache ->从文件映射中删除页缓存
(通过映射的页缓存的总量来确认是否存在内存相关问题),即mm_filemap_add_to_page_cache和mm_filemap_delete_from_page_cache和对比机对比出现明显差异,可以认为内存原因或者低内存导致。
除此之外,MTK官方网站建议如何判断是否存在Low Memory:

针对低内存 的优化方案,MTK官方网站也建议如下:
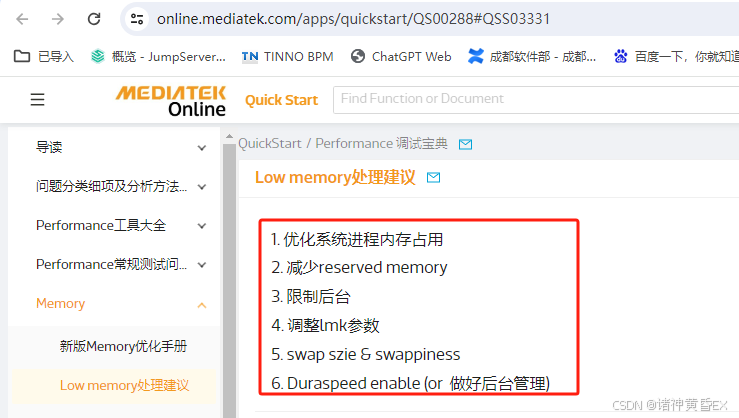
参考链接:https://online.mediatek.com/apps/quickstart/QS00288#QSS03331
4.4.2 是否有IO请求巨大的进程
在排除内存原因之后,我们需要确认IO数据量的请求情况,做这一步的目的是看看有没有特别的进程在疯狂进行IO请求导致整个IO高,即使没有这种情况,也能够为下一步分析是存储器件问题还是文件系统问题提供一个基础。
这里介绍两种方式来排查所有进程的IO请求量:
方式一:Trace中的android_fs字段
用文本工具直接打开trace文件,搜索所有的android_fs字符串:

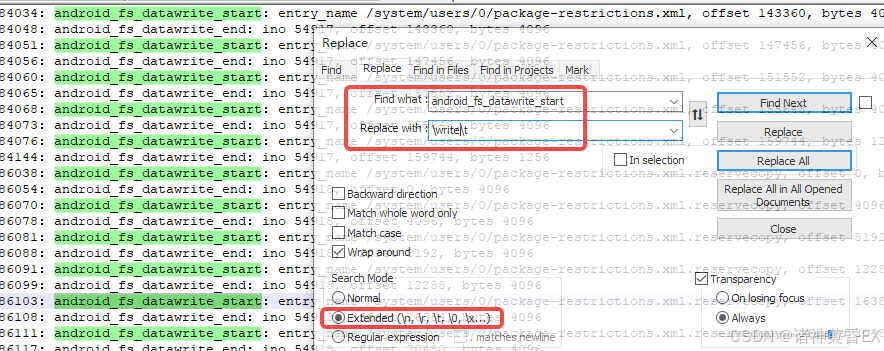
android_fs_dataread_start 替换成 \tread\t
android_fs_datawrite_start 替换成 \twrite\t
entry_name 替换成 \tentry_name\t
, offset 替换成 \toffset\t
, bytes 替换成 \tbytes\t
, cmdline 替换成 \tcmdline\t
, pid 替换成 \tpid\t
, i_size 替换成 \ti_size\t
, ino 替换成 \tino\t
替换之后的日志直接copy到Excel表格里面,整理一下格式如下图:
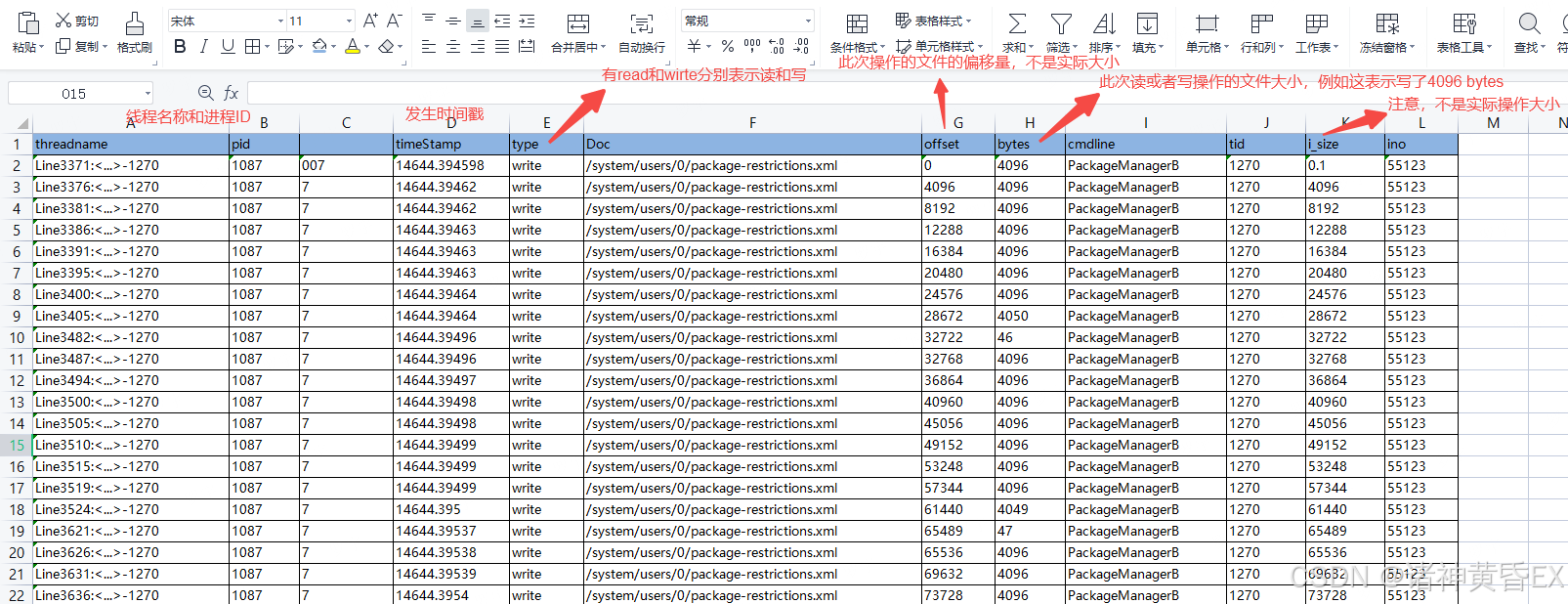
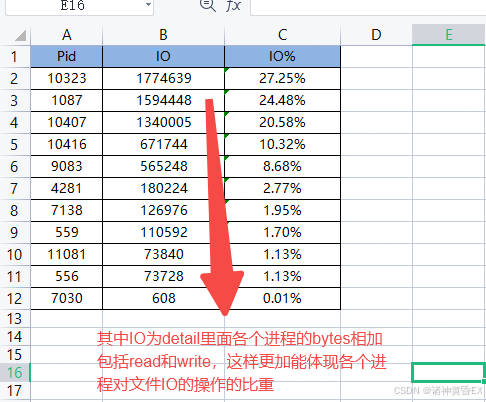
举个例子:VerifierDataSto线程疯狂请求IO
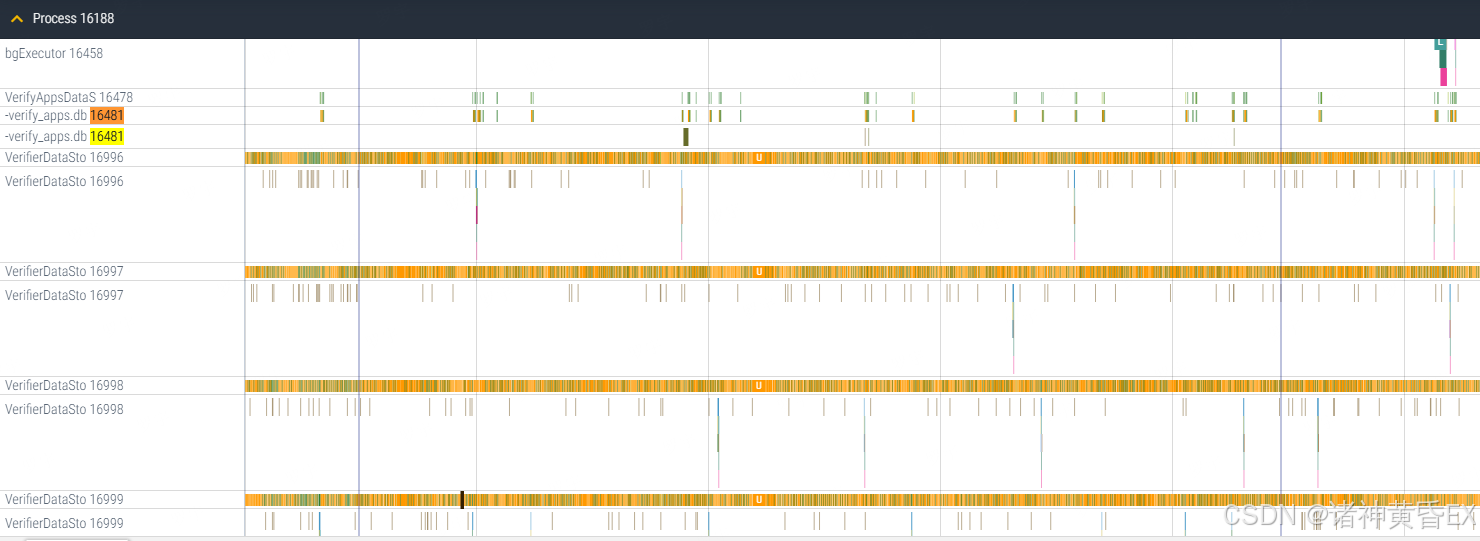
打开trace搜索VerifierDataSto发现基本上没有android_fs的打印,但是有很多block_rq相关的打印,说明这里的IO不涉及文件系统,因此下面针对block_rq进行解析。观察可以发现block_rq_insert和block_rq_issue相差不大,block_rq_complete信息不是很全,因此提取了所有的block_rq_insert信息来进行表格解析,最后输出表格如下:
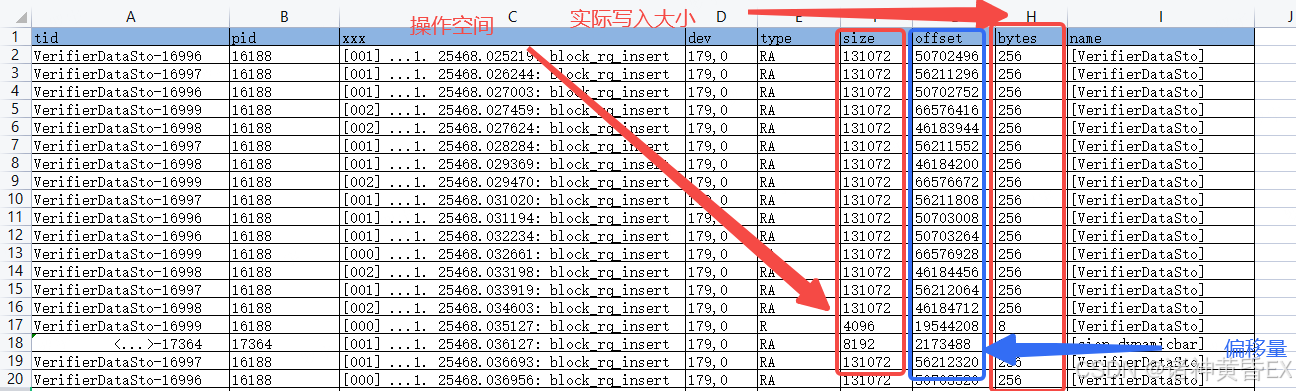
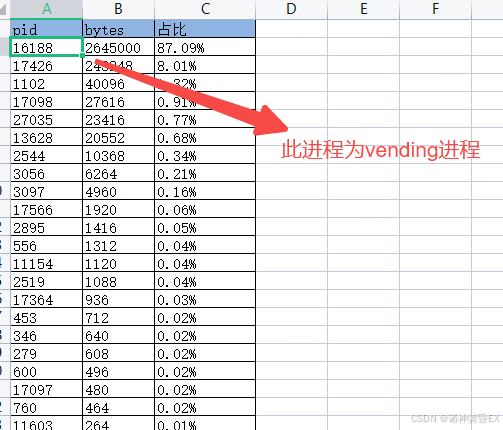
方式二:Trace中的block_rq_insert字段
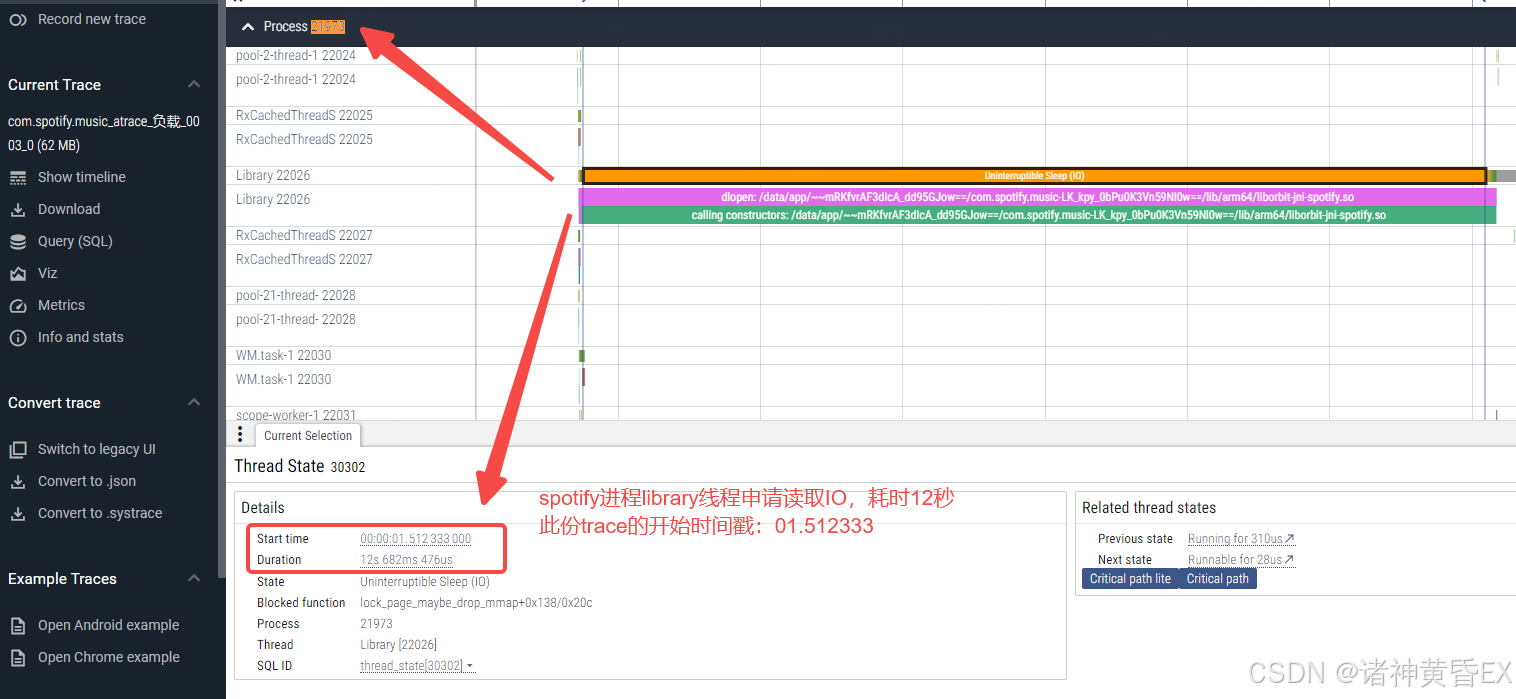
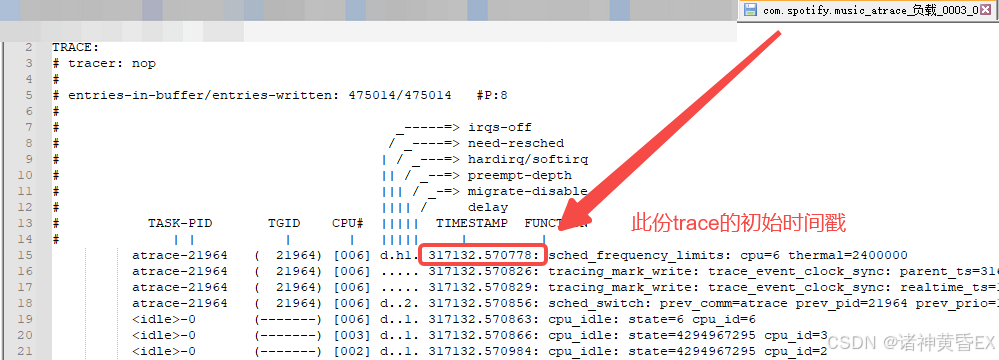
如果要寻找到上面那份耗时12秒的IO请求,可以先粗略的计算时间戳:317132.570778+1.512333=317134.083111单位秒

如上搜索block_rq_insert结合大概时间范围和线程name,基本上可以确定如上圈红为这次IO请求:
IO请求三步曲:
第一步:block_rq_insert(申请排队)
第二步:block_rq_issue(底层设备执行)
第三步:block_rq_complete(底层设备执行完成)

- 设备信息:8,32 其中8代表了设备的主设备号,32代表了次设备号
- 请求类型:RA表示预读取操作,除此之外还有R(普通读取操作)、WS(普通写入操作)、WSM(写入重复的数据块)
- 请求数据:131072 () 80058320 + 256 表示读取空间128kb,偏移量80058320,实际读取的长度为258字节
从上面的日志来看底层设备从issue到complete,读取256个字节长度,居然耗时了12秒,高度怀疑底层设备器件问题。
方式三:MTK总结推荐关键字段
MTK官方网站介绍了一些关键字来确认IO数据量的请求,详细可以点击我

在trace中新增如上节点,block_rq通常以IO请求的维度,android_fs通常以文件系统的维度,mmc_request通常以emmc维度,其中emmc会是trace文件变得很大,我们通常分析的android_fs和block_rq:
- block_rq_insert:表示将一个新的块I/O请求插入到块层请求队列中。当应用程序或者操作系统发起一个读取或写入请求时,这个请求会被插入到块I/O请求队列中等待处理
- block_rq_issue:表示一个块I/O请求已经提交并开始执行,具体含义是块设备层已经向硬盘或固态驱动器提交了一个请求,并此请求已经在硬盘或驱动器设备上执行。当I/O请求插入到请求队列中表示等待执行,issue事件才表示才表示请求队列终于到它并且底层设备开始处理,但是并表示处理完成,处理完成还得靠complete事件
- block_rq_complete:表示一个块I/O请求已经完成,数据已被读取或写入到磁盘上。当I/O操作成功完成后,将触发此事件
- block_rq_requeue:表示一个块I/O请求被重新排队等待处理。当某个请求需要重新排队或延迟处理时,系统会触发此事件,将请求放回队列中以等待后续处理,如果此事件升高的原因可能很多
- android_fs_dataread_start:表示android文件系统开始进行数据读取操作。这个事件通常标志着文件系统正在从存储设备中读取数据,可能是应用程序请求读取某些文件的内容,或者系统执行读取操作以加载数据到内存中等
- android_fs_datawrite_start:表示android文件系统开始进行数据写入操作。这个事件表示文件系统正在往存储设备中写入数据,可能是应用程序在创建新文件、更新文件内容或者将数据持久化到磁盘等操作
- mmc_request_start:表示MMC请求的开始阶段。当系统或应用程序发起一个MMC请求时,这个事件标志着请求的启动,并表示MMC控制器已经开始处理该请求
- mmc_request_done:表示MMC请求的完成阶段。当MMC请求被成功处理并执行完毕时,这个事件被触发,表示请求已经完成且响应的数据传输或操作已经结束
- sched_block_reason:表示调度器在某个进程或线程上阻塞的原因。当一个进程或线程无法立即执行,处于等待状态或被挂起时调度器会记录下其阻塞的原因

其中iowait 为 1 表示在等待IO完成,为0表示可能是其他原因让线程挂起或者等待;caller表示调用者
4.4.3 硬件物料差异
述都排除之后就考虑IO问题(包括文件系统、Flash物料的问题),此时我们可以做如下三件事情:
- 确定是否ROM物料差异:AndroidBench跑分数据是否存在差异;测试机和对比机换料测试是否存在差异。如果存在差异看看是否能够澄清
- UFS文件系统差异:统计ufshcd_command trace
- 转到存储模块进行分析
4.4.4 UFS-Delay经典案例
功能说明
Ufs-delay是UFS文件系统的一个功能,目的是UFS在没有IO请求的时候进入PowerMode以节省功耗,但是频繁的调用会造成如下两个问题:每次进入/退出PowerMode都会有性能开销造成一定的延时;PowerMode模式当有大量IO请求到来时,因为能力受限可能无法及时响应io request,文件系统返回busy进而导致IO requeue retry。
解决方案
针对上面提到的两个问题,展锐平台已经回退为原生的150ms,MTK平台根据计算来进行动态设置。但是ufs的此功能受器件性能的影响较大,因此针对不同项目上,如果出现因为ufs-delay导致的问题,可以尝试增大delay值来看看是否有所改善。
相关分析
问题描述:有Trace表现为Block IO测试机比对比机多400ms在trace中增加pagecache
第一步分析:通过mm_filemap_add_to_page_cache关键字排除低内存问题
直接用记事本打开trace文件搜索如上关键字:


如上第一张图为对比机共申请了9911次,第二张图为测试机共申请了10084次。同一个应用启动过程中,测试机和对比机执行mm_filemap_add_to_page_cache的次数基本一致,从page allocate侧基本可以排除掉内存原因导致。
第二步分析:通过block_rq_complete关键字排除存在异常IO请求的进程
在排除内存问题之后,可以在分析一下IO请求量,这里主要用block_rq_complete,直接打开trace搜索关键字:


上面第一张图为对比机block_rq_complete 1801次,第二张图为测试机block_rq_complete 2014次。可以看到测试机和对比机执行block_rq_complete的次数基本一致,从IO完成情况同样说明读取的数据量一致,接下来需要从IO方向进一步分析了。
第三步分析:排查硬件物料和文件系统
排除了内存和IO数据量,接下来排查了IO速度一致,通过跑分软件对IO和DDR进行跑分,数据差不多。接着在trace中和测试对比了block_rq_requeue,表示块I/O请求已经从块设备请求队列取出(可能是延时或其他原因)并重新插入队列,但是block_rq_requeue的原因特别多。最后定位为文件系统ufs延迟导致


















 5484
5484

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











