










聊聊AHP层次分析法
1 什么是AHP层次分析法?
大家直接Google层次分析法,会发现一条令人哭笑不得,十分尴尬的结果:

想到自己原来参加数学建模竞赛的时候也是经常用AHP层次分析法。。。真的low吗?(笑哭)
那究竟什么是貌似很low的层次分析法呢?
- 层次分析法:AHP(The analytic hierarchy process),从英文名可以看出来这个方式是一个分析层级的过程,啥叫层级?这么拗口?别急,下面详细解释一波!
- 提出者:在20世纪70年代中期由美国运筹学家托马斯·塞蒂(T.L.saaty)正式提出
- 层次分析法是将决策问题按总目标、各层子目标、评价准则直至具体的备投方案的顺序分解为不同的层次结构,然后用求解判断矩阵特征向量的办法,求得每一层次的各元素对上一层次某元素的优先权重,最后再加权和的方法递阶归并各备择方案对总目标的最终权重,此最终权重最大者即为最优方案。
2 这个方法是干吗呢?在什么场景使用?
- 确定指标权重
- 确定最优方案(本质也是确定各个方案的权重,一般选取权重最大的为最优方案)
3 AHP层次分析法的实现
3.1 步骤
- 建立层次结构模型
对决策对象调查研究,将目标体系所包含的因素划分为不同的层次。一般有三层:最高层(总目标),中间层(目标层),最低层(方案层)。【说人话:就是构建一个指标体系,分一二三级指标!】
- 构造成对比较矩阵
按照层次结构模型,从上到下逐层构造判断矩阵。每一层元素都以相邻上一层次各元素为准则,按1-9标度方法两两比较构造判断矩阵。【说人话:构建一个矩阵,里面的数值是业务人员对两两指标的评分!】
- 一致性检验
【下面单独解析】
【说人话:就是上面第二步构建的矩阵如果不符合要求,就要重打!检验的过程就是一致性检验!如何检验?见下面单独解析】
- 确定权重和最优方案
一旦上面一致性检验通过之后,就可以根据矩阵特征向量来确定二级指标和三级指标的权重!
3.2 实际的例子
下面以具体的例子来实现上述的步骤
3.2.1 背景
问题背景:
- 我们现在需要给商户进行评分,作为筛选白名单的依据。
- 商户的评分维度现在假设有6个,记为[企业B1 交易B2 活跃B3 经营B4 风险B5 成长B6]
- 现在假设已经算出了各个维度的评分,需要根据这6项得分算出商户的总得分,在计算的过程中,6个维度的指标权重就显得尤为重要了,是1/6吗?还是有不同的权重?如果不同的,如何得到呢?
- 基于这个问题的背景,AHP层次分析法就闪亮登场了!
3.2.2 Step1 构建层次结构模型
注:为了保护公司隐私,下述信息为真实项目案例脱敏之后的结果!

同时每一个二级指标下面对应着有很多三级指标

这样第一步层次结构模型就搭建完毕了!可以看到:
- 总目标:给商户进行评分
- 目标层:即评估商户的6个维度的指标
- 方案层:即商户每个二级指标下对应的三级指标!
3.2.3 Step2 构造成对比较矩阵
以商户评分-交易-C21~C27为例,专家打分结果见下表:

这个表的含义是什么呢?怎么打出来的呢?
-
C22-C21为8 表示 指标C22 是 C21重要性的8倍。
-
判断矩阵(成对比较矩阵)构造采用Saaty引用的1-9标度方法,各级标度含义见下表:

也就是说我们评判矩阵的重要性就按照1-9打分即可,如果变量A对B重要性是x,那么B对A就是1/x! -
同时可以看到判断矩阵是有一些特殊的性质的,知道了下三角,上三角都是它的倒数,且对角线元素都是1
这样,我们分别对二级指标(B1~B6)以及对应的各三级指标进行评分,构建判断矩阵,本案例应构建的判断矩阵应该有1+6=7个,但企业仅一个维度无需判别,所以应该是构造6个判断矩阵。
3.2.4 Step3 一致性检验
问题:什么叫一致性检验呢?为什么要进行一致性检验呢?
首先给出判断矩阵一致性的定义:

可以看出:
- 判断矩阵都是互反矩阵
- 但是互反矩阵不一定都是一致性矩阵,需要再多一个条件,也就是条件(3):
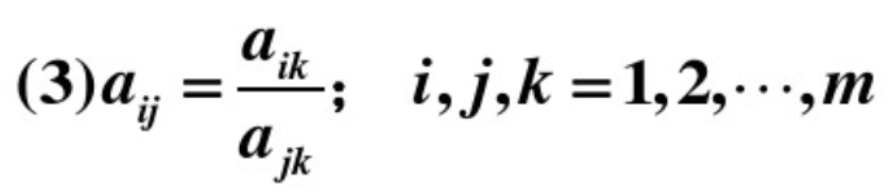
这个条件的含义是什么呢?当时刚看的时候小编也一脸懵逼,但仔细想想,从现实的含义出发理解也就不难了。下面小编就尝试用通俗的语言解释一下:
① 如果k=j,则条件(3)肯定成立,分母为1
② 如果k=i,则条件(3)也成立,即和条件(2)重合了
③ 如果 k≠i 且 k≠j 这时候表示什么意思呢?举两个例子就很清楚了!

通过上面两个矩阵的对比,可以得出条件(3)的含义就是:
- 如果变量2对1的重要性是4,变量3对1的重要性是8,那么变量3对2的重要性应该就是8/4=2 这是符合我们常理的,如果结果不为2,那么就不是一致性矩阵了。
既然知道了矩阵一致性的含义,那么如何去检验和判断呢?是不是都得这么一个一个去算?3×3矩阵还是ok的 但维度提升后,一个一个手算就会很耗时了。那有没有其余的方法呢?答案是有的:

对了,这里有两个重要的线代结论:
- 矩阵对角线元素之和为特征值之和。
- 矩阵特征值的乘积等于矩阵行列式结果。
但是就像人无完人一样,判断矩阵完全符合一致性的可能性也比较小,所以能否尝试放松条件?答案那必须阔以哈!
思路如下:
- 如果判断矩阵为一致性矩阵,那么1个特征值就为矩阵的维数,其余特征值均为0。
- 但是现在上述情况不成立,可我们还是希望1个特征值尽可能接近矩阵的维数,其余接近0,如何衡量呢?我们的做法是将(最大特征值)- 特征值之和(矩阵维数)再除以(矩阵维数-1),记为C.I 作为检验判断矩阵一致性的指标。
- 可以看出C.I应该是越小越好。即分子越接近于0
根据上面的分析,我们知道,计算出这个矩阵的 C.I 然后再判断一致性即可!但又遇到了一个问题:就是C.I的计算结果和矩阵的维数是有关系的。
- 判断矩阵的阶数m越大,判断的主观因素造成的偏差越大,偏离一致性也就越大,反之,偏离一致性越小。
- 阶数m≤2时,C.I=0
- 基于上述两点原因,引入平均随机一致性指标R.I,随判断矩阵的阶数而变化。
故我们的一致性判别指标变成了:一致性指标C.I除以同阶随机一致性指标R.I的比值,称为一致性比率。
C.R = C.I / R.I
随机一致性指标R.I的取值见下方:

注:不同的地方对于这个R.I的取值稍有不同,不过影响不大!
具体到本案例,对于上面的判断矩阵,是否通过一致性的检验呢?检验的方法有两种:一种是Excel来判断,一种是Python来判断。
Python判断的思路:
- 首先求解判断矩阵的特征值
- 计算C.I 将 (最大特征值-维数) /(维数-1)
- 查表得R.I
- 计算C.R ,如果小于0.1,可视为通过一致性检验!否则不通过,继续调整判断矩阵。
import numpy as np
x = np.array([[1, 1/8, 1/5, 1/2, 1/8, 1/5, 1/2],
[8,1,1/2,1,1/2,1/2,1],
[5,2,1,1,1/2,1,1],
[2,1,1,1,1/4,1/2,1],
[8,2,2,4,1,0.5,1],
[5,2,1,2,2,1,1/2],
[2,1,1,1,1,2,1]])
x
array([[1. , 0.125, 0.2 , 0.5 , 0.125, 0.2 , 0.5 ],
[8. , 1. , 0.5 , 1. , 0.5 , 0.5 , 1. ],
[5. , 2. , 1. , 1. , 0.5 , 1. , 1. ],
[2. , 1. , 1. , 1. , 0.25 , 0.5 , 1. ],
[8. , 2. , 2. , 4. , 1. , 0.5 , 1. ],
[5. , 2. , 1. , 2. , 2. , 1. , 0.5 ],
[2. , 1. , 1. , 1. , 1. , 2. , 1. ]])
a,b=np.linalg.eig(x) ##特征值赋值给a,对应特征向量赋值给b
print(a)
print(b)
[ 7.66748795+0.j 0.03940202+1.87298751j 0.03940202-1.87298751j
0.05735978+1.26682712j 0.05735978-1.26682712j -0.59654648+0.j
-0.26446506+0.j ]
[[ 8.98495759e-02+0.j -1.18246709e-01-0.01263084j
-1.18246709e-01+0.01263084j 3.98351769e-04+0.13474951j
3.98351769e-04-0.13474951j -6.03676850e-02+0.j
3.56785054e-02+0.j ]
[ 3.09527955e-01+0.j -9.23924468e-02+0.3397639j
-9.23924468e-02-0.3397639j 6.18132774e-01+0.j
6.18132774e-01-0.j 1.47584293e-01+0.j
-3.38554025e-01+0.j ]
[ 3.70552823e-01+0.j 1.21048811e-01+0.01895149j
1.21048811e-01-0.01895149j 1.17043949e-01-0.54495727j
1.17043949e-01+0.54495727j 4.62647077e-02+0.j
6.66602397e-01+0.j ]
[ 2.45301866e-01+0.j -9.37531583e-02-0.05462322j
-9.37531583e-02+0.05462322j -2.36156222e-01-0.16043371j
-2.36156222e-01+0.16043371j -2.55128037e-01+0.j
-3.64760465e-01+0.j ]
[ 5.54526869e-01+0.j 1.25504484e-01+0.41339602j
1.25504484e-01-0.41339602j -3.92432327e-01+0.04185286j
-3.92432327e-01-0.04185286j 5.80407359e-01+0.j
4.49197914e-01+0.j ]
[ 4.85303610e-01+0.j 5.72831146e-01+0.j
5.72831146e-01-0.j -2.76707723e-02+0.02135125j
-2.76707723e-02-0.02135125j -5.82755720e-01+0.j
-3.07080830e-01+0.j ]
[ 3.94483785e-01+0.j 8.24130634e-02-0.55993026j
8.24130634e-02+0.55993026j -1.98177832e-01+0.10638157j
-1.98177832e-01-0.10638157j 4.80486159e-01+0.j
1.03062419e-01+0.j ]]
CI = (max(a) - x.shape[0]) / (x.shape[0]-1)
RI = 1.36
CR = CI / RI
if CR < 0.1:
print('判断矩阵x一致性检验通过, 值为 %.2f' % CR)
else:
print('一致性检验未通过,继续调整判断矩阵')
判断矩阵x一致性检验通过, 值为 0.08
/Users/apple/anaconda3/lib/python3.6/site-packages/ipykernel/__main__.py:5: ComplexWarning: Casting complex values to real discards the imaginary part
Excel判断的思路和上述Python类似,不过在Excel中进行求解判断的时候可以采用几种近似的方法进行处理,具体有根法,和法,幂法,具体可以参考:https://wenku.baidu.com/view/96cc92ac195f312b3069a54e.html
3.2.5 Step4 确定权重和最优方案
如何确定上述C21~C27 7个指标的权重呢?
- 根据递阶层次结构权重解析:将特征向量和特征值相乘,结果即为权重
import numpy as np
np.set_printoptions(suppress=True)
b
array([[ 0.08984958+0.j , -0.11824671-0.01263084j,
-0.11824671+0.01263084j, 0.00039835+0.13474951j,
0.00039835-0.13474951j, -0.06036768+0.j ,
0.03567851+0.j ],
[ 0.30952795+0.j , -0.09239245+0.3397639j ,
-0.09239245-0.3397639j , 0.61813277+0.j ,
0.61813277-0.j , 0.14758429+0.j ,
-0.33855403+0.j ],
[ 0.37055282+0.j , 0.12104881+0.01895149j,
0.12104881-0.01895149j, 0.11704395-0.54495727j,
0.11704395+0.54495727j, 0.04626471+0.j ,
0.6666024 +0.j ],
[ 0.24530187+0.j , -0.09375316-0.05462322j,
-0.09375316+0.05462322j, -0.23615622-0.16043371j,
-0.23615622+0.16043371j, -0.25512804+0.j ,
-0.36476046+0.j ],
[ 0.55452687+0.j , 0.12550448+0.41339602j,
0.12550448-0.41339602j, -0.39243233+0.04185286j,
-0.39243233-0.04185286j, 0.58040736+0.j ,
0.44919791+0.j ],
[ 0.48530361+0.j , 0.57283115+0.j ,
0.57283115-0.j , -0.02767077+0.02135125j,
-0.02767077-0.02135125j, -0.58275572+0.j ,
-0.30708083+0.j ],
[ 0.39448379+0.j , 0.08241306-0.55993026j,
0.08241306+0.55993026j, -0.19817783+0.10638157j,
-0.19817783-0.10638157j, 0.48048616+0.j ,
0.10306242+0.j ]])
w = np.dot(b,a)
print(w)
[0.41213046-0.j 1.16568062+0.j 3.97002508+0.j 2.70613214+0.j
2.09704971+0.j 4.13778295+0.j 4.52252119+0.j]
所以C21~C27对应的权重见上方!
结果很奇怪,试验一下其余的矩阵
x2 = np.array([[1,1/4,1/8],
[4,1,1/3],
[8,3,1]])
x2
array([[1. , 0.25 , 0.125 ],
[4. , 1. , 0.33333333],
[8. , 3. , 1. ]])
a,b=np.linalg.eig(x2) ##特征值赋值给a,对应特征向量赋值给b
print(a)
print(b)
[ 3.01829471+0.j -0.00914735+0.23480874j -0.00914735-0.23480874j]
[[ 0.1014959 +0.j 0.05074795+0.08789803j 0.05074795-0.08789803j]
[ 0.35465936+0.j 0.17732968-0.30714401j 0.17732968+0.30714401j]
[ 0.92947045+0.j -0.92947045+0.j -0.92947045-0.j ]]
w = np.dot(b,a)
(w/sum(w) )[0]
(0.0614556613808721+0j)
应该没啥问题。但不过Python结果还是有点奇怪,可以以下面这个Python版本为准!
3.3 Python实现
import numpy as np
# 建立平均随机一致性指标R.I
RI_dict = {1: 0, 2: 0, 3: 0.58, 4: 0.90, 5: 1.12, 6: 1.24, 7: 1.32, 8: 1.41, 9: 1.45, 10: 1.49}
def get_w(array):
print('' * 50)
print('*' * 50)
print('我是炫酷的分割线')
print('-' * 50)
print('' * 50)
# 1、计算出阶数 看这个数组是几维的 也就是后面对应字典查询!
row = array.shape[0]
# 2、按列求和
a_axis_0_sum = array.sum(axis=0)
# 3、得到新的矩阵b 就是把每一个数都除以列和
b = array / a_axis_0_sum
# 4、计算新矩阵b行和
b_axis_1_sum = b.sum(axis=1)
# 5、将b_axis_1_sum每一个值除以总和
W = b_axis_1_sum / sum(b_axis_1_sum)
# 6、将原始矩阵乘以W
a_W = np.dot(array, W)
# 7、求解最大特征值
lambda_max = 0
for i in range(len(a_W)):
lambda_max += (a_W[i] / W[i])
lambda_max = lambda_max / len(a_W)
# 8、检验判断矩阵的一致性
C_I = (lambda_max - row) / (row - 1)
R_I = RI_dict[row]
C_R = C_I / R_I
if C_R < 0.1:
print('矩阵 %s 一致性检验通过' % (array))
print('判断矩阵对应的指标的权重为:%s' % W)
print('判断矩阵对应的最大特征值为 %.2f' % lambda_max)
print('大功告成!!!')
return W
else:
print('矩阵 %s 一致性检验未通过,需要重新进行调整判断矩阵' % (array))
def main(array):
if type(array) is np.ndarray:
return get_w(array)
else:
print('请输入正确的numpy对象')
if __name__ == '__main__':
# 由于地方问题,矩阵我就写成一行了
# 检验以下判断矩阵的一致性并输出权重
a = np.array([[1, 1 / 3, 1 / 8], [3, 1, 1 / 3], [8, 3, 1]])
b = np.array([[1, 3, 6], [1 / 3, 1, 4], [1 / 5, 1 / 2, 1]])
c = np.array([[1, 1, 3], [1, 1, 3], [1 / 3, 1 / 3, 1]])
d = np.array([[1, 3, 4], [1 / 3, 1, 1], [1 / 4, 1, 1]])
e = np.array([[1, 2, 7, 5, 5], [1 / 2, 1, 4, 3, 3], [1 / 7, 1 / 4, 1, 1 / 2, 1 / 3], [1 / 5, 1 / 3, 2, 1, 1], [1 / 5, 1 / 3, 3, 1, 1]])
f = np.array([[1, 4, 1 / 2], [1 / 4, 1, 1 / 4], [2, 4, 1]])
main(a)
main(b)
main(c)
main(d)
main(e)
main(f)
**************************************************
我是炫酷的分割线
--------------------------------------------------
矩阵 [[1. 0.33333333 0.125 ]
[3. 1. 0.33333333]
[8. 3. 1. ]] 一致性检验通过
判断矩阵对应的指标的权重为:[0.08199023 0.23644689 0.68156288]
判断矩阵对应的最大特征值为 3.00
大功告成!!!
**************************************************
我是炫酷的分割线
--------------------------------------------------
矩阵 [[1. 3. 6. ]
[0.33333333 1. 4. ]
[0.2 0.5 1. ]] 一致性检验未通过,需要重新进行调整判断矩阵
**************************************************
我是炫酷的分割线
--------------------------------------------------
矩阵 [[1. 1. 3. ]
[1. 1. 3. ]
[0.33333333 0.33333333 1. ]] 一致性检验通过
判断矩阵对应的指标的权重为:[0.42857143 0.42857143 0.14285714]
判断矩阵对应的最大特征值为 3.00
大功告成!!!
**************************************************
我是炫酷的分割线
--------------------------------------------------
矩阵 [[1. 3. 4. ]
[0.33333333 1. 1. ]
[0.25 1. 1. ]] 一致性检验通过
判断矩阵对应的指标的权重为:[0.63274854 0.19239766 0.1748538 ]
判断矩阵对应的最大特征值为 3.01
大功告成!!!
**************************************************
我是炫酷的分割线
--------------------------------------------------
矩阵 [[1. 2. 7. 5. 5. ]
[0.5 1. 4. 3. 3. ]
[0.14285714 0.25 1. 0.5 0.33333333]
[0.2 0.33333333 2. 1. 1. ]
[0.2 0.33333333 3. 1. 1. ]] 一致性检验通过
判断矩阵对应的指标的权重为:[0.47439499 0.26228108 0.0544921 0.09853357 0.11029827]
判断矩阵对应的最大特征值为 5.07
大功告成!!!
**************************************************
我是炫酷的分割线
--------------------------------------------------
矩阵 [[1. 4. 0.5 ]
[0.25 1. 0.25]
[2. 4. 1. ]] 一致性检验通过
判断矩阵对应的指标的权重为:[0.34595035 0.11029711 0.54375254]
判断矩阵对应的最大特征值为 3.05
大功告成!!!
main(x)
**************************************************
我是炫酷的分割线
--------------------------------------------------
矩阵 [[1. 0.125 0.2 0.5 0.125 0.2 0.5 ]
[8. 1. 0.5 1. 0.5 0.5 1. ]
[5. 2. 1. 1. 0.5 1. 1. ]
[2. 1. 1. 1. 0.25 0.5 1. ]
[8. 2. 2. 4. 1. 0.5 1. ]
[5. 2. 1. 2. 2. 1. 0.5 ]
[2. 1. 1. 1. 1. 2. 1. ]] 一致性检验通过
判断矩阵对应的指标的权重为:[0.03787191 0.12641825 0.15144125 0.10278494 0.22816213 0.19300904
0.16031248]
判断矩阵对应的最大特征值为 7.67
大功告成!!!
array([0.03787191, 0.12641825, 0.15144125, 0.10278494, 0.22816213,
0.19300904, 0.16031248])
main(x2)
**************************************************
我是炫酷的分割线
--------------------------------------------------
矩阵 [[1. 0.25 0.125 ]
[4. 1. 0.33333333]
[8. 3. 1. ]] 一致性检验通过
判断矩阵对应的指标的权重为:[0.0738203 0.25718595 0.66899375]
判断矩阵对应的最大特征值为 3.02
大功告成!!!
array([0.0738203 , 0.25718595, 0.66899375])
3.3.1 直接将打分ok的excel表格读入并进行一致性检验以及权重的计算
import pandas as pd
df = pd.read_excel('data/层次分析法打分表.xlsx', sheet_name='Sheet2')
df
| C21 | C22 | C23 | C24 | C25 | C26 | C27 | |
|---|---|---|---|---|---|---|---|
| C21 | 1 | 0.125 | 0.2 | 0.5 | 0.125 | 0.2 | 0.5 |
| C22 | 8 | 1.000 | 0.5 | 1.0 | 0.500 | 0.5 | 1.0 |
| C23 | 5 | 2.000 | 1.0 | 1.0 | 0.500 | 1.0 | 1.0 |
| C24 | 2 | 1.000 | 1.0 | 1.0 | 0.250 | 0.5 | 1.0 |
| C25 | 8 | 2.000 | 2.0 | 4.0 | 1.000 | 0.5 | 1.0 |
| C26 | 5 | 2.000 | 1.0 | 2.0 | 2.000 | 1.0 | 0.5 |
| C27 | 2 | 1.000 | 1.0 | 1.0 | 1.000 | 2.0 | 1.0 |
df_array = np.array(df)
df_array
array([[1. , 0.125, 0.2 , 0.5 , 0.125, 0.2 , 0.5 ],
[8. , 1. , 0.5 , 1. , 0.5 , 0.5 , 1. ],
[5. , 2. , 1. , 1. , 0.5 , 1. , 1. ],
[2. , 1. , 1. , 1. , 0.25 , 0.5 , 1. ],
[8. , 2. , 2. , 4. , 1. , 0.5 , 1. ],
[5. , 2. , 1. , 2. , 2. , 1. , 0.5 ],
[2. , 1. , 1. , 1. , 1. , 2. , 1. ]])
main(df_array)
**************************************************
我是炫酷的分割线
--------------------------------------------------
矩阵 [[1. 0.125 0.2 0.5 0.125 0.2 0.5 ]
[8. 1. 0.5 1. 0.5 0.5 1. ]
[5. 2. 1. 1. 0.5 1. 1. ]
[2. 1. 1. 1. 0.25 0.5 1. ]
[8. 2. 2. 4. 1. 0.5 1. ]
[5. 2. 1. 2. 2. 1. 0.5 ]
[2. 1. 1. 1. 1. 2. 1. ]] 一致性检验通过
判断矩阵对应的指标的权重为:[0.03787191 0.12641825 0.15144125 0.10278494 0.22816213 0.19300904
0.16031248]
判断矩阵对应的最大特征值为 7.67
大功告成!!!
array([0.03787191, 0.12641825, 0.15144125, 0.10278494, 0.22816213,
0.19300904, 0.16031248])
3.4 Excel实现
这个可以见附件上传数据,均为简单excel函数,近似求解特征值和特征向量,不难。
3.5 如何得到总权重
这个得看具体需求是否需要。
- 已经计算出二级指标对应权重
- 已经计算出二级指标下对应的三级指标对应权重
- 如果需要考虑三级指标的整体权重,把二级权重×三级权重即可!这样的目的就是所有指标的权重之和为1!
4 参考
- https://wiki.mbalib.com/wiki/层次分析法
- https://blog.csdn.net/jiangzhouyue/article/details/52926039
- https://wenku.baidu.com/view/96cc92ac195f312b3069a54e.html
- https://wenku.baidu.com/view/ea612a7c31b765ce05081473.html
5 附录:AHP层次分析法的Excel版本实现
注:一般实际业务场景中,用Excel版本的AHP会更加实用,上面的Python版本仅作为验证以及练习。原因如下:
- Excel中一旦专家将分数打完之后,会出一个R.I结果,如果大于0.1,可以自行调整判断矩阵,直至符合条件为止
- Excel进行操作易于专家打分以及结果汇总。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









