







LLama
论文
模型结构
LLAMA网络基于 Transformer 架构。提出了各种改进,并用于不同的模型,例如 PaLM。以下是与原始架构的主要区别: 预归一化。为了提高训练稳定性,对每个transformer 子层的输入进行归一化,而不是对输出进行归一化。使用 RMSNorm 归一化函数。 SwiGLU 激活函数 [PaLM]。使用 SwiGLU 激活函数替换 ReLU 非线性以提高性能。使用 2 /3 4d 的维度而不是 PaLM 中的 4d。 旋转嵌入。移除了绝对位置嵌入,而是添加了旋转位置嵌入 (RoPE),在网络的每一层。
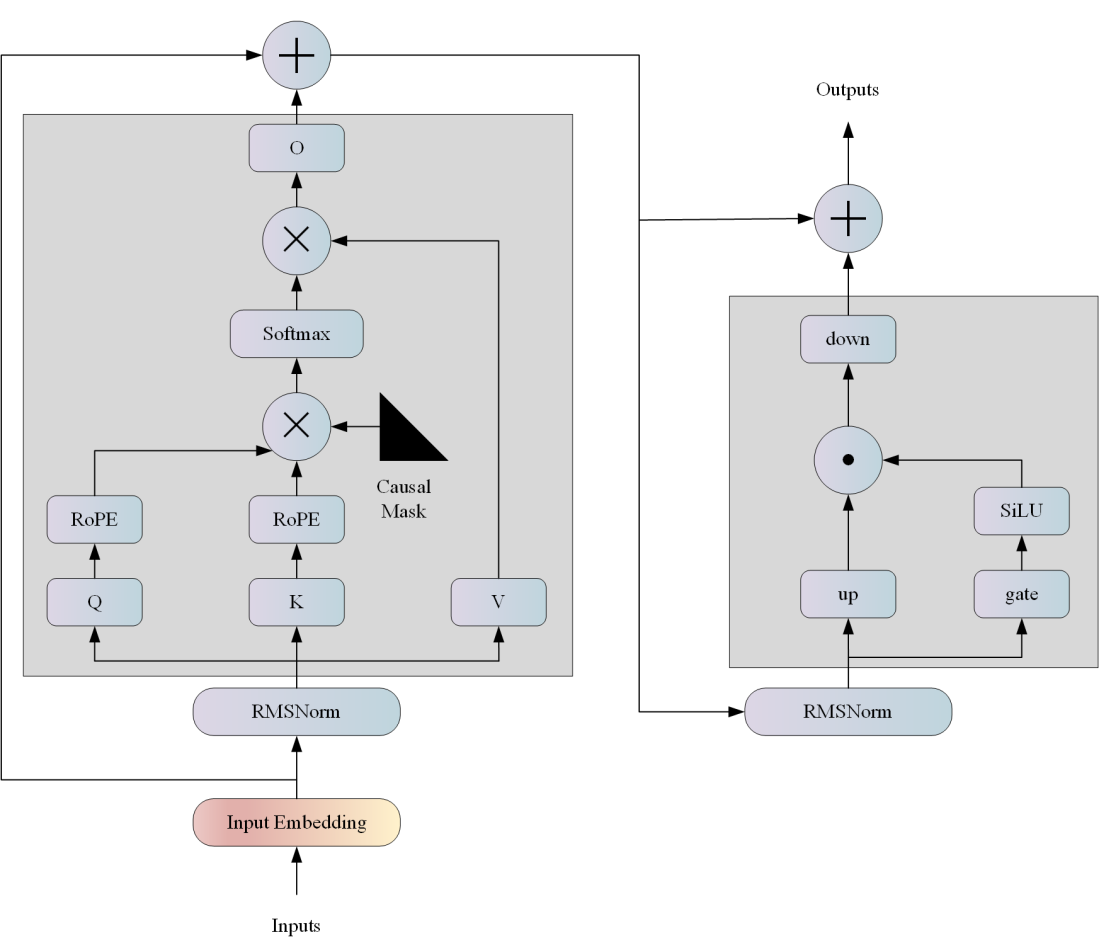
算法原理
LLama是一个基础语言模型的集合,参数范围从7B到65B。在数万亿的tokens上训练出的模型,并表明可以专门使用公开可用的数据集来训练最先进的模型,而不依赖于专有的和不可访问的数据集。
环境配置
提供光源拉取推理的docker镜像:
docker pull image.sourcefind.cn:5000/dcu/admin/base/custom:lmdeploy0.0.13_dtk23.04_torch1.13_py38
# <Image ID>用上面拉取docker镜像的ID替换
# <Host Path>主机端路径
# <Container Path>容器映射路径
docker run -it --name llama --shm-size=1024G --device=/dev/kfd --device=/dev/dri/ --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --ulimit memlock=-1:-1 --ipc=host --network host --group-add video -v <Host Path>:<Container Path> <Image ID> /bin/bash
镜像版本依赖:
- DTK驱动:dtk23.04
- Pytorch: 1.13
- python: python3.8
数据集
无
推理
源码编译安装
# 若使用光源的镜像,可以跳过源码编译安装,镜像里面安装好了lmdeploy。
git clone http://developer.hpccube.com/codes/modelzoo/llama_lmdeploy.git
cd llama_lmdeploy
git submodule init && git submodule update
cd lmdeploy
mkdir build && cd build
sh ../generate.sh
make -j 32
make install
cd .. && python3 setup.py install
模型下载
支持模型包括:LLama-7B、LLama-13B、LLama-30B、LLama-65B、LLama2-7B、LLama2-13B、LLama2-70B
运行 LLama-7b
# 模型转换
# <model_name> 模型的名字 ('llama', 'internlm', 'vicuna', 'internlm-chat-7b', 'internlm-chat', 'internlm-chat-7b-8k', 'internlm-chat-20b', 'internlm-20b', 'baichuan-7b', 'baichuan2-7b', 'llama2', 'qwen-7b', 'qwen-14b')
# <model_path> 模型路径
# <model_format> 模型的格式 ('llama', 'hf', 'qwen')
# <tokenizer_path> tokenizer模型的路径(默认None,会去model_path里面找qwen.tiktoken)
# <model_format> 保存输出的目标路径(默认./workspace)
# <tp> 用于张量并行的GPU数量应该是2^n
lmdeploy convert --model_name llama --model_path /path/to/model --model_format hf --tokenizer_path None --dst_path ./workspace_llama7b --tp 1
# bash界面运行
lmdeploy chat turbomind --model_path ./workspace_llama7b --tp 1 # 输入问题后执行2次回车进行推理
# 服务器网页端运行
在bash端运行:
# <model_path_or_server> 部署模型的路径或tritonserver URL或restful api URL。前者用于与gradio直接运行服务。后者用于默认情况下使用tritonserver运行。如果输入URL是restful api。请启用另一个标志“restful_api”。
# <server_name> gradio服务器的ip地址
# <server_port> gradio服务器的ip的端口
# <batch_size> 于直接运行Turbomind的batch大小 (默认32)
# <tp> 用于张量并行的GPU数量应该是2^n (和模型转换的时候保持一致)
# <restful_api> modelpath_or_server的标志(默认是False)
lmdeploy serve gradio --model_path_or_server ./workspace_llama7b --server_name {ip} --server_port {pord} --batch_size 32 --tp 1 --restful_api False
在网页上输入{ip}:{pord}即可进行对话
运行 LLama-13b
# 模型转换
lmdeploy convert --model_name llama --model_path /path/to/model --model_format hf --tokenizer_path None --dst_path ./workspace_llama13b --tp 1
# bash界面运行
lmdeploy chat turbomind --model_path ./workspace_llama13b --tp 1
# 服务器网页端运行
在bash端运行:
lmdeploy serve gradio --model_path_or_server ./workspace_llama13b --server_name {ip} --server_port {pord} --batch_size 32 --tp 1 --restful_api False
在网页上输入{ip}:{pord}即可进行对话
运行 LLama-33b
# 模型转换
lmdeploy convert --model_name llama --model_path /path/to/model --model_format hf --tokenizer_path None --dst_path ./workspace_llama33b --tp 4
# bash界面运行
lmdeploy chat turbomind --model_path ./workspace_llama33b --tp 4
# 服务器网页端运行
在bash端运行:
lmdeploy serve gradio --model_path_or_server ./workspace_llama33b --server_name {ip} --server_port {pord} --batch_size 32 --tp 4 --restful_api False
在网页上输入{ip}:{pord}即可进行对话
运行 LLama-65b
# 模型转换
lmdeploy convert --model_name llama --model_path /path/to/model --model_format hf --tokenizer_path None --dst_path ./workspace_llama65b --tp 8
# bash界面运行
lmdeploy chat turbomind --model_path ./workspace_llama65b --tp 8
# 服务器网页端运行
在bash端运行:
lmdeploy serve gradio --model_path_or_server ./workspace_llama65b --server_name {ip} --server_port {pord} --batch_size 32 --tp 8 --restful_api False
在网页上输入{ip}:{pord}即可进行对话
运行 LLama2-7b
# 模型转换
lmdeploy convert --model_name llama2 --model_path /path/to/model --model_format hf --tokenizer_path None --dst_path ./workspace_llama2-7b --tp 1
# bash界面运行
lmdeploy chat turbomind --model_path ./workspace_llama2-7b --tp 1
# 服务器网页端运行
在bash端运行:
lmdeploy serve gradio --model_path_or_server ./workspace_llama2-7b --server_name {ip} --server_port {pord} --batch_size 32 --tp 1 --restful_api False
在网页上输入{ip}:{pord}即可进行对话
运行 LLama2-13b
# 模型转换
lmdeploy convert --model_name llama2 --model_path /path/to/model --model_format hf --tokenizer_path None --dst_path ./workspace_llama2-13b --tp 1
# bash界面运行
lmdeploy chat turbomind --model_path ./workspace_llama2-13b --tp 1
# 服务器网页端运行
在bash端运行:
lmdeploy serve gradio --model_path_or_server ./workspace_llama2-13b --server_name {ip} --server_port {pord} --batch_size 32 --tp 1 --restful_api False
在网页上输入{ip}:{pord}即可进行对话
运行 LLama2-70b
# 模型转换
lmdeploy convert --model_name llama2 --model_path /path/to/model --model_format hf --tokenizer_path None --dst_path ./workspace_llama2-70b --tp 8
# bash界面运行
lmdeploy chat turbomind --model_path ./workspace_llama2-70b --tp 8
# 服务器网页端运行
在bash端运行:
lmdeploy serve gradio --model_path_or_server ./workspace_llama2-70b --server_name {ip} --server_port {pord} --batch_size 32 --tp 8 --restful_api False
在网页上输入{ip}:{pord}即可进行对话
result
精度
无
应用场景
算法类别
对话问答
热点应用行业
金融,科研,教育
源码仓库及问题反馈
ModelZoo / LLama_lmdeploy · GitLab
参考资料
GitHub - InternLM/lmdeploy: LMDeploy is a toolkit for compressing, deploying, and serving LLMs.

















 846
846

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











