







LLAMA
论文
模型结构
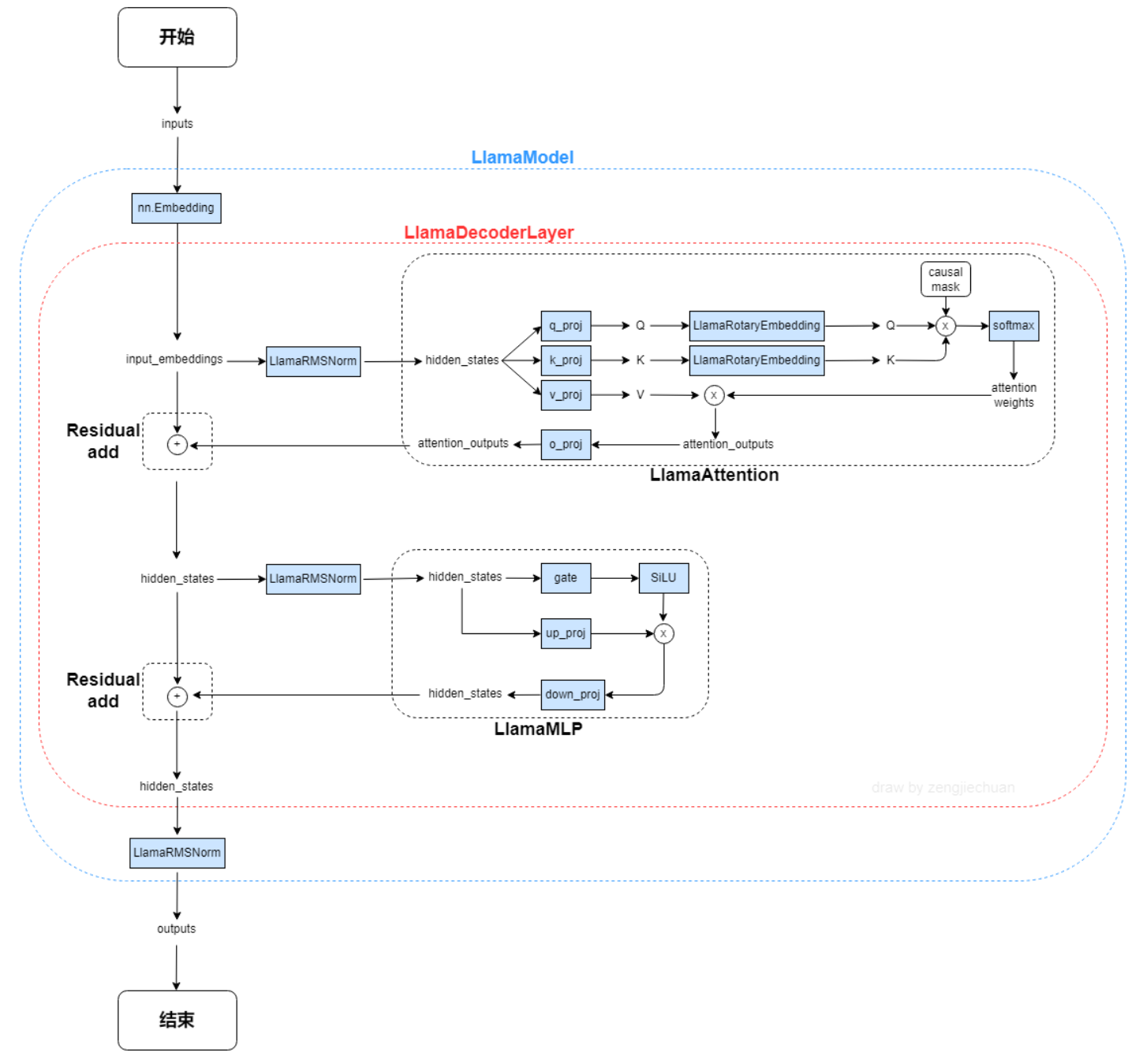
LLAMA网络基于 Transformer 架构。提出了各种改进,并用于不同的模型,例如 PaLM。以下是与原始架构的主要区别: 预归一化。为了提高训练稳定性,对每个transformer 子层的输入进行归一化,而不是对输出进行归一化。使用 RMSNorm 归一化函数。 SwiGLU 激活函数 [PaLM]。使用 SwiGLU 激活函数替换 ReLU 非线性以提高性能。使用 2 /3 4d 的维度而不是 PaLM 中的 4d。 旋转嵌入。移除了绝对位置嵌入,而是添加了旋转位置嵌入 (RoPE),在网络的每一层。
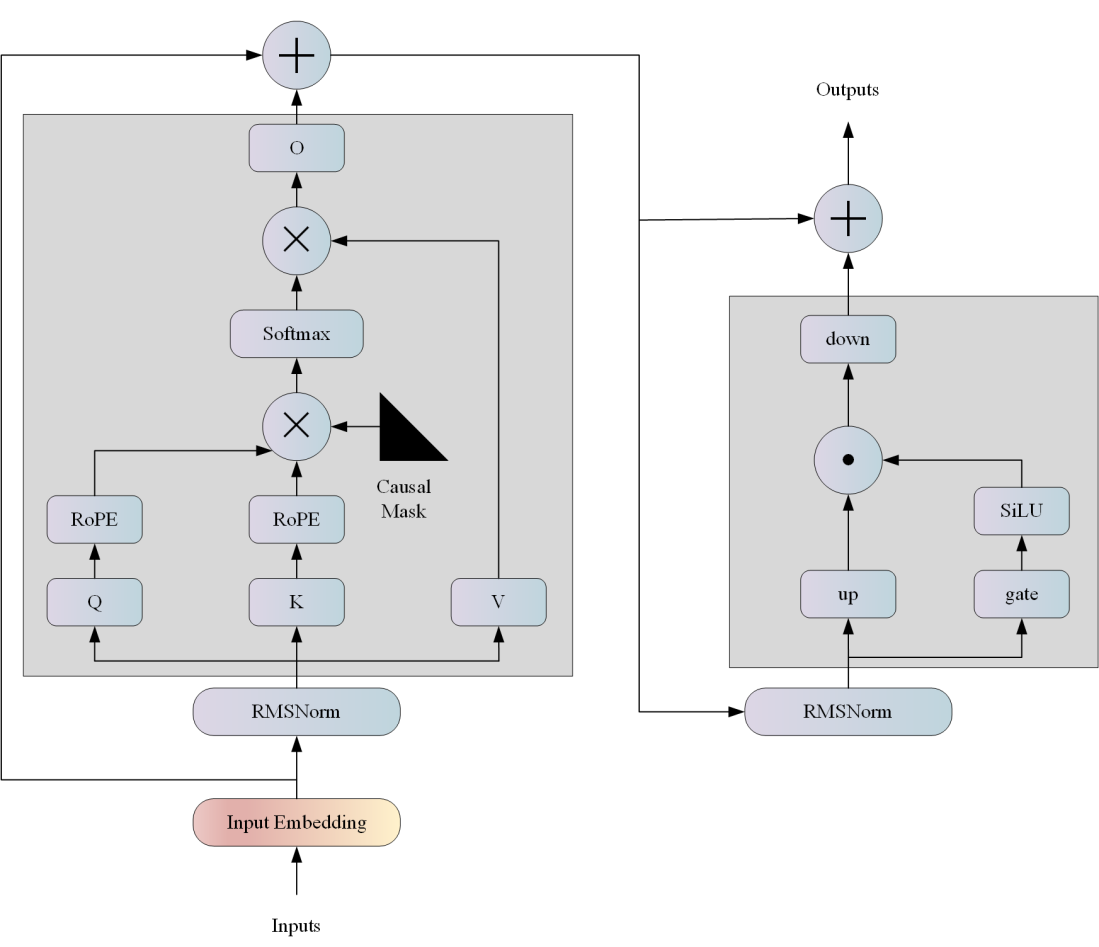
算法原理
LLama是一个基础语言模型的集合,参数范围从7B到65B。在数万亿的tokens上训练出的模型,并表明可以专门使用公开可用的数据集来训练最先进的模型,而不依赖于专有的和不可访问的数据集。
环境配置
Docker(方法一)
提供光源拉取推理的docker镜像:
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.1-py3.10
# <Image ID>用上面拉取docker镜像的ID替换
# <Host Path>主机端路径
# <Container Path>容器映射路径
docker run -it --name llama_vllm --privileged --shm-size=64G --device=/dev/kfd --device=/dev/dri/ --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --ulimit memlock=-1:-1 --ipc=host --network host --group-add video -v /opt/hyhal:/opt/hyhal -v <Host Path>:<Container Path> <Image ID> /bin/bash
pip install aiohttp==3.9.1 outlines==0.0.37 openai==1.23.3 -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
Tips:若在K100/Z100L上使用,需要替换flash_attn,下载链接:https://forum.hpccube.com/thread/515
Dockerfile(方法二)
# <Host Path>主机端路径
# <Container Path>容器映射路径
docker build -t llama:latest .
docker run -it --name llama_vllm --privileged --shm-size=64G --device=/dev/kfd --device=/dev/dri/ --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --ulimit memlock=-1:-1 --ipc=host --network host --group-add video -v /opt/hyhal:/opt/hyhal -v <Host Path>:<Container Path> llama:latest /bin/bash
Tips:若在K100/Z100L上使用,需要替换flash_attn,下载链接:https://forum.hpccube.com/thread/515
Anaconda(方法三)
conda create -n llama_vllm python=3.10
pip install aiohttp==3.9.1 outlines==0.0.37 openai==1.23.3
关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装。
- DTK驱动:dtk24.04.1
- Pytorch: 2.1.0
- triton:2.1.0
- vllm: 0.3.3
- xformers: 0.0.25
- flash_attn: 2.0.4
- python: python3.10
Tips:若在K100/Z100L上使用,需要替换flash_attn,下载链接:https://forum.hpccube.com/thread/515
数据集
无
推理
源码编译安装
# 若使用光源的镜像,可以跳过源码编译安装,镜像中已安装vllm。
git clone http://developer.hpccube.com/codes/modelzoo/llama_vllm.git
cd llama_vllm
git submodule init && git submodule update
cd vllm
pip install wheel
python setup.py bdist_wheel
cd dist && pip install vllm*
模型下载
快速下载通道:
离线批量推理
python vllm/examples/offline_inference.py
其中,prompts为提示词;temperature为控制采样随机性的值,值越小模型生成越确定,值变高模型生成更随机,0表示贪婪采样,默认为1;max_tokens=16为生成长度,默认为1; model为模型路径;tensor_parallel_size=1为使用卡数,默认为1;dtype="float16"为推理数据类型,如果模型权重是bfloat16,需要修改为float16推理,quantization="gptq"为使用gptq量化进行推理,需下载以上GPTQ模型。
离线批量推理性能测试
1、指定输入输出
python vllm/benchmarks/benchmark_throughput.py --num-prompts 1 --input-len 32 --output-len 128 --model meta-llama/Llama-2-7b-chat-hf -tp 1 --trust-remote-code --enforce-eager --dtype float16
其中--num-prompts是batch数,--input-len是输入seqlen,--output-len是输出token长度,--model为模型路径,-tp为使用卡数,dtype="float16"为推理数据类型,如果模型权重是bfloat16,需要修改为float16推理。若指定--output-len 1即为首字延迟。-q gptq为使用gptq量化模型进行推理。
2、使用数据集 下载数据集:
wget https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json
python vllm/benchmarks/benchmark_throughput.py --num-prompts 1 --model meta-llama/Llama-2-7b-chat-hf --dataset ShareGPT_V3_unfiltered_cleaned_split.json -tp 1 --trust-remote-code --enforce-eager --dtype float16
其中--num-prompts是batch数,--model为模型路径,--dataset为使用的数据集,-tp为使用卡数,dtype="float16"为推理数据类型,如果模型权重是bfloat16,需要修改为float16推理。-q gptq为使用gptq量化模型进行推理。
api服务推理性能测试
1、启动服务端:
python -m vllm.entrypoints.api_server --model meta-llama/Llama-2-7b-chat-hf --dtype float16 --enforce-eager -tp 1
2、启动客户端:
python vllm/benchmarks/benchmark_serving.py --model meta-llama/Llama-2-7b-chat-hf --dataset ShareGPT_V3_unfiltered_cleaned_split.json --num-prompts 1 --trust-remote-code
参数同使用数据集,离线批量推理性能测试,具体参考[vllm/benchmarks/benchmark_serving.py]
OpenAI兼容服务
启动服务:
python -m vllm.entrypoints.openai.api_server --model meta-llama/Llama-2-7b-chat-hf --enforce-eager --dtype float16 --trust-remote-code
这里--model为加载模型路径,--dtype为数据类型:float16,默认情况使用tokenizer中的预定义聊天模板,--chat-template可以添加新模板覆盖默认模板,-q gptq为使用gptq量化模型进行推理。
列出模型型号:
curl http://localhost:8000/v1/models
OpenAI Completions API和vllm结合使用
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "meta-llama/Llama-2-7b-hf",
"prompt": "I believe the meaning of life is",
"max_tokens": 7,
"temperature": 0
}'
或者使用vllm/examples/openai_completion_client.py
OpenAI Chat API和vllm结合使用
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "meta-llama/Llama-2-7b-chat-hf",
"messages": [
{"role": "system", "content": "I believe the meaning of life is"},
{"role": "user", "content": "I believe the meaning of life is"}
]
}'
或者使用vllm/examples/openai_chatcompletion_client.py
result
使用的加速卡:1张 DCU-K100_AI-64G
Prompt: 'I believe the meaning of life is', Generated text: ' to find purpose, happiness, and fulfillment. Here are some reasons why:\n\n1. Purpose: Having a sense of purpose gives life meaning and direction. It helps individuals set goals and work towards achieving them, which can lead to a sense of accomplishment and fulfillment.\n2. Happiness: Happiness is a fundamental aspect of life that brings joy and satisfaction.
精度
无
应用场景
算法类别
对话问答
热点应用行业
金融,科研,教育

















 1185
1185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











