






What is Machine Learning?
data + model ⇒ prediction \text{data} + \text{model} \rArr \text{prediction} data+model⇒prediction
-
data
\text{data}
data : observations, could be actively or passively
acquired (meta-data). -
model
\text{model}
model : assumptions, based on previous experience (other data!
transfer learning etc), or beliefs about the regularities of
the universe. Inductive bias. -
prediction
\text{prediction}
prediction : an action to be taken or a categorization or a
quality score.
Two important Gaussian Properties
-
Sum of Gaussianv
Sum of Gaussian variables is also Gaussian.
y i ∼ N ( μ i , σ i 2 ) y_{i} \sim \mathcal{N}(\mu_{i},\sigma_{i}^{2}) yi∼N(μi,σi2)
And the sum is distributed as
∑ y i ∼ N ( ∑ μ i , ∑ σ i 2 ) \sum y_{i} \sim \mathcal{N}(\sum \mu_{i},\sum \sigma_{i}^{2}) ∑yi∼N(∑μi,∑σi2)
Aside: As sum increase, sum of non-Gaussian, finite variance variables is also Gaussian because of central limit theorem.
-
Scaling a Gaussian
Scaling a Gaussian leads to a Gaussian.ω ∗ y ∼ N ( ω μ , ω 2 σ 2 ) \omega*y \sim \mathcal{N}(\omega \mu, \omega^{2}\sigma^{2}) ω∗y∼N(ωμ,ω2σ2)
The central limit theorem (CLT) establishes that, in some situations, when independent random variables are added, their properly normalized sum tends toward a normal distribution (informally a “bell curve”) even if the original variables themselves are not normally distributed.
Prior Distribution
- Bayesian inference requires a prior on the parameters.
- The prior represents your belief before you see the data of the
likely value of the parameters. - For linear regression, consider a Gaussian prior on the intercept:
c ∼ N ( 0 , α 1 ) c\sim \mathcal{N}(0, \alpha_1) c∼N(0,α1)
Posterior Distribution
- Posterior distribution is found by combining the prior with
the likelihood. - Posterior distribution is your belief after you see the data of
the likely value of the parameters. - The posterior is found through Bayes’ Rule
p ( c ∣ y ) = p ( y ∣ c ) p ( c ) p ( y ) p(c|y) = \frac{p(y|c)p(c)}{p(y)} p(c∣y)=p(y)p(y∣c)p(c)
The p ( y ∣ c ) p(y|c) p(y∣c) likelihood is not a density over c c c, it’s a function of c c c. Here, c c c is a parameter of this density. The normalization step, e.g. find the suitable way to compute the p ( y ) p(y) p(y) is the most difficult setp.
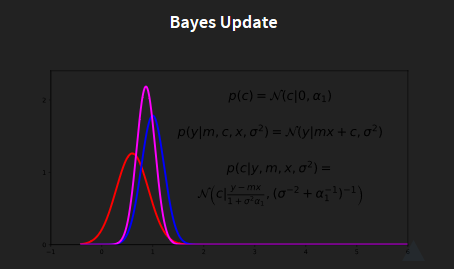
The red line describe the probablity for
c
c
c with:
p
(
c
)
=
N
(
c
∣
0
,
α
1
)
p(c) = \mathcal{N}(c | 0,\alpha_{1})
p(c)=N(c∣0,α1)
the blue line stands for the observation, with:
p
(
y
∣
m
,
c
,
x
,
σ
2
)
=
N
(
y
∣
m
x
+
c
,
σ
2
)
p(y|m,c,x,\sigma^{2}) = \mathcal{N}(y|mx+c,\sigma^{2})
p(y∣m,c,x,σ2)=N(y∣mx+c,σ2)
Note that, this is a likelihood function over
c
c
c not a distribution.
based on the bayes’rule, the posterior could be written as:
P
(
c
∣
y
,
m
,
x
,
σ
2
)
=
N
(
c
∣
y
−
m
x
1
+
σ
2
α
,
(
σ
−
2
+
α
1
−
1
)
−
1
)
P(c|y,m,x,\sigma^{2}) = \mathcal{N}(c|\frac{y-mx}{1+\sigma^{2}}\alpha,(\sigma^{-2}+\alpha_{1}^{-1})^{-1})
P(c∣y,m,x,σ2)=N(c∣1+σ2y−mxα,(σ−2+α1−1)−1)
Math Trick:
p
(
c
)
=
1
2
π
α
1
exp
(
−
1
2
α
1
c
2
)
p(c) = \frac{1}{\sqrt{2\pi\alpha_1}} \exp\left(-\frac{1}{2\alpha_1}c^2\right)
p(c)=2πα11exp(−2α11c2)
p
(
y
∣
x
,
c
,
m
,
σ
2
)
=
1
(
2
π
σ
2
)
n
2
exp
(
−
1
2
σ
2
∑
i
=
1
n
(
y
i
−
m
x
i
−
c
)
2
)
p(\mathbf{y}|\mathbf{x}, c, m, \sigma^2) = \frac{1}{\left(2\pi\sigma^2\right)^{\frac{n}{2}}} \exp\left(-\frac{1}{2\sigma^2}\sum_{i=1}^n(y_i - mx_i - c)^2\right)
p(y∣x,c,m,σ2)=(2πσ2)2n1exp(−2σ21i=1∑n(yi−mxi−c)2)
p
(
c
∣
y
,
x
,
m
,
σ
2
)
=
p
(
y
∣
x
,
c
,
m
,
σ
2
)
p
(
c
)
p
(
y
∣
x
,
m
,
σ
2
)
p(c| \mathbf{y}, \mathbf{x}, m, \sigma^2) = \frac{p(\mathbf{y}|\mathbf{x}, c, m, \sigma^2)p(c)}{p(\mathbf{y}|\mathbf{x}, m, \sigma^2)}
p(c∣y,x,m,σ2)=p(y∣x,m,σ2)p(y∣x,c,m,σ2)p(c)
p
(
c
∣
y
,
x
,
m
,
σ
2
)
=
p
(
y
∣
x
,
c
,
m
,
σ
2
)
p
(
c
)
∫
p
(
y
∣
x
,
c
,
m
,
σ
2
)
p
(
c
)
d
c
p(c| \mathbf{y}, \mathbf{x}, m, \sigma^2) = \frac{p(\mathbf{y}|\mathbf{x}, c, m, \sigma^2)p(c)}{\int p(\mathbf{y}|\mathbf{x}, c, m, \sigma^2)p(c) \text{d} c}
p(c∣y,x,m,σ2)=∫p(y∣x,c,m,σ2)p(c)dcp(y∣x,c,m,σ2)p(c)
p
(
c
∣
y
,
x
,
m
,
σ
2
)
∝
p
(
y
∣
x
,
c
,
m
,
σ
2
)
p
(
c
)
p(c| \mathbf{y}, \mathbf{x}, m, \sigma^2) \propto p(\mathbf{y}|\mathbf{x}, c, m, \sigma^2)p(c)
p(c∣y,x,m,σ2)∝p(y∣x,c,m,σ2)p(c)
log p ( c ∣ y , x , m , σ 2 ) = − 1 2 σ 2 ∑ i = 1 n ( y i − c − m x i ) 2 − 1 2 α 1 c 2 + const = − 1 2 σ 2 ∑ i = 1 n ( y i − m x i ) 2 − ( n 2 σ 2 + 1 2 α 1 ) c 2 + c ∑ i = 1 n ( y i − m x i ) σ 2 , \begin{aligned} \log p(c | \mathbf{y}, \mathbf{x}, m, \sigma^2) =&-\frac{1}{2\sigma^2} \sum_{i=1}^n(y_i-c - mx_i)^2-\frac{1}{2\alpha_1} c^2 + \text{const}\\ = &-\frac{1}{2\sigma^2}\sum_{i=1}^n(y_i-mx_i)^2 -\left(\frac{n}{2\sigma^2} + \frac{1}{2\alpha_1}\right)c^2\\ & + c\frac{\sum_{i=1}^n(y_i-mx_i)}{\sigma^2}, \end{aligned} logp(c∣y,x,m,σ2)==−2σ21i=1∑n(yi−c−mxi)2−2α11c2+const−2σ21i=1∑n(yi−mxi)2−(2σ2n+2α11)c2+cσ2∑i=1n(yi−mxi),
complete the square of the quadratic form to obtain
log
p
(
c
∣
y
,
x
,
m
,
σ
2
)
=
−
1
2
τ
2
(
c
−
μ
)
2
+
const
\log p(c | \mathbf{y}, \mathbf{x}, m, \sigma^2) = -\frac{1}{2\tau^2}(c - \mu)^2 +\text{const}
logp(c∣y,x,m,σ2)=−2τ21(c−μ)2+const
where
τ
2
=
(
n
σ
−
2
+
α
1
−
1
)
−
1
\tau^2 = \left(n\sigma^{-2} +\alpha_1^{-1}\right)^{-1}
τ2=(nσ−2+α1−1)−1
and
μ = τ 2 σ 2 ∑ i = 1 n ( y i − m x i ) \mu = \frac{\tau^2}{\sigma^2} \sum_{i=1}^n(y_i-mx_i) μ=σ2τ2∑i=1n(yi−mxi).
Piror comes from the model, where we think about it. And likelihood is coming from the data.
Stages to Derivation of the Posterior
- Multiply likelihood by prior
- they are “exponentiated quadratics”, the answer is always also an exponentiated quadratic because
exp ( a 2 ) exp ( b 2 ) = exp ( a 2 + b 2 ) \exp(a^2)\exp(b^2) = \exp(a^2 + b^2) exp(a2)exp(b2)=exp(a2+b2)
- they are “exponentiated quadratics”, the answer is always also an exponentiated quadratic because
- Complete the square to get the resulting density in the form of a Gaussian.
- Recognise the mean and (co)variance of the Gaussian. This is the estimate of the posterior.
Multivariate Regression Likelihood
- Noise corrupted data point
y i = w T X i , : + ϵ i y_{i} = \mathcal{w}^{T}X_{i,:}+\epsilon_{i} yi=wTXi,:+ϵi - Multivariate regression likelihood:
p ( y ∣ X , w ) = 1 ( 2 π σ 2 ) e x p ( − 1 2 σ 2 ∑ ( y i − w T x i , : ) 2 ) p(y|X,w)=\frac{1}{(2\pi\sigma^{2})}exp(-\frac{1}{2\sigma^{2}}\sum(y_{i}-w^{T}x_{i,:})^2) p(y∣X,w)=(2πσ2)1exp(−2σ21∑(yi−wTxi,:)2) - Multivariate Gaussian piroi:
p ( w ) = 1 ( 2 π σ 2 ) p / 2 e x p ( − 1 2 σ 2 w T w ) p(w)=\frac{1}{(2\pi\sigma^{2})^{p/2}}exp(-\frac{1}{2\sigma^{2}}w^{T}w) p(w)=(2πσ2)p/21exp(−2σ21wTw)
The independent multivariate Gaussian could be seen as the independent Gaussian and multiple them and rotate the results.
Independent Gaussians:
p ( w , h ) = 1 2 π α 1 2 π α 2 exp ( − 1 2 ( ( w − μ 1 ) 2 σ 1 2 + ( h − μ 2 ) 2 σ 2 2 ) ) p(w,h)=\frac{1}{\sqrt{2\pi\alpha_1}\sqrt{2\pi\alpha_2}} \exp(-\frac{1}{2}(\frac{(w-\mu_1)^2}{\sigma_1^2}+\frac{(h-\mu_2)^2}{\sigma_2^2})) p(w,h)=2πα12πα21exp(−21(σ12(w−μ1)2+σ22(h−μ2)2))
and we can write it with linear algebra form:
p
(
w
,
h
)
=
1
2
π
α
1
2
π
α
2
exp
(
−
1
2
(
[
w
h
]
−
[
u
1
u
2
]
)
T
(
[
σ
1
0
0
σ
2
]
[
w
h
]
−
[
u
1
u
2
]
)
)
p(w,h)=\frac{1}{\sqrt{2\pi\alpha_1}\sqrt{2\pi\alpha_2}} \exp(-\frac{1}{2}(\begin{bmatrix} w\\ h \end{bmatrix}-\begin{bmatrix} u_1\\ u_2 \end{bmatrix})^T(\begin{bmatrix} \sigma_1 & 0\\ 0 & \sigma_2 \end{bmatrix}\begin{bmatrix} w\\ h \end{bmatrix}-\begin{bmatrix} u_1\\ u_2 \end{bmatrix}))
p(w,h)=2πα12πα21exp(−21([wh]−[u1u2])T([σ100σ2][wh]−[u1u2]))
and then, rename it:
p
(
y
)
=
1
∣
2
π
∗
D
∣
1
2
exp
(
−
1
2
(
y
−
μ
)
T
D
−
1
(
Y
−
μ
)
)
p(y)=\frac{1}{|2 \pi*D|^\frac{1}{2}} \exp(-\frac{1}{2}(y-\mu)^TD^{-1}(Y-\mu))
p(y)=∣2π∗D∣211exp(−21(y−μ)TD−1(Y−μ))
∣
D
∣
|D|
∣D∣ means the determinant of the matrix.
Correlated Gaussian
Form correlated from original by rotating the data space using matrx R.
p
(
y
)
=
1
∣
2
π
∗
D
∣
1
2
exp
(
−
1
2
(
R
T
y
−
R
T
μ
)
T
D
−
1
(
R
T
Y
−
R
T
μ
)
)
p(y)=\frac{1}{|2 \pi*D|^\frac{1}{2}} \exp(-\frac{1}{2}(R^Ty-R^T\mu)^TD^{-1}(R^TY-R^T\mu))
p(y)=∣2π∗D∣211exp(−21(RTy−RTμ)TD−1(RTY−RTμ))
p
(
y
)
=
1
∣
2
π
∗
D
∣
1
2
exp
(
−
1
2
(
y
−
μ
)
T
R
D
−
1
R
T
(
Y
−
μ
)
)
p(y)=\frac{1}{|2 \pi*D|^\frac{1}{2}} \exp(-\frac{1}{2}(y-\mu)^TRD^{-1}R^T(Y-\mu))
p(y)=∣2π∗D∣211exp(−21(y−μ)TRD−1RT(Y−μ))
this gives a covariance matric:
C
−
1
=
R
D
−
1
R
T
C^{-1}=RD^{-1}R^T
C−1=RD−1RT
which in some view is the result of the principal compoment.
Multivariate Consequence
if
x
∼
N
(
μ
,
Σ
)
x \sim \mathcal{N}(\mu,\varSigma)
x∼N(μ,Σ)
and
y
=
W
x
y=Wx
y=Wx
then
y
∼
N
(
W
μ
,
W
Σ
W
T
)
y\sim \mathcal{N}(W\mu,W\varSigma W^T)
y∼N(Wμ,WΣWT)
we can say the first equaption is the prior of x x x, the second is the likelihood, the last is the marginal of y y y. If we set μ = 0 , Σ = I \mu = 0, \varSigma = I μ=0,Σ=I, so it is just the inverse of PCA.
Prediction with Correlated Gaussians
-
Prediction of f ∗ \mathbf{f}_* f∗ from f \mathbf{f} f requires multivariate conditional density.
-
Multivariate conditional density is also Gaussian.
p ( f ∗ ∣ f ) = N ( f ∗ ∣ K ∗ , f K f , f − 1 f , K ∗ , ∗ − K ∗ , f K f , f − 1 K f , ∗ ) p(\mathbf{f}_*|\mathbf{f}) = \mathcal{N}\left(\mathbf{f}_*|\mathbf{K}_{*,\mathbf{f}}\mathbf{K}_{\mathbf{f},\mathbf{f}}^{-1}\mathbf{f},\mathbf{K}_{*,*}-\mathbf{K}_{*,\mathbf{f}} \mathbf{K}_{\mathbf{f},\mathbf{f}}^{-1}\mathbf{K}_{\mathbf{f},*}\right) p(f∗∣f)=N(f∗∣K∗,fKf,f−1f,K∗,∗−K∗,fKf,f−1Kf,∗) -
Here covariance of joint density is given by
K = [ K f , f K ∗ , f K f , ∗ K ∗ , ∗ ] \mathbf{K} = \begin{bmatrix} \mathbf{K}_{\mathbf{f}, \mathbf{f}} & \mathbf{K}_{*, \mathbf{f}}\\ \mathbf{K}_{\mathbf{f}, *} & \mathbf{K}_{*, *}\end{bmatrix} K=[Kf,fKf,∗K∗,fK∗,∗]
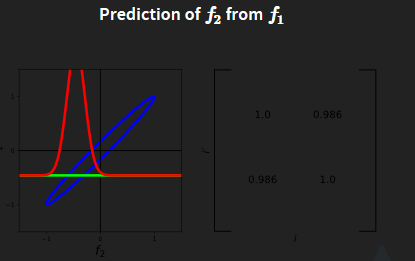
Take the picture as the example:
since that example is in 1D, all the values are scalar.
f
=
f
1
=
−
0.4
f=f1=-0.4
f=f1=−0.4,
K
f
,
f
=
1
,
K
∗
,
f
=
0.98
,
K
∗
,
∗
=
1
K_{f,f}=1,K_{*,f}=0.98,K_{*,*}=1
Kf,f=1,K∗,f=0.98,K∗,∗=1, so
p
(
p
2
∣
p
1
)
=
N
(
p
2
∣
0.98
∗
1
∗
(
−
0.4
)
,
1
−
0.98
∗
1
∗
0.98
)
p(p_2|p_1)=\mathcal{N}(p_2|0.98*1*(-0.4),1-0.98 *1*0.98)
p(p2∣p1)=N(p2∣0.98∗1∗(−0.4),1−0.98∗1∗0.98)
p
(
p
2
∣
p
1
)
=
N
(
p
2
∣
−
0.392
,
0.0396
)
p(p_2|p_1)= \mathcal{N}(p_2|-0.392,0.0396)
p(p2∣p1)=N(p2∣−0.392,0.0396)
the variance is 0.0396, and the standard variance is 0.2.














 2976
2976











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









