






摘要
最近提出的BERT在各种自然语言理解任务上表现出强大的能力,例如文本分类,阅读理解等。然而,如何有效地将BERT应用于神经机器翻译(NMT)仍然缺乏足够的探索。虽然BERT通常用于微调,而不是用于下游语言理解任务的上下文嵌入,但是在NMT中,我们实验表明使用BERT作为上下文嵌入的初步探索要比用于微调更好。这激发了我们思考如何沿着这个方向更好地利用BERT进行NMT。我们提出了一种称为BERT-fused模型的新算法,该算法首先使用BERT提取输入序列的表示,然后通过注意力机制将表示与NMT模型的编码器和解码器的每一层融合。我们在有监督的(包括句子级和文档级的翻译),半监督的和无监督的机器翻译上进行实验,并在七个基准数据集上获得了最新的结果。我们的代码可从https://github.com/bert-nmt/bert-nmt获得。
1.介绍
最近,像ELMo,GPT/GPT-2,BERT,跨语言模型(简而言之,XLM),XLNet和RoBERTa在机器学习和自然语言处理领域引起了越来越多的关注。这些模型首先在大量未标记的数据上进行预训练以捕获输入的丰富表示,然后通过提供输入序列的上下文嵌入或初始化模型的参数并进行微调,从而将其应用于下游任务。这样的预训练方法导致自然语言理解任务的显着改善。其中,BERT是最强大的技术之一,它启发了XLNet,XLM,RoBERTa等许多变体,并为许多语言理解任务(包括阅读理解,文本分类等)取得了最新的成果。
神经机器翻译(NMT)旨在将输入序列从源语言转换为目标语言。NMT模型通常由将输入序列映射到隐藏表示的编码器和对隐藏表示进行解码以生成目标语言句子的解码器组成。鉴于BERT在语言理解任务上取得了巨大成功,因此值得研究的问题是如何结合BERT来改善NMT。由于计算资源的限制,从头开始训练BERT模型对于许多研究人员来说是负担不起的。因此,我们专注于为NMT利用预训练的BERT模型(而不是从头开始训练BERT模型)的设置。
鉴于使用BERT进行NMT的工作量有限,我们的首先尝试两种先前的策略:(1)使用BERT初始化下游模型,然后对模型进行微调,以及(2)使用BERT作为上下文嵌入的下游模型。对于第一个策略,遵循Devlin et al. (2019),我们使用预训练的BERT模型初始化NMT模型的编码器,然后在下游数据集上微调NMT模型。不幸的是,我们没有观察到明显的改善。使用预训练的XLM模型(用于机器翻译的BERT变体)来热启动NMT模型是另一种选择。XLM已被证明有助于WMT’16 Romanian-to-English的翻译。但是,当将其应用于超出语料库的语言领域以训练XLM(例如有关口语的IWSLT数据集)时,或者当大型双语数据可用于下游任务时,都没有观察到明显的改进。对于第二种策略,遵循(Peters et al., 2018)的实践,我们使用BERT为NMT模型提供上下文嵌入。我们发现此策略优于第一个策略(更多信息请参考第3节)。这激励我们朝着这个方向前进,并设计出更有效的算法。
我们提出了一种新的算法,即BERT-fused模型,在该算法中,我们通过将BERT的表示馈入所有层而不是仅用作输入嵌入来利用它。我们使用注意力机制来自适应地控制每一层如何与表示交互,并处理BERT模块和NMT模块可能使用不同的分词规则,从而导致不同的序列(即表示)长度的情况。与标准NMT相比,除BERT外,还有两个额外的注意力模块,即BERT编码器注意力和BERT解码器注意力。首先将输入序列转换为由BERT处理的表示形式。然后,通过BERT-encoder注意力模块,每个NMT编码器层与从BERT获得的表示进行交互,并最终利用BERT和NMT编码器输出融合表示。解码器的工作原理类似,并且融合了BERT表示和NMT编码器表示。
我们针对各种NMT任务进行了14个实验,以验证我们的方法,包括监督,半监督和无监督的设置。对于有监督的NMT,我们处理IWSLT数据集的五个任务和WMT数据集的两个任务。具体来说,我们在IIWSLT’14 Germanto-English 翻译中获得了36.11的BLEU分数,为这项任务创造了新的记录。我们还致力于IWSLT的两个文档级翻译,并将德语到英语翻译的BLEU分数进一步提高到36.69。在WMT’14的数据集上,我们在英语到德语的翻译中获得了30.75 BLEU的评分,在英语到法语的翻译中获得了43.78的评分,明显优于基线。对于半监督NMT,我们将经典的半监督算法反向翻译从WMT’16 Romanian-to-English翻译的BLEU分数从37.73提高到39.10,在此上获得了最佳结果任务。最后,我们在无监督的英语↔法语和无监督的英语↔罗马尼亚语翻译中验证了我们的算法,并获得了最新的结果。
2.背景和相关工作
本节我们将简要介绍了NMT的背景并回顾了当前的预训练技术。
(1)NMT
NMT目的是将输入句子从源语言翻译成目标语言。NMT模型通常由编码器,解码器和注意力模块组成。编码器将输入序列映射到隐藏表示,而解码器将隐藏表示映射到目标序列。Bahdanau et al. (2015) 首先引入了注意力模块,用于更好地对齐源词和目标词。编码器和解码器可以使用LSTM,CNN和Transformer。Transformer层由三个子层组成:一个自我注意力层,用于处理每个时刻的上下文的序列数据;一个可选的编码器-解码器注意力层,用于桥接仅存在于解码器中的输入序列和目标序列,以及一个前向层用于非线性转换。Transformer达到了NMT的最新成果。在这项工作中,我们将使用Transformer作为模型的基本架构。
(2)预训练
预训练在机器学习和自然语言处理方面有着悠久的历史。Mikolov et al. (2013) 和Pennington et al. (2014) 提出对单个单词使用分布式表示(即单词嵌入)。Dai & Le (2015) 提出使用未标记的数据训练语言模型或自动编码器,然后利用获得的模型来微调下游任务。近年来,预训练越来越受到人们的关注,并且随着数据规模的扩大和采用深度神经网络的实现,预训练取得了很大的进步。ELMo是Peters et al. (2018) 提出的基于双向LSTM,其预训练的模型被作为上下文嵌入输入到下游任务中。在GPT中,基于Transformer的语言模型在未标记的数据集上进行了预训练,然后在下游任务上进行了微调。BERT是广泛用于模型初始化的预训练方法之一。BERT的架构是Transformer的编码器。BERT训练中使用两种目标函数:(1)屏蔽语言建模(MLM),其中将句子中15%的单词屏蔽,并对BERT进行训练以预测其周围单词。(2)下一个句子预测(NSP):预训练BERT的另一个任务是预测两个输入序列是否相邻。为此,训练语料由元组和可学习的特殊标记
[
c
l
s
]
[cls]
[cls]组成(
[
c
l
s
]
,
i
n
p
o
u
t
1
,
[
s
e
p
]
,
i
n
p
u
t
2
,
[
s
e
p
]
[cls],inpout~1,[sep],input~2,[sep]
[cls],inpout 1,[sep],input 2,[sep]),该标记对
i
n
p
o
u
t
1
inpout~1
inpout 1和
i
n
p
u
t
2
input~2
input 2是否相邻进行分类吗,另外
[
s
e
p
]
[sep]
[sep]用以分割两个句子,并以50%的概率将第二个输入替换为随机输入。已经提出了BERT的变体:在XLM中,该模型基于多种语言进行了预训练,并且删除了NSP任务;在RoBERTa中,在没有NSP任务的情况下也利用了更多未标记的数据跑;在XLNet中,引入了基于全排列的建模。
3.初步探索

尽管有几项工作设计了针对NMT的特定预训练方法,但由于它们需要使用大规模数据从头开始对大型模型进行预训练,因此它们既浪费时间又浪费资源,甚至每种语言对都有一个模型。在这项工作中,我们专注于使用预训练的BERT模型的设置。详细的模型下载链接可在附录D中找到。
考虑到已经以两种不同的方式将预训练模型用于其他自然语言任务,因此很容易尝试将其用于NMT。根据以前的实践,我们进行以下尝试。
(I)使用预训练模型初始化NMT模型,此方法有不同的实现。(1)与Devlin et al., 2019 相同,我们使用预训练的BERT初始化NMT模型的编码器。(2)与Lample & Conneau, 2019 相同,我们使用XLM初始化NMT模型的编码器和/或解码器。
(II)使用预训练的模型作为NMT模型的输入。 受Peters et al., 2018 的启发,我们将BERT的最后一层的输出作为NMT模型的输入。
我们对 IWSLT’14 English→German翻译进行了实验,这是一种广泛采用的机器翻译数据集,包含16万个带标签的句子对。我们选择Transformer作为
t
r
a
n
s
f
o
r
m
e
r
_
i
w
s
l
t
_
d
e
_
e
n
transformer\_iwslt\_de\_en
transformer_iwslt_de_en配置(具有36.7M参数的六层模型)的基本模型架构。翻译质量由BLEU评分评估。
B
E
R
T
b
a
s
e
BERT_{base}
BERTbase和XLM模型都是经过预训练的,我们可以从Web上获得它们。有关实验设置的更多详细信息,请参见附录A.2。
结果如表1所示。我们有以下几点观察:(1)使用BERT初始化NMT编码器只能达到27.14 BLEU评分,甚至比不使用BERT的标准Transformer还差。也就是说,仅使用BERT来热启动NMT模型不是一个好选择。(2)使用XLM分别初始化编码器或解码器,我们得到28.22或26.13的BLEU得分,不超过基线。如果两个模块都使用XLM初始化,则BLEU得分将提高到28.99,略好于基线。尽管XLM在WMT’16 Romanian-to-English方面取得了巨大的成功,但我们在这里取得的进步有限。我们的推测是,XLM模型已在新闻数据上进行了预训练,而IWSLT数据集的领域主要是关于口语,因此,改进效果有限。(3)当使用BERT的输出作为编码器的上下文嵌入时,我们实现了29.67 BLEU,这比使用预训练的模型进行初始化要好得多。这表明利用BERT作为特征提供者在NMT中更有效。这激励我们采取进一步的措施,并研究如何充分利用预训练的BERT模型提供的这些特征。
4.算法
在本节中,我们首先定义必要的符号,然后介绍我们提出的BERT-fused模型,最后提供有关现有工作的讨论。
(1)符号定义
令
X
\mathcal X
X和
Y
\mathcal Y
Y分别表示源语言和目标语言,它们是具有相同语种的句子的集合。对于任何句子
x
∈
X
x∈\mathcal X
x∈X和
y
∈
Y
y∈\mathcal Y
y∈Y,令
l
x
l_x
lx和
l
y
l_y
ly表示
x
x
x和
y
y
y中的单元数(例如单词或子词)。
x
/
y
x/y
x/y中的第
i
i
i个单元表示为
x
i
/
y
i
x_i/y_i
xi/yi。将编码器,解码器和BERT分别表示为
E
n
c
Enc
Enc,
D
e
c
Dec
Dec和
B
E
R
T
BERT
BERT。为便于参考,我们在本工作中将编码器和解码器称为NMT模块。为了更好的描述,我们假设编码器和解码器均由
L
L
L层组成。令
a
t
t
n
(
q
,
K
,
V
)
attn(q,K,V)
attn(q,K,V)表示注意力层,其中q,K和V分别表示query,key和value。我们使用与(Vaswani et al., 2017) 中使用的相同的前馈层,并将其表示为FFN。上述各层的数学公式可在附录E中查看。
4.1 BERT-fused模型
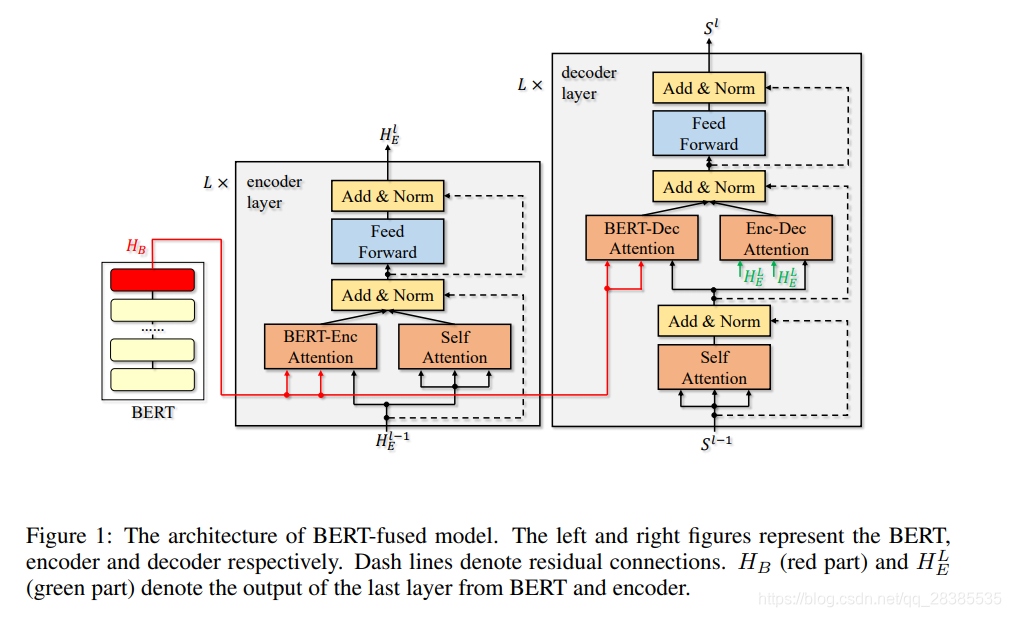
图1显示了我们的算法。任何输入
x
∈
X
x∈\mathcal X
x∈X都由BERT,编码器和解码器逐步处理。
(1)Step-1
给定任何输入
x
∈
X
x∈\mathcal X
x∈X,BERT首先将其编码为表示
H
B
=
B
E
R
T
(
x
)
H_B=BERT(x)
HB=BERT(x)。
H
B
H_B
HB是BERT中最后一层的输出。
h
B
,
i
∈
H
B
h_{B,i}∈H_B
hB,i∈HB是
x
x
x中第
i
i
i个单词的表示。
(1)Step-2
令
H
E
l
H^l_E
HEl表示编码器中的第
l
l
l层的隐藏表示,并且令
H
E
0
H^0_E
HE0表示序列
x
x
x的词嵌入。对于任何
i
∈
[
l
x
]
i∈[l_x]
i∈[lx],将
H
E
l
H^l_E
HEl中的第
i
i
i个元素表示为
h
i
l
h^l_i
hil。对于
l
∈
[
L
]
l∈[L]
l∈[L]层,有:
h
~
i
l
=
1
2
(
a
t
t
n
S
(
h
i
l
−
1
,
H
E
l
−
1
,
H
E
l
−
1
)
+
a
t
t
n
B
(
h
i
l
−
1
,
H
B
,
H
B
)
)
,
∀
i
∈
[
l
x
]
(1)
\tilde h^l_i=\frac{1}{2}(attn_S(h^{l-1}_i,H^{l-1}_E,H^{l-1}_E)+attn_B(h^{l-1}_i,H_B,H_B)),\forall i\in [l_x] \tag{1}
h~il=21(attnS(hil−1,HEl−1,HEl−1)+attnB(hil−1,HB,HB)),∀i∈[lx](1)
其中
a
t
t
n
S
attn_S
attnS和
a
t
t
n
B
attn_B
attnB是具有不同参数的注意力模型(请参见等式6)。然后,每个
h
~
i
l
\tilde h^l_i
h~il由方程(7)中定义的
F
F
N
(
⋅
)
FFN(·)
FFN(⋅)进一步处理,从而得到第
l
l
l层的输出:
H
E
l
=
(
F
F
N
(
h
~
1
l
)
,
⋅
⋅
⋅
,
F
F
N
(
h
~
l
x
l
)
)
H^l_E=(FFN(\tilde h^l_1),···,FFN(\tilde h^l_{l_x}))
HEl=(FFN(h~1l),⋅⋅⋅,FFN(h~lxl))。编码器最终将从最后一层输出
H
E
L
H^L_E
HEL。
(1)Step-3
令
S
<
t
l
S^l_{<t}
S<tl表示在时刻
t
t
t之前解码器中第
l
l
l层的隐藏状态,即,
S
<
t
l
=
(
s
1
l
,
.
.
.
,
s
t
−
1
l
)
S^l_{<t}=(s^l_1,...,s^l_{t-1})
S<tl=(s1l,...,st−1l)。注意
s
1
0
s^0_1
s10是用来表示序列开始的特殊标记,而
s
t
0
s^0_t
st0是在时刻
t
−
1
t-1
t−1预测单词的嵌入。在第
l
l
l层,可得:
s
^
t
l
=
a
t
t
n
S
(
s
t
l
−
1
,
S
<
t
+
1
l
−
1
,
S
<
t
+
1
l
−
1
)
;
s
~
t
l
=
1
2
(
a
t
t
n
B
(
s
^
t
l
,
H
B
,
H
B
)
+
a
t
t
n
E
(
s
^
t
l
,
H
E
L
,
H
E
L
)
)
,
s
t
l
=
F
F
N
(
s
~
t
l
)
(2)
\hat s^l_t=attn_S(s^{l-1}_t,S^{l-1}_{\lt t+1},S^{l-1}_{\lt t+1});\\ \tilde s^l_t=\frac{1}{2}(attn_B(\hat s^l_t,H_B,H_B)+attn_E(\hat s^l_t,H^L_E,H^L_E)),s^l_t=FFN(\tilde s^l_t) \tag{2}
s^tl=attnS(stl−1,S<t+1l−1,S<t+1l−1);s~tl=21(attnB(s^tl,HB,HB)+attnE(s^tl,HEL,HEL)),stl=FFN(s~tl)(2)
a
t
t
n
S
attn_S
attnS,
a
t
t
n
B
attn_B
attnB和
a
t
t
n
E
attn_E
attnE分别代表自注意力模型,BERT-decoder注意力模型和encoder-decoder注意力模型。等式2在解码器各层上迭代,最终可以得到
s
t
L
s^L_t
stL。最后,通过线性变换和softmax映射
s
t
L
s^L_t
stL以获得第
t
+
1
t+1
t+1个预测词
y
^
t
+
1
\hat y_{t+1}
y^t+1。解码过程一直持续到出现句子结束标记为止。
在我们的框架中,BERT的输出用作外部序列表示,并且我们使用注意力模型将其合并到NMT模型中。这是一种利用预训练模型的通用方法,而与e tokenizati方法无关。
4.2 2 DROP-NET技巧
受dropout和drop-path的启发(这些方法可以正则化网络训练),我们提出了Drop-net技巧,以确保BERT和常规编码器输出的特征被充分利用。引入drop-net将影响等式1和等式2。将drop-net概率表示为
p
n
e
t
∈
[
0
,
1
]
p_{net}∈[0,1]
pnet∈[0,1]。在每次训练迭代中,对于任意层
l
l
l,我们从
[
0
,
1
]
[0,1]
[0,1]中均匀采样一个随机变量
U
l
U^l
Ul,然后以下列方式计算等式1中的所有
h
~
i
l
\tilde h^l_i
h~il:
h
~
i
,
d
r
o
p
−
n
e
t
l
=
I
(
U
l
<
p
n
e
t
2
)
⋅
a
t
t
n
S
(
h
i
l
−
1
,
H
E
l
−
1
,
H
E
l
−
1
)
+
I
(
U
l
>
1
−
p
n
e
t
2
)
⋅
a
t
t
n
B
(
h
i
l
−
1
,
H
B
,
H
B
)
+
1
2
I
(
p
n
e
t
2
≤
U
l
≤
1
−
p
n
e
t
2
)
⋅
(
a
t
t
n
S
(
h
i
l
−
1
,
H
E
l
−
1
,
H
E
l
−
1
)
+
a
t
t
n
B
(
h
i
l
−
1
,
H
B
,
H
B
)
)
,
(3)
\tilde h^l_{i,drop-net}=\mathbb I(U^l\lt \frac{p_{net}}{2})\cdot attn_S(h^{l-1}_i,H^{l-1}_E,H^{l-1}_E)+\mathbb I(U^l\gt 1-\frac{p_{net}}{2})\cdot attn_B(h^{l-1}_i,H_B,H_B)\\ +\frac{1}{2}\mathbb I(\frac{p_{net}}{2}\le U^l\le 1-\frac{p_{net}}{2})\cdot (attn_S(h^{l-1}_i,H^{l-1}_E,H^{l-1}_E)+attn_B(h^{l-1}_i,H_B,H_B)),\tag{3}
h~i,drop−netl=I(Ul<2pnet)⋅attnS(hil−1,HEl−1,HEl−1)+I(Ul>1−2pnet)⋅attnB(hil−1,HB,HB)+21I(2pnet≤Ul≤1−2pnet)⋅(attnS(hil−1,HEl−1,HEl−1)+attnB(hil−1,HB,HB)),(3)
其中
I
(
⋅
)
\mathbb I(·)
I(⋅)是指示函数。对于概率为
p
n
e
t
/
2
p_{net}/2
pnet/2的任何层,仅使用BERT编码器注意力或自注意力。概率为
(
1
−
p
n
e
t
)
(1-p_{net})
(1−pnet),则两个注意力模型都被使用。例如,在特定的迭代中,第一层可能仅使用
a
t
t
n
S
attn_S
attnS,而第二层可能仅使用
a
t
t
n
B
attn_B
attnB。在推理期间,使用每个注意力模型的期望输出,即
E
U
〜
u
n
i
f
o
r
m
[
0
,
1
]
(
h
~
i
,
d
r
o
p
−
n
e
t
l
)
\mathbb E_{U〜uniform[0,1]}(\tilde h^l_{i,drop-net})
EU〜uniform[0,1](h~i,drop−netl)。期望恰好等于等式1。
类似地,在训练解码器时,使用drop-net技巧,我们有:
s
~
t
,
d
r
o
p
−
n
e
t
l
=
I
(
U
l
<
p
n
e
t
2
)
⋅
a
t
t
n
B
(
s
^
t
l
,
H
B
,
H
B
)
+
I
(
U
l
>
1
−
p
n
e
t
2
)
⋅
a
t
t
n
E
(
s
^
t
l
,
H
E
L
,
H
E
L
)
+
1
2
I
(
p
n
e
t
2
≤
U
l
≤
1
−
p
n
e
t
2
)
⋅
(
a
t
t
n
B
(
s
^
t
l
,
H
B
,
H
B
)
+
a
t
t
n
E
(
s
^
t
l
,
H
E
L
,
H
E
L
)
)
,
(3)
\tilde s^l_{t,drop-net}=\mathbb I(U^l\lt \frac{p_{net}}{2})\cdot attn_B(\hat s^l_t,H_B,H_B)+\mathbb I(U^l\gt 1-\frac{p_{net}}{2})\cdot attn_E(\hat s^l_t,H^L_E,H^L_E)\\ +\frac{1}{2}\mathbb I(\frac{p_{net}}{2}\le U^l\le 1-\frac{p_{net}}{2})\cdot (attn_B(\hat s^l_t,H_B,H_B)+attn_E(\hat s^l_t,H^L_E,H^L_E)),\tag{3}
s~t,drop−netl=I(Ul<2pnet)⋅attnB(s^tl,HB,HB)+I(Ul>1−2pnet)⋅attnE(s^tl,HEL,HEL)+21I(2pnet≤Ul≤1−2pnet)⋅(attnB(s^tl,HB,HB)+attnE(s^tl,HEL,HEL)),(3)
为了进行推断,它的计算方法与公式2相同。使用此技术可以防止网络过拟合(有关更多详细信息,请参见第6节的第二部分)。
4.3 讨论
与ELMo的比较如第2节所述,ELMo为编码器提供了上下文嵌入,以便捕获输入序列的更丰富的信息。与之相比,我们的方法是一种利用预训练模型中的特征的更有效方法:(1)将预训练模型的输出特征融合到NMT模块的所有层中,以确保经过充分训练的特征得以充分利用;(2)我们使用注意力模型来桥接NMT模块和BERT的预训练特征,其中NMT模块可以自适应地确定如何利用BERT的特征。
我们知道我们的方法有几个局限性:(1)额外的存储成本:我们的方法利用了BERT模型,这导致了额外的存储成本。但是,考虑到BLEU的改进以及我们不需要对BERT进行额外训练这一情况,我们认为额外的存储是可以接受的。(2)额外的推理时间:我们使用BERT对输入序列进行编码,这需要大约45%的额外时间(有关详细信息,请参见附录C)。 我们将上述两个限制的改进留作以后的工作。

















 547
547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









