






摘要
本文根据我们构建的神经抽取式摘要系统的方式创建了一个范式转换。我们没有遵循通常使用的首先抽取句子,然后再建模句子之间关系的框架,而是将抽取式摘要任务形式化为语义文本匹配问题,在该问题中,源文档和候选摘要(从原始文本中提取)将在语义空间进行匹配。值得注意的是,这种向语义匹配框架的转变是基于我们根据数据集的属性对句子级提取器与摘要级提取器之间的固有差距进行全面分析的基础。此外,即使使用简单形式的匹配模型实例化框架,我们也已将CNN / DailyMail上的最新抽取结果提升到了一个新水平(ROUGE-1中为44.41)。在其他五个数据集上的实验也显示了匹配框架的有效性。我们认为,这种基于匹配的摘要框架的功能尚未得到充分利用。为了鼓励将来更多的实例化,我们在https://github.com/maszhongming/MatchSum中发布了代码,经过处理的数据集以及生成的摘要。
1.介绍
自动文本摘要的任务旨在将文本文档压缩为较短的重要语句显示,同时保留有关原始文本的重要信息。在本文中,我们专注于抽取式摘要,因为它通常会生成语义和语法上正确的句子并且计算速度更快。
目前,大多数神经抽取摘要系统从原始文本中逐一评分和提取句子(或更小的语义单元),对句子之间的关系进行建模,然后选择几个句子以形成一个句子摘要。Cheng and Lapata (2016); Nallapati et al. (2017) 将抽取式摘要任务表述为序列标记问题,并使用编码器-解码器框架解决该问题。这些模型为每个句子做出独立的二分类决策,从而实现高冗余度。解决上述问题的自然方法是引入自回归解码器,从而允许不同句子的评分操作相互影响。 Trigram Blocking作为最近更流行的方法具有相同的动机。在选择句子以形成摘要的阶段,它将跳过具有与先前选择的句子重叠的字母的句子。出乎意料的是,这种简单的删除重复的方法为CNN/DailyMail带来了显着的性能改进。
以上对句子之间的关系进行建模的系统本质上是句子级提取器,而不是考虑整个摘要的语义。这使他们更倾向于选择高度通用的句子,而忽略了多个句子的耦合。Narayan et al. (2018b); Bae et al. (2019) 利用强化学习(RL)来实现摘要级评分,但仍限于句子级抽取器的体系结构。
为了更好地理解句子级和摘要级方法的优点和局限性,我们对六个基准数据集(在第3节中)进行了分析,以探索这两种方法的特性。我们发现,在这些数据集中,这两种方法之间确实存在固有的差距,这促使我们提出以下摘要级的方法。
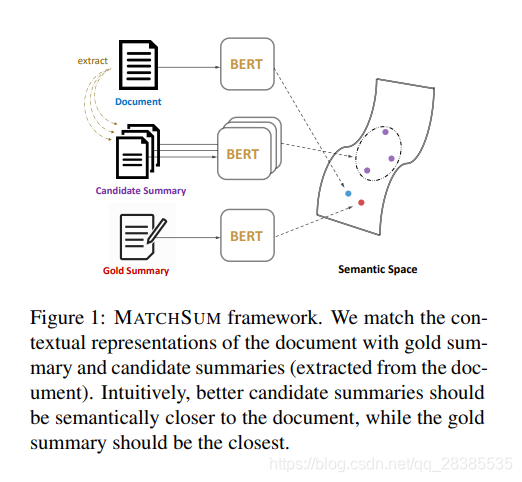
在本文中,我们提出了一个新的摘要级框架(MATCHSUM,图1),并将抽取式摘要概念化为语义文本匹配问题。原则上的想法是,一个好的摘要在整体上应比无限制的摘要在语义上更类似于源文档。语义文本匹配是估计源文本片段和目标文本片段之间语义相似性的重要研究问题,已广泛应用于信息检索,问答,自然语言推理等领域。语义文本匹配的最常规方法之一是学习每个文本片段的矢量表示,然后应用典型的相似性度量来计算匹配分数。
对于抽取式摘要,我们提出了一个Siamese-BERT架构来计算源文档和候选摘要之间的相似度。Siamese BERT在Siamese网络结构中利用了经过预训练的BERT,以导出可以使用余弦相似度进行比较的语义有意义的文本嵌入。一个好的摘要在一组候选摘要中具有最高的相似性。
我们评估提出的匹配框架,并对一系列基准数据集进行显着性测试。在所有情况下,我们的模型均明显优于强基准,并改善了CNN / DailyMail的最新的抽取结果。此外,我们设计实验以观察框架带来的收益。
我们将我们的贡献总结如下:
1)我们将提取摘要描述为语义文本匹配问题,而不是一个一个地对句子进行评分和提取以形成摘要,并提出了一个新的摘要级框架。我们的方法通过对比学习绕过了摘要级优化的难度,也就是说,一个好的摘要在语义上应比无限制的摘要更类似于源文档。
2)我们进行分析以研究抽取模型是否必须根据数据集的属性进行摘要级提取,并尝试量化句子级方法与摘要级方法之间的固有差距。
3)与六个基准数据集上的强基准相比,我们提出的框架已实现了最好的性能。值得注意的是,仅使用基本版本的BERT,我们就可以在CNN/DailyMail上获得最新的抽取结果(ROUGE-1中为44.41)。此外,我们试图观察模型的性能增益来自何处。
2.相关工作
2.1 抽取式摘要
关于抽取式摘要的最新研究工作涉及多种方法。这些工作通常通过选择RNN,Transformer或GNN来构建编码器-解码器框架, 非自回归解码器或自回归解码器。尽管有效,但是这些模型本质上是句子级别的抽取器,具有单个评分过程,尽管这会获得最高评分的句子,但可能不是形成摘要的最佳模型。
RL的应用提供了摘要级评分的手段并带来了改进。但是,这些努力仍然仅限于自回归或非自回归体系结构。此外,在非神经网络方法中,整数线性规划(ILP)方法也可用于摘要级评分。
此外,在本文之前,还有一些工作可以从语义的角度解决抽取式摘要,例如概念覆盖,重构以及最大化语义量。
2.2 两阶段摘要
最近的研究试图建立两阶段的文档摘要系统。对于抽取式摘要,第一阶段通常是提取原始文本的某些片段,第二阶段通常是在这些片段的基础上进行选择或修改。
Chen and Bansal (2018) 和Bae et al. (2019) 遵循混合“提取然后重写”框架,基于策略的RL将两个网络桥接在一起。Lebanoff et al. (2019); Xu and Durrett (2019); Mendes et al. (2019) 专注于提取-压缩学习框架,即压缩式摘要,它首先训练抽取器进行内容选择。我们的模型可以看作是“提取然后匹配”框架,该框架还使用句子提取器来修剪不必要的信息。
3.Sentence-Level or Summary-Level? A Dataset-dependent Analysis
尽管先前的工作已经指出了句子级提取器的弱点,但是对于以下问题尚无系统的分析:1)对于抽取式摘要,摘要级提取器是否比句子级提取器更好? 2)给定一个数据集,我们应该根据数据的特征选择哪个提取器,这两个提取器之间的固有差距是什么?
在本节中,我们将研究六个基准数据集上句子级和摘要级方法之间的差距,这些差距可以指导我们寻找有效的学习框架。值得注意的是,我们在这里使用的句子级抽取器不包含冗余删除过程,因此我们可以估算摘要级抽取器对冗余消除的影响。值得注意的是,本节中介绍的用于评估理论有效性的分析方法是通用的,可以应用于任何摘要级的方法。
3.1 定义
我们将
D
=
{
s
1
,
⋅
⋅
⋅
,
s
n
}
D=\{s_1,···,s_n\}
D={s1,⋅⋅⋅,sn}称为包含
n
n
n个句子的单文档,将
C
=
{
s
1
,
⋅
⋅
⋅
,
s
k
,
∣
s
i
∈
D
}
C=\{s_1,···,s_k,|s_i∈D\}
C={s1,⋅⋅⋅,sk,∣si∈D}作为候选摘要,该摘要中包括
k
(
k
≤
n
)
k(k≤n)
k(k≤n)个从文档中提取的句子。给定具有标准摘要
C
∗
C^∗
C∗的文档D,我们通过计算
C
C
C和
C
∗
C^∗
C∗之间的ROUGE值,在两个级别上测量候选摘要
C
C
C:
1)Sentence-Level Score:
g
s
e
n
(
C
)
=
1
∣
C
∣
∑
s
∈
C
R
(
s
,
C
∗
)
,
(1)
g^{sen}(C)=\frac{1}{|C|}\sum_{s\in C}R(s,C^*),\tag{1}
gsen(C)=∣C∣1s∈C∑R(s,C∗),(1)
其中,
s
s
s是
C
C
C中的句子,
∣
C
∣
|C|
∣C∣代表句子的数量。
R
(
⋅
)
R(·)
R(⋅)表示平均ROUGE得分。因此,
g
s
e
n
(
C
)
g^{sen}(C)
gsen(C)表示
C
C
C中的每个句子与标准摘要
C
∗
C^∗
C∗之间的平均重叠。
2)Summary-Level Score:
g
s
u
m
(
C
)
=
R
(
C
,
C
∗
)
,
(2)
g^{sum}(C)=R(C,C^*),\tag{2}
gsum(C)=R(C,C∗),(2)
其中
g
s
u
m
(
C
)
g^{sum}(C)
gsum(C)将
C
C
C中的句子视为一个整体,然后和标准摘要
C
∗
C^∗
C∗计算ROUGE得分。
Pearl-Summary。我们将pearl-summary定义为句子级别得分较低但摘要级别得分较高的摘要。
Definition 1。如果存在满足不等式(
g
s
e
n
(
C
′
)
>
g
s
e
n
(
C
)
w
h
i
l
e
g
s
u
m
(
C
′
)
<
g
s
u
m
(
C
)
g^{sen}(C')>g^{sen}(C)~while~g^{sum}(C')<g^{sum}(C)
gsen(C′)>gsen(C) while gsum(C′)<gsum(C))的另一个候选摘要
C
′
C'
C′,则候选摘要
C
C
C定义为pearl-summary。显然,如果候选摘要是pearl-summary,那么用句子级别的抽取器来提取摘要就具有挑战性。
Best-Summary。best-summary是指在所有候选摘要中摘要级评分最高的摘要。
Definition 2。满足以下条件时,摘要
C
^
\hat C
C^被定义为best-summary:
C
^
=
a
r
g
m
a
x
C
∈
C
g
s
u
m
(
C
)
\hat C=\mathop{argmax}\limits_{C∈\mathcal C}g^{sum}(C)
C^=C∈Cargmaxgsum(C),其中
C
\mathcal C
C表示文档的所有候选摘要。
3.2 Best-Summary排名

对于每个文档,我们根据句子级得分对所有候选摘要进行降序排序,然后将
z
z
z定义为best-summary
C
^
\hat C
C^的排名索引。
从直觉上讲,1)如果
z
=
1
z=1
z=1(
C
^
\hat C
C^排第一),则表示best-summary由得分最高的句子组成;2)如果
z
>
1
z>1
z>1,则best-summary是pearl-summary。并且随着
z
z
z的增加(
C
^
\hat C
C^排名降低),我们可以找到更多句子摘要得分高于best-summary的候选摘要,这导致句子级摘要提取器的学习会很困难(即越难找到best-summary)。
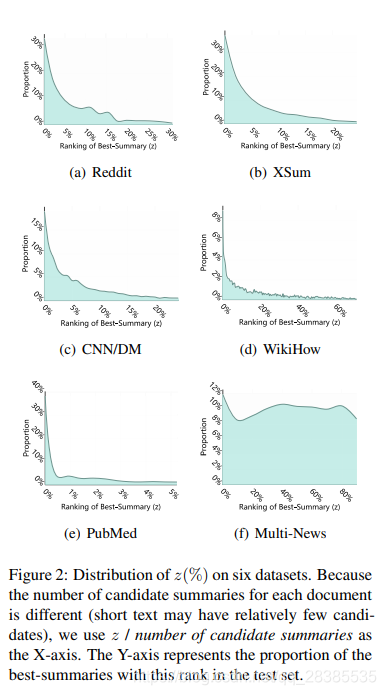
由于pearl-summary的出现将给句子级提取器带来挑战,因此,我们尝试研究6个基准数据集上不同数据集中pearl-summary的比例。表1中显示了这些数据集的详细描述。
如图2所示,我们可以观察到,对于所有数据集,大多数best-summary并非由得分最高的句子组成。具体来说,对于CNN/DM,只有18.9%的best-summary不是pearl-summary,这表明句子级提取器将很容易陷入局部优化,而缺少更好的候选摘要。
与CNN/DM不同,PubMed最适合句子级抽取器,因为大多数best-summary都不是pearl-summary。此外,在没有摘要级的学习过程的情况下,在WikiHow和Multi-News上获得良好的性能也是一个挑战,因为这两个数据集分布最均匀,也就是说,pearl-summary的出现使best-summary的选择更加复杂。
总之,pearl-summary在所有best-summary中的比例能表征数据集的属性,这将影响我们对摘要提取器的选择。
3.3 Inherent Gap between Sentence-Level and Summary-Level Extractors
上面的分析表明,摘要级抽取的方法比句子级抽取的方法更好,因为它可以挑选出pearl-summaries,但是给定特定的数据集可以带来多少改进?
根据评分方法的定义。通过等式(1)和(2),我们可以将文档
D
D
D的句子级和摘要级摘要系统的上限描述为:
α
s
e
n
(
D
)
=
m
a
x
C
∈
C
D
g
s
e
n
(
C
)
,
(3)
\alpha^{sen}(D)=\mathop{max}\limits_{C\in\mathcal C_D}~g^{sen}(C),\tag{3}
αsen(D)=C∈CDmax gsen(C),(3)
α
s
u
m
(
D
)
=
m
a
x
C
∈
C
D
g
s
u
m
(
C
)
,
(4)
\alpha^{sum}(D)=\mathop{max}\limits_{C\in\mathcal C_D}~g^{sum}(C),\tag{4}
αsum(D)=C∈CDmax gsum(C),(4)
其中
C
D
\mathcal C_D
CD是从
D
D
D中提取的候选摘要的集合。
然后,我们通过计算
α
s
e
n
(
D
)
α^{sen}(D)
αsen(D)和
α
s
u
m
(
D
)
α^{sum}(D)
αsum(D)之差来量化文档
D
D
D的潜在增益:
Δ
(
D
)
=
α
s
u
m
(
D
)
−
α
s
e
n
(
D
)
.
(5)
\Delta (D)=\alpha^{sum}(D)-\alpha^{sen}(D).\tag{5}
Δ(D)=αsum(D)−αsen(D).(5)
最后,可以通过以下方式获得数据集级别的潜在增益:
Δ
(
D
)
=
1
∣
D
∣
∑
D
∈
D
Δ
(
D
)
,
(6)
\Delta(\mathcal D)=\frac{1}{|\mathcal D|}\sum_{D\in \mathcal D}\Delta(D),\tag{6}
Δ(D)=∣D∣1D∈D∑Δ(D),(6)
其中
D
\mathcal D
D代表一个特定的数据集,
∣
D
∣
|\mathcal D|
∣D∣是此数据集中的文档数目。
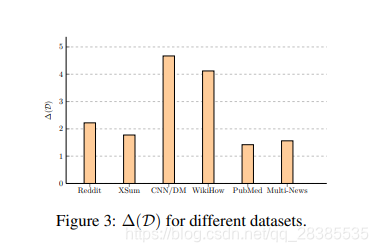
从图3中我们可以看到,摘要级方法的性能增益随数据集而变化,并且在CNN / DM上最大提高了4.7。从图3和表1中,我们可以发现性能增益与不同数据集的参考摘要的长度有关。在简短摘要(Reddit和XSum)的情况下,对pearl-summaries的完美识别不会带来太大的改进。同样,长摘要中的多个句子(PubMed和Multi-News)已经具有很大程度的语义重叠,使得摘要级方法的改进相对较小。但是对于中等长度的摘要(CNN / DM和WikiHow,约60个单词),摘要级的学习过程是有益的。我们将在5.4节中使用特定模型讨论这种性能提升。
4.Summarization as Matching
上述定量分析表明,对于大多数数据集而言,句子级提取器无法抽取pearl-summary,因此很难获得best-summary。为了更好地利用数据的上述特征,我们提出了一个摘要级别的框架,该框架可以直接对摘要进行评分和提取。
具体来说,我们将抽取式摘要任务表述为语义文本匹配问题,其中源文档和候选摘要将在语义空间中(从原始文本中提取)匹配。下一节将详细介绍如何通过使用基于siamese的简单体系结构实例化我们提出的匹配摘要框架。
4.1 Siamese-BERT
受siamese网络结构的启发,我们构建了一个Siamese-BERT架构以匹配文档
D
D
D和候选摘要
C
C
C。在推理阶段,我们的Siamese-BERT包含两个具有相同权重的BERT和一个余弦相似度层。
与(Liu, 2019; Bae et al., 2019) 中使用的修改后的BERT不同,我们直接使用原始BERT从文档
D
D
D和候选摘要
C
C
C中导出语义上有意义的嵌入,因为我们不需要获得句子级别的表示形式。因此,我们使用来自BERT顶层的
[
C
L
S
]
[CLS]
[CLS]字符的向量作为文档或摘要的表示。令
r
D
\textbf r_D
rD和
r
C
\textbf r_C
rC表示文档
D
D
D和候选摘要
C
C
C的嵌入。它们的相似性得分由
f
(
D
,
C
)
=
c
o
s
i
n
e
(
r
D
,
r
C
)
f(D,C)=cosine(\textbf r_D,\textbf r_C)
f(D,C)=cosine(rD,rC)度量。
为了微调Siamese-BERT,我们使用基于margin的三元损失来更新权重。从直觉上讲,标准摘要
C
∗
C^*
C∗在语义上应与原始文档最接近,这是我们损失的首要原则:
L
1
=
m
a
x
(
0
,
f
(
D
,
C
)
−
f
(
D
,
C
∗
)
+
γ
1
)
,
(7)
\mathcal L_1=max(0, f(D,C)-f(D,C^*)+\gamma_1),\tag{7}
L1=max(0,f(D,C)−f(D,C∗)+γ1),(7)
其中
C
C
C是
D
D
D中的候选摘要,而
γ
1
γ_1
γ1是边距值。此外,我们还为所有候选摘要设计了成对的margin损失。我们将所有候选摘要按照ROUGE分数的降序与标准摘要进行排序。自然,排名差距较大的候选对应该具有较大的margin,这是设计损失函数的第二个原则:
L
2
=
m
a
x
(
0
,
f
(
D
,
C
j
)
−
f
(
D
,
C
i
)
+
(
j
−
i
)
∗
γ
2
)
(
i
<
j
)
,
(8)
\mathcal L_2=max(0,f(D,C_j)-f(D,C_i)+(j-i)*\gamma_2)\quad (i\lt j),\tag{8}
L2=max(0,f(D,Cj)−f(D,Ci)+(j−i)∗γ2)(i<j),(8)
其中
C
i
C_i
Ci代表排名第
i
i
i的候选摘要,而
γ
2
γ_2
γ2是用于区分好的和不好的候选摘要的超参数。最后,我们基于margin的三元损失可以写成:
L
=
L
1
+
L
2
.
(2)
\mathcal L=\mathcal L_1+\mathcal L_2.\tag{2}
L=L1+L2.(2)
基本思想是让标准摘要具有最高的匹配分数,同时,与不合格的候选摘要相比,更好的候选摘要应获得更高的分数。图1说明了这个想法。
在推理阶段,我们将抽取式摘要形式化为一项任务,以在从文档
D
D
D提取的所有候选摘要
C
C
C中搜索最佳摘要。
C
^
=
a
r
g
m
a
x
C
∈
C
f
(
D
,
C
)
.
(10)
\hat C=\mathop{argmax}\limits_{C\in \mathcal C}~f(D,C).\tag{10}
C^=C∈Cargmax f(D,C).(10)
4.2 Candidates Pruning
Curse of Combination。当遇到组合爆炸问题时,匹配的想法更加直观。例如,我们如何确定候选摘要集的大小,或者应该对所有可能的候选者评分?为了减轻这些困难,我们提出了一种简单的候选修剪策略。
具体而言,我们引入了内容选择模块来预先选择重要的句子。该模块学习为每个句子分配重要性分数,并修剪与当前文档无关的句子,从而得到修剪的文档
D
′
=
{
s
1
′
,
⋅
⋅
⋅
,
s
e
x
t
′
∣
s
i
′
∈
D
}
D'=\{s'_1,···,s'_{ext}|s'_i∈D\}
D′={s1′,⋅⋅⋅,sext′∣si′∈D}。
与以前的两阶段摘要工作类似,我们的内容选择模块是一个参数化的神经网络。在本文中,我们使用没有三元模块的
B
E
R
T
S
U
M
BERTSUM
BERTSUM(我们称其为
B
E
R
T
E
X
T
BERTEXT
BERTEXT)为每个句子评分。然后,我们使用一条简单的规则来获取候选:生成经过修剪的文档的
s
e
l
sel
sel个句子的所有组合,并根据文档中的原始位置重新组织句子的顺序以形成候选摘要。因此,我们总共有
C
e
x
t
s
e
l
C^{sel}_{ext}
Cextsel个候选集。

















 299
299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









