






摘要
智能和自适应在线教育系统旨在为各种学生提供高质量的教育。然而,现有系统通常依赖于人工制作的问题池,这限制为不同水平的学生进行更加细粒度和开放性的自适应调整。我们将目标问题生成作为一个可控序列生成任务。我们首先展示如何使用深度知识跟踪来微调预训练语言模型(LM-KT)。 该模型能准确预测学生正确回答问题的概率,并推广到训练集中未见过的问题。然后,我们使用LM-KT指定训练模型的目标和数据,以在学生和目标难度为条件下生成问题。我们的结果表明,我们在在线教育平台上成功地为第二语言学习者创造了新的,设计良好的语言翻译问题。
1.介绍
在线教育平台可以增加世界教育资源的可利用率。然而,为了能够在各种学习中都达到较好的结果,需要为每个学生都进行定制化教学。传统上,自适应教育方法涉及在预先制定的问题池中规划。这自然受到问题池中问题多样性和覆盖率的限制,以及课程规划算法的缩放能力。最近的方法,如个性化编程游戏的程序生成,但这仅限于特定的小领域。我们通过利用最近在深度生成模型中的成功,特别是语言模型(LMS)来解决这些限制。
许多教育项目都涉及到序列数据的使用,例如语言翻译,阅读理解,代数和演绎逻辑。同时,预训练的语言模型可以有效地处理来自各种领域的序列。在这项工作中,我们专注于自然语言序列,其中语言建模最近在捕获语言的抽象属性时表现出巨大的成功。具体而言,通过使用回答问题的难度作为更复杂的未来学习目标,我们展示了如何在反向翻译任务中简单利用预训练的语言模型以自适应地为特定的学生和目标难度生成问题。
我们介绍了一种基于LM的知识追踪模型(LM-KT),以预测学生回答新问题(例如,目标短语翻译)的难度。我们展示了LM-KT设计良好,从而允许我们为问题生成器定义学习难度:给定一个学生状态,基于LM-KT,能够生成目标难度的问题。我们在一个流行的第二语言学习平台Duolingo上,基于真实用户和响应,评估了LM-KT和生产模型。
2.背景和相关工作
在如何精确建模的学生“能力”和学习这一领域中存在大量的研究工作。例如,Item Response Theory(IRT)旨在根据对不同问题的回答结果来建模单个学生的能力,从而在学生和测试项目之间创造强的分解。同时,Computer Adaptive Testing(CAT)技术用于根据相关信息工具以选择测试项目来尽快确定学生的能力。然而,这些已被用于开发有效的标准化测试的方法,不一定能优化学生的学习体验。 我们专注于跟踪每个学生的不断提升的知识,选择目标难度的问题进行生成。
Knowledge Tracing (KT)。知识追踪(KT)基于学生的历史回答来建模其知识状态,从而有助于定制化教学。这受传统课程教育的启发,例如词汇的分布空间和数学的混合复习。为了解决早期KT方法中的简化假设,例如离散知识表示,Piech et al. (2015) 引入了深度知识追踪(DKT),它使用RNN为学生提供更复杂的知识表示。最近, SAINT+ 在流行的EdNet KT任务上显示了最先进的性能,其使用Transformer模型捕获时间信息,这激励了我们使用基于Transformer的LM。
Controllable Text Generation。可控文本生成旨在引导LMS生成包含所需的属性的句子。研究工作包括使用强化学习来控制质量指标,调整采样权重以控制诗歌风格,以及基于特定领域的code来学习。据我们所知,我们是第一个在教育背景中使用真实学生交互数据来实现可控生成的工作。
3.方法
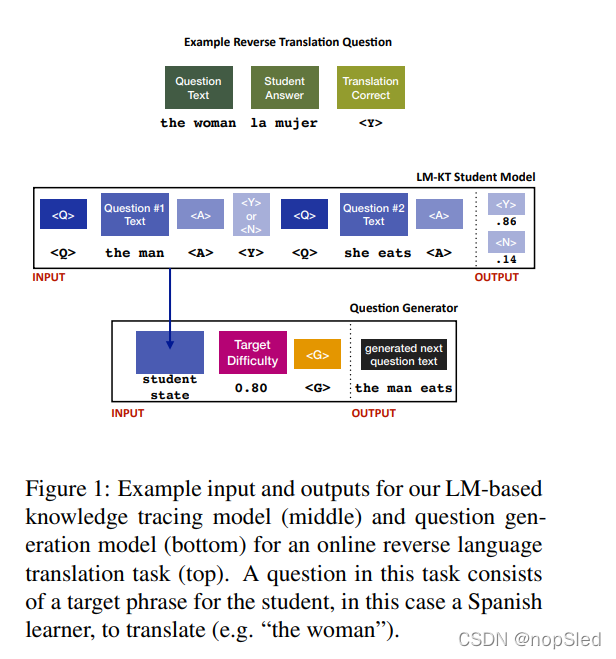
给定任意一个自回归语言模型(例如GPT-2),我们可以微调一个LM-KT model
(
p
θ
K
T
)
(p_{θ_{KT}})
(pθKT)来预测学生是否能正确回答问题。如果此模型具有良好设计的不确定性,我们可以使用其预测的正确答案的概率作为针对学生回答一个问题的代理。然后,我们训练一个question generation model(
p
θ
Q
G
p_θ{QG}
pθQG),以在学生和期望的目标难度上生成一个新的问题。
Question Representation。与将问题表示ID或简单手工特征的标准DKT不同,我们完全用文本来表示问题(例如,图1中的“she eats”)。 这是我们的工作的关键贡献,我们的最终目标是在文本中生成问题,并允许模型在语言特征上利用相似性。因此,我们将一个问题
q
q
q作为一系列单词,并且具有特殊的前缀和后缀字符:
q
i
=
<
Q
>
w
1
i
w
2
i
w
3
i
⋯
w
n
i
<
A
>
q_i=<Q>~w^i_1~w^i_2~w^i_3~\cdots~w^i_n~<A>
qi=<Q> w1i w2i w3i ⋯ wni <A>
Student State。我们将学生状态表示为一个不断发展的问题和他们的回答序列。与之前的KT工作一样,我们简单地将学生的响应表示为正确或不正确,对应着特殊的字符
<
Y
>
<Y>
<Y>和
<
N
>
<N>
<N>。因此,学生的当前状态表示为所有过去【问题,响应】对的序列:
s
j
=
q
1
j
a
1
j
q
2
j
a
2
j
.
.
.
q
m
j
a
m
j
,
a
i
∈
{
<
Y
>
,
<
N
>
}
s_j=q^j_1a^j_1q^j_2a^j_2...q^j_ma^j_m,a_i\in \{<Y>,<N>\}
sj=q1ja1jq2ja2j...qmjamj,ai∈{<Y>,<N>}
LM-KT。给定学生随时间推移的学习序列,我们可以轻松将知识追踪定义为自回归语言建模任务。给定一个学生数据集
D
D
D,
s
1
,
s
2
,
.
.
.
,
s
∣
D
∣
s_1,s_2,...,s_{|D|}
s1,s2,...,s∣D∣,我们采用标准训练目的找到最小化的参数
θ
K
T
θ_{KT}
θKT:
L
K
T
=
−
∑
i
=
1
∣
D
∣
∑
∣
x
(
i
)
∣
t
=
1
l
o
g
p
θ
K
T
(
x
t
(
i
)
∣
x
<
t
(
i
)
)
(1)
\mathcal L_{KT}=-\sum^{|D|}_{i=1}\sum^{|\textbf x^{(i)}|_{t=1}}log~p_{\theta_{KT}}(x^{(i)}_t|x^{(i)}_{\lt t})\tag{1}
LKT=−i=1∑∣D∣∑∣x(i)∣t=1log pθKT(xt(i)∣x<t(i))(1)
其中
x
(
j
)
=
(
x
1
(
j
)
,
.
.
.
.
,
x
∣
x
∣
(
j
)
)
\textbf x^{(j)}=(x^{(j)}_1,....,x^{(j)}_{|\textbf x|})
x(j)=(x1(j),....,x∣x∣(j))是与学生
s
j
s_j
sj对应的整个序列,包括他们所有过去的问题和答案。使用LM-KT模型的softmax输出(
p
θ
K
T
p_{θ_{KT}}
pθKT),我们将估计学生在回答特定问题时的难度作为
d
q
s
=
p
θ
K
T
(
<
Y
>
∣
s
,
q
)
d_{qs}=p_{θ_{KT}}(<Y>|s,q)
dqs=pθKT(<Y>∣s,q)。我们发现
p
θ
K
T
p_{θ_{KT}}
pθKT是一个良好的设计,这为真正的问题难度控制提供一个好的代理。
Question Generation。我们将问题生成定义为微调一个新的自回归LM。给定一个从未用于训练LM-KT的学生和问题的随机样本,我们可以构建由
s
i
d
i
<
G
>
q
i
s_i~d_i~<G>~q_i
si di <G> qi序列组成的新数据集
D
′
D'
D′,其中
<
G
>
<G>
<G>是特殊生成字符,
d
i
=
p
θ
K
T
(
<
Y
>
∣
s
i
,
q
i
)
d_i=p_{θ_{KT}}(<Y>|s_i,q_i)
di=pθKT(<Y>∣si,qi)是LM-KT分配的连续难度值。我们学习一个线性层,以将连续输入难度映射到维度和LM Word-Embeddings相同的难度控制向量
c
d
c_d
cd中,然后将其附加到字符嵌入。与LM-KT不同,我们训练我们的问题生成模型
p
θ
Q
G
p_{θ_{QG}}
pθQG,以最小化出现在
<
G
>
<G>
<G>字符之后的问题文本上的损失。 如果
t
g
t_g
tg是
<
G
>
<G>
<G>的字符索引,那么我们修改的损失是:
L
Q
G
=
−
∑
i
=
1
∣
D
′
∣
∑
t
=
t
g
+
1
x
(
i
)
l
o
g
p
θ
Q
G
(
x
i
(
i
)
∣
x
<
t
(
i
)
)
(2)
\mathcal L_{QG}=-\sum^{|D'|}_{i=1}\sum^{\textbf x^{(i)}}_{t=t_g+1}log~p_{\theta_{QG}}(x^{(i)}_i|x^{(i)}_{\lt t})\tag{2}
LQG=−i=1∑∣D′∣t=tg+1∑x(i)log pθQG(xi(i)∣x<t(i))(2)
其中序列
x
(
j
)
\textbf x^{(j)}
x(j)包含完整的
s
i
d
i
<
G
>
q
i
s_i~d_i~<G>~q_i
si di <G> qi序列。在推理时间,我们以
s
i
d
i
<
G
>
s_i~d_i~<G>
si di <G>为前缀生成字符
w
1
.
.
.
w
n
w_1 ... w_n
w1...wn。

















 1270
1270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









