






 研究发现大型语言模型如PaLM和Codex具有将数学自然语言转化为正规格式的能力,尤其在数学竞赛问题的正规化中表现突出。通过in-context learning,LLM能在部分问题上生成准确的Isabelle/HOL正规化语句,提高了神经定理证明器的证明成功率。这一发现为自动正规化和形式验证提供了新方法,有望连接自然语言和正规数学知识,促进机器学习与正规化系统间的正反馈循环。
研究发现大型语言模型如PaLM和Codex具有将数学自然语言转化为正规格式的能力,尤其在数学竞赛问题的正规化中表现突出。通过in-context learning,LLM能在部分问题上生成准确的Isabelle/HOL正规化语句,提高了神经定理证明器的证明成功率。这一发现为自动正规化和形式验证提供了新方法,有望连接自然语言和正规数学知识,促进机器学习与正规化系统间的正反馈循环。
摘要
自动正规化是指将数学自然语言自动转化为正规格式和证明的过程。一个成功的自动正规化系统可以应用到形式验证,程序合成和人工智能的领域。虽然自动正规化的长期目标在很长时间以来似乎是难以实现的,但我们展示了大型语言模型能为这一目标提供了新的前景。我们得到了令人惊讶的观察结果,即LLM可以成功地将一部分(25.3%)的数学竞赛题完全转化为 Isabelle/HOL 的正规格式。 我们通过对这些自动正规化定理进行训练来改善先前引入的神经定理证明器来证明这一过程的有用性。我们的方法能在MiniF2F定理证明基准上得到SOTA的结果,从而将证明率从29.6%提高到35.2%。
1.介绍

自动正规化是指将数学自然语言自动转化为正规语言的任务。成功的自动正规化工具在实践和理论研究上都具有巨大的意义。它能够降低当前正规化工作的成本,从长远来看,它可以将能进行自动数学推理的各个研究领域(例如自动定理证明和计算机代数)与由自然语言描述的数学知识连接起来。此外,自动正规化将是机器理解、掌握自然语言模糊性和正规语言准确性的正确途径。
最近大语言模型的进步显示出理解正规语言的有希望的能力。但是,现有的成功仅限于在网络上存在大量语料的正规语言(例如Python语言)。正规的数学数据非常稀缺。例如,最大的正规数学库之一,Archive of Formal Proofs,只有180MB的大小,不到大语言模型训练数据的0.18%。此外,与通常自然语言Docstrings被广泛使用的编程语言不同,自然语言和正规数学之间的对齐数据几乎为零。 因此,目前尚不清楚最近的成功是否可以直接有助于自动化的发展。
在这项工作中,我们探索了大型语言模型自动正规化的前景。令我们惊讶的是,我们发现大型语言模型在交互式定理证明器中正规化数学自然语言已经具有不错的能力。有关完美的自动正规化示例,请参见图1。该模型不仅转化为句法正确的Isabelle代码,而且还掌握了自然语言的重要推理。我们随机选择150个正规化结果并手动评估它们的正确性。其中,LLM能够生成38个完美的正规化!为了应用,我们进一步证明自动正规化可以为神经定理证明器提供有用的训练数据。我们将自动正规化语句用作Isabelle/HOL神经定理证明器证明搜索的目标。基于自动正规化发现的证明,在我们对神经定理证明器进行微调后,其在MiniF2F基准测试中的成功率大大增加,从而获得了35.2%的最新结果。
2.Related Work
早期机器学习在定理证明中的应用包括Schulz [42]和Urban [45]的工作,并发展为使用机器学习技术直接指导交互式证明助手[14]。然后,深度学习的革命从DeepMath开始[1,33],并激发了对该主题的一轮新的兴趣。
目前已经提出了几种方法来解决数据稀缺性问题:使用模仿无关的强化学习来避免需要对人类证明数据进行训练[31、5、14、51]。另外,hindsight经验回放[2]也用于生成其他训练数据[4]。 Hahn et al. [18], Schmitt et al. [41], Kreber & Hahn [29] and Wu et al. [52] 表明,在合成公式上训练对于时间逻辑和不平等性可以成功。Rabe et al. [39]从正规的数学语句中屏蔽不同的子表达式,并为每个源语句生成了100个训练示例。Skip-tree数据也可用于改善神经定理证明的性能[21]。
Wang et al. [48] 探索了使用有监督和无监督的翻译技术。有监督的翻译生成了有趣的结果,但依赖于由Mizar定理证明器生成的合成(Naturallooking)数据,而我们依赖于通过自监督训练的语言模型。
3.Background
Formal Mathematics。数学和计算机科学的一些重要且复杂的结果是通过使用交互式定理证明器来手工正规化,例如four color theorem,Kepler conjecture,odd-order theorem和verification of a microkernel。这能使我们可以完全确定证明的正确性,这对于解决复杂数学证明的正确性或证明在与安全至关重要应用中使用软件的某些特性(例如飞机组件)可能具有很大的价值。
这些项目依赖于交互式定理证明器,例如Isabelle,Coq,HOL Light和Lean,它们本质上是编程语言,使用户能够以正规语言输入其语句和证明,然后可以自动检查以确保正确性。交互式定理证明器提供了有限的自动化,但是正规化复杂问题的项目通常需要专家的多年的繁琐工作。只有在诸如芯片设计和操作系统中驱动程序验证之类的狭窄领域才具有自动化逻辑。
自动正规化和定理证明的自动化最终可能使数学成为普遍可用的工具,并促进科学的范式转变和安全相关软件的开发。 但是,我们对数学正规化的兴趣还有一个额外方面。我们认为自动正规化将达到双重目的,不仅能加速数学推理工具的开发,而且还提供了一种用于机器学习系统的手段,从而使机器学习和正规化系统之间具有正反馈回路(参见[44]) )。
Large Language Models。我们的工作严重依赖于大型语言模型(LLM),尤其是PaLM和Codex。这些模型的训练目标给定一些前缀来预测下一个单词。这使我们能够在任意数目文本上训练这些模型。在数千亿个单词上训练了模型之后,它们通常能够生成高质量的文本。我们还可以给这些模型输入一个任意的前缀(提示),这使我们可以控制它们的生成内容。在新闻文章,对话,摘要,笑话和诗歌生成上已经证明了这一点。LLM同样在诸如GSM8K和MATH等数学单词问题数据集上进行了评估,并已证明随着规模的增加这些模型可以在这些基准上取得进展。
In-context Learning。大型语言模型显示出在当前输入(上下文)上学习模式和任务的非凡能力:这称为in-context learning或few-shot learning。例如,如果我们使用少量英语和对应法语的句子对来提示语言模型,并以新的英语句子结尾,那么语言模型很可能会掌握翻译任务,并尝试翻译最后的英语句子。例如,该观察结果已被用来实现强大的翻译性能,而无需使用大量的平行句子对语料。
这允许我们可以仅提供几个正规化样例来指定LLM自动正规化的任务。在第4节中,我们将详细说明我们如何确切地使用in-context learning进行自动正规化。
4.Autoformalization for Mathematical Competition Problems
受LLM通过联合训练网络上的自然语言和代码,并成功生成计算机代码的启发,我们在交互式定理定理证明器Isabelle上探索了LLM将数学自然语言转变成正规定理能力。这可以看作是一个机器翻译任务,其中输入语言是英语,输出语言是应用到Isabelle的正规代码。
我们首先在一个有约束设置下研究自动正规化,即对数学竞赛问题进行正规化。该设置的优势是,大多数必要的背景理论和定义已在Isabelle的当前库中正规化,因此通常可以在不引入其他定义的情况下进行正规化。
我们使用当前任务对LLMS自动正规化的能力进行评估。我们手动选择了两个有趣的数学自然语言语句,并提示各种尺寸的PaLM模型以及Codex将它们转化为Isabelle中的正规化语句。接下来,我们研究了一个数据集,该数据集中具有人类编写的真实正规化格式。该数据集是miniF2F数据集的子集,由140个代数问题和120个数字理论问题组成。使用人类正规化结果为参考,我们计算了由几个LLM生产的正规化结果的BLEU评分。最后,我们对150个问题的错误正规化结果进行人工分析。
请注意,许多数学竞赛问题通常是要求人们找到该问题对应答案的形式,而不是证明给定的命题。但是,正规化的数学描述是以命题的形式而不是问题的形式给出。要将问题转换为命题,我们在问题之后附加了最终答案:
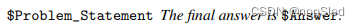
我们用于自动正规化的提示格式为:
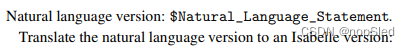
4.1 Mathematical Competition Datasets
4.2 Case Studies

Experimental setup。对于我们所有的实验,我们都使用标准的贪心解码算法来获取自动正规化结果。我们随机选择两个数学语句来构建提示。构造提示时,不执行任何提示工程或微调。示例如图2所示。案例研究中使用的自然语言问题语句来自miniF2F数据集。在下面的案例研究中,我们将语言模型的输出标红,以将其与提示区分开。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









