






摘要
使用one-hot目标分布训练的神经对话模型会面临over-confidence问题,这导致生成的多样性较差,正如各种文献说描述的那样。尽管诸如label smoothing之类的现有方法可以减轻此问题,但它们无法适应各种对话上下文。在本文中,我们提出了一种Adaptive Label Smoothing (AdaLabel) 方法,该方法可以在每个时刻基于不同的上下文自适应地估计目标标签的分布。预测分布中的最大概率用于修改由轻量双向解码器模块产生的软目标分布。 最终的目标分布同时基于先前和未来的上下文,并经过调整以避免对话模型过度训练。我们的模型可以以end-to-end的方式进行训练。在两个基准数据集上进行的广泛实验表明,我们的方法在生成多样性响应方面优于各种竞争基线。
1.介绍

神经模型的成功大大推动了对话生成的研究。但是,这些模型中的大多数都会面临低多样性问题的困扰,在该问题中,模型往往会生成平淡无奇的响应,例如I don’t know或I’m OK。尽管已经提出了各种方法来解决这个问题,但神经模型生成的响应与人类响应之间仍然存在显着差距。此外,在改善生成响应的多样性时,一些现有方法甚至可能损害流利或连贯性。
最近,Jiang and de Rijke (2018); Jiang et al. (2019) 表明,低多样性问题与over-confidence问题之间存在紧密的联系。即,over-confidence的对话模型倾向于生成低多样性的响应。主要原因是有监督的训练目标。具体而言,基于one-hot标签,使用 Maximum Likelihood Estimation (MLE)目标训练的对话生成模型,会使模型倾向使用高频token,并且产生over-confident的概率估计。Hinton et al. (2015) 和 Yang et al. (2018) 建议,理想的训练目标应该是一个软目标,该目标能为多个有效候选分配概率(请参见图1)。有了这样的软目标,就可以缓解over-confidence的问题,因此可以改善生成响应的多样性。
不幸的是,理想的软目标是具有挑战性的。早期的工作尝试使用label smoothing来解决此问题,即,将一个很小的概率平均分配给非目标单词。但是,以这种方式构建的目标分布与理想软分布具有较大差距:首先,目标词的概率是手动设置且固定的,无法适应不同的上下文。但是,正如Holtzman et al. (2020) 证明的,人类文本分布在每个token中困惑中表现出显着的波动。我们认为应将不同的目标概率用于不同的上下文。其次,非目标单词上概率的均匀分配忽略了上下文和每个单词之间的语义关系。理想情况下,如果一个单词与上下文更相关,则应获得更多的概率。对于图1中所示的示例,“fun”一词更有可能出现在“I make the robots seem more _”中,而不是单词“bank”。
为了解决上述问题,我们提出了一种Adaptive Label smoothing (AdaLabel) 方法,该方法可以在每个时刻基于不同的上下文自适应地估计目标标签的分布。具体而言,对于训练数据中的每个目标词
y
t
y_t
yt,首先获得当前模型预测的概率分布。该分布中的最大概率
p
m
a
x
p_{max}
pmax用于衡量当前预测的置信度,即较高的
p
m
a
x
p_{max}
pmax意味着对当前预测的置信度更高。为了避免过度自信,我们将
p
m
a
x
p_{max}
pmax用作训练过程中目标词
y
t
y_t
yt的监督信号,以便模型能够在正确预测
y
t
y_t
yt后就不会继续沿着
y
t
y_t
yt进行优化。另外,还引入了单词级的因子,以促进学习低频单词。
此外,我们引入了一个新的辅助解码器模块
D
a
D_a
Da,以在每个训练时刻为这些非目标单词生成有监督信号。
D
a
D_a
Da仅包含一个transformer块,并且可以根据双向上下文进行优化以预测单词。另外使用了一种新的目标mask注意力方案,以防止
D
a
D_a
Da在训练过程中看到目标词。该方案还可以使
D
a
D_a
Da实现并行训练和推断。
我们在两个基准数据集上进行了广泛的实验:DailyDialog和OpenSubtitles。我们的方法表现优于各种竞争基线,并显着提高了生成响应的多样性,同时确保流利性和相干性。我们的主要贡献总结如下:
- 我们提出了AdaLabel,该方法可以基于当前上下文和模型的置信度,生成软目标分布。具体而言,AdaLabel能确保如果模型正确预测了 y t y_t yt,则不会继续沿着目标单词 y t y_t yt进行优化。这样可以防止我们的模型 over-confident。
- 我们引入了一个轻量的双向解码器,该解码器可以为非目标单词生成基于上下文的监督信号。并设计了一种新的目标MASK注意力方案,以促进该解码器的并行训练和推断。
- 在具有自动和人类评估结果的两个基准对话数据集上的广泛实验表明,我们的方法有助于缓解模型over-confident的问题,并显着改善模型的多样性。
2.相关工作
Diversity Promotion。解决神经对话模型低多样性问题的现有方法通常分为两类:
第一类是基于训练的,例如在对话模型中设计新的训练目标或引入潜在变量。一些方法还试图完善MLE损失中使用的训练目标,或直接用辅助损失项来惩罚重复响应。与这些现有方法不同,我们的方法试图通过利用当前预测结果来调整训练目标。
第二类是基于解码的,其中设计了不同的启发式解码规则。请注意,这些解码技术与模型设置无关,我们的方法可以与这些技术结合使用。
Confidence Calibration。现代深层神经网络会面临over-confidence的问题,并提出了各种解决方案。与 Jiang and de Rijke (2018); Jiang et al. (2019) 的工作类似,我们提出了一种方法来解决该问题,以改善生成响应的多样性。但是,与现有方法不同,我们的方法可以对目标分布进行更灵活的控制。
Knowledge Distillation。与我们工作类似的另一个重要技术是知识蒸馏,其中一个学习好的teacher模型通过最小化KL项从而将知识蒸馏到student模型中。
与我们方法最相关的工作是C-MLM方法,其中BERT模型被微调为一个teacher。我们的方法和C-MLM的主要区别在于,我们的辅助解码器
D
a
D_a
Da是一个一层模块,该模块与对话模型联合训练。但是,C-MLM中的BERT teacher包含更多的参数,并使用预训练和微调过程进行训练。此外,
D
a
D_a
Da中的目标MASK注意力方案可以为每个训练序列
Y
Y
Y进行并行推理。相比之下,BERT teacher需要多次独立的forward过程。
3.方法
3.1 Background: MLE with Hard Target
生成式对话建模的目的是学习条件概率分布
p
(
Y
∣
X
)
p(Y|X)
p(Y∣X),其中
X
X
X是对话上下文,
Y
=
y
1
,
.
.
.
,
y
T
Y=y_1,...,y_T
Y=y1,...,yT是响应单词序列,
y
i
∈
V
y_i∈\mathcal V
yi∈V是来词表
V
\mathcal V
V中一个单词。在自回归方式中,
p
(
Y
∣
X
)
p(Y|X)
p(Y∣X)被分解为
∏
t
p
(
y
t
∣
y
<
t
,
X
)
\prod_t p(y_t|y_{\lt t},X)
∏tp(yt∣y<t,X)。对于训练序列
Y
Y
Y中的每个目标词
y
t
y_t
yt,常规的MLE训练方法试图优化以下交叉熵损失:
L
(
q
,
p
)
=
−
∑
w
k
∈
V
q
k
l
o
g
[
p
(
w
k
∣
y
<
t
,
X
)
]
,
(1)
\mathcal L(\textbf q,\textbf p)=-\sum_{w_k\in \mathcal V}q_klog[p(w_k|y_{\lt t},X)],\tag{1}
L(q,p)=−wk∈V∑qklog[p(wk∣y<t,X)],(1)
其中
q
\textbf q
q是一个one-hot分布(即硬目标),该分布为目标单词
y
t
y_t
yt分配的概率为1,其它则为0。
3.2 Method Overview
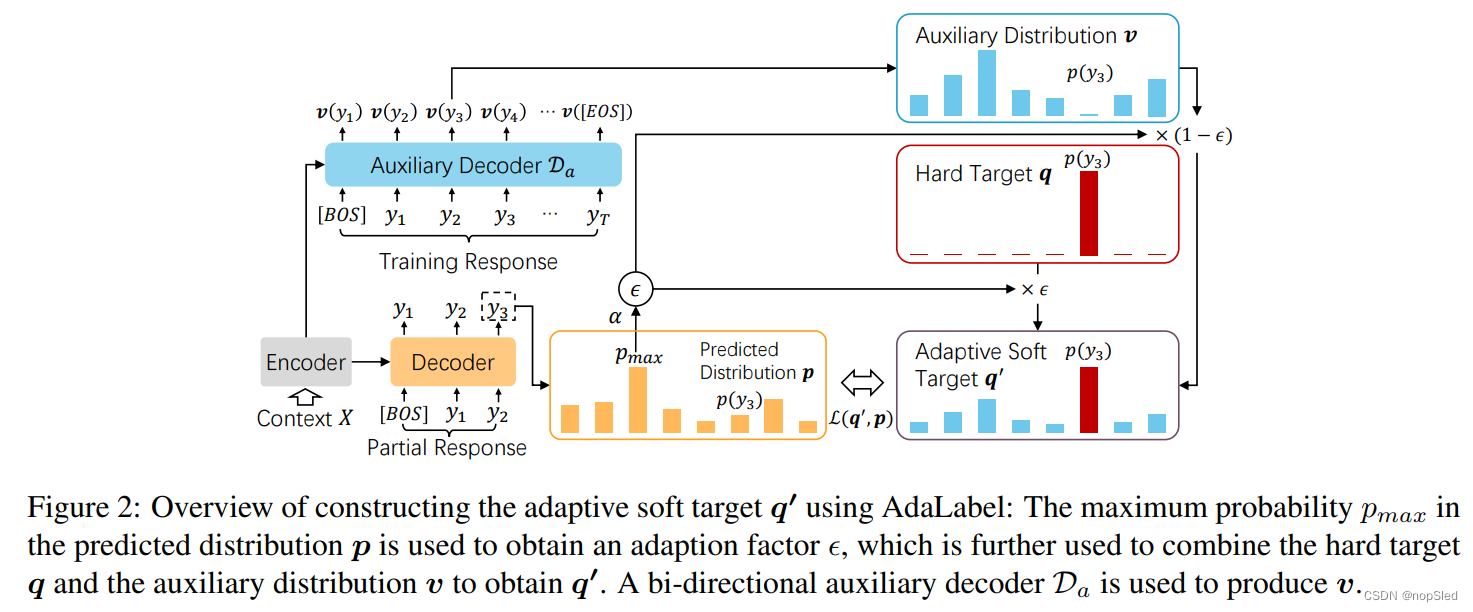
我们提出去自适应构建一个软的目标分布
q
′
\textbf q'
q′,来替换等式1中的
q
\textbf q
q。即:
q
′
=
ϵ
⋅
q
+
(
1
−
ϵ
)
⋅
v
,
(2)
\textbf q'=\epsilon \cdot \textbf q+(1-\epsilon)\cdot \textbf v,\tag{2}
q′=ϵ⋅q+(1−ϵ)⋅v,(2)
其中,
ϵ
∈
[
0
,
1
]
\epsilon\in [0,1]
ϵ∈[0,1]是一个调整因子,并且
v
\textbf v
v是一个取决于当前时刻的辅助分布向量(如图2所示)。
在这项研究中,我们约束
v
\textbf v
v为目标单词
y
t
y_t
yt分配一个零概率,而非目标单词
V
≠
y
t
=
{
y
i
∣
y
i
∈
V
,
y
i
6
=
y
t
}
\mathcal V_{\ne y_t}=\{yi |yi∈V,yi 6 = yt\}
V=yt={yi∣yi∈V,yi6=yt}分配非零概率。此约束使我们能够显式控制分配给
y
t
y_t
yt的监督信号。具体而言,等式2中的第一项
ε
⋅
q
ε·\textbf q
ε⋅q和第二项
(
1
−
ε
)
⋅
v
(1-ε)·\textbf v
(1−ε)⋅v分别确定了
q
′
\textbf q'
q′分配给
y
t
y_t
yt和
V
≠
y
t
V_{\ne y_t}
V=yt的概率有多少。这种设置与传统的知识蒸馏不同,因为它有利于对
q
′
\textbf q'
q′进行更灵活的控制,因为我们可以使用因子
ε
ε
ε来确定为目标词
y
t
y_t
yt提供的监督信号。以下各节详细介绍了如何计算
ε
ε
ε和
v
\textbf v
v。
3.3 Target Word Probability
我们通过操纵等式2中的自适应因子
ε
ε
ε来控制
p
′
\textbf p'
p′中目标词
y
t
y_t
yt的概率。具体而言,对于一个对话样例
<
X
,
Y
>
<X,Y>
<X,Y>和每个目标词
y
t
∈
Y
y_t∈Y
yt∈Y,当前的分布
p
(
⋅
∣
y
<
t
,
X
)
p(·|y_{<t},X)
p(⋅∣y<t,X)首先被计算,并获得此分布中的最大概率:
p
m
a
x
=
m
a
x
w
k
∈
V
p
(
w
k
∣
y
<
t
,
X
)
.
(3)
p_{max}=\mathop{max}\limits_{w_k\in \mathcal V}~p(w_k|y_{\lt t}, X).\tag{3}
pmax=wk∈Vmax p(wk∣y<t,X).(3)
然后
ϵ
\epsilon
ϵ通过以下方式获取:
ϵ
=
m
a
x
(
p
m
a
x
,
λ
)
,
(4)
\epsilon=max(p_{max},\lambda),\tag{4}
ϵ=max(pmax,λ),(4)
其中,
λ
\lambda
λ作为
ϵ
\epsilon
ϵ的下界(即,
ϵ
≥
λ
\epsilon\ge \lambda
ϵ≥λ)。
等式4背后的基本直觉是当
p
m
a
x
p_{max}
pmax足够大时,就设置
ε
=
p
m
a
x
ε=p_{max}
ε=pmax。 这种设计能够防止我们的模型接收到超过
p
m
a
x
p_{max}
pmax的监督信号,即当当前时刻预测的置信度足够高时。
此外,为了确保目标词
y
t
y_t
yt始终在
q
′
\textbf q'
q′中获得最大的概率的监督信号,即确保
ε
>
(
1
−
ε
)
⋅
m
a
x
(
v
)
ε>(1-ε)·max(\textbf v)
ε>(1−ε)⋅max(v)(见等式2),其中
m
a
x
(
v
)
max(\textbf v)
max(v)是非目标词
V
≠
y
t
\mathcal V_{\ne y_t}
V=yt的最大概率,我们必须强迫
ε
>
m
a
x
(
v
)
1
+
m
a
x
(
v
)
ε>\frac{max(v)}{1+max(v)}
ε>1+max(v)max(v)。因此,我们提出将
ε
ε
ε的下界
λ
λ
λ计算为:
λ
=
m
a
x
(
v
)
1
+
m
a
x
(
v
)
+
η
,
(5)
\lambda=\frac{max(\textbf v)}{1+max(\textbf v)}+\eta,\tag{5}
λ=1+max(v)max(v)+η,(5)
其中
η
>
0
\eta\gt 0
η>0是一个超参,用于控制目标单词和非目标单词概率之间的边界。
为了促进更快的收敛并更好地学习低概率单词,我们进一步引入了经验因子
α
∈
[
0
,
1
]
α∈[0,1]
α∈[0,1],以根据等式4调整
ε
ε
ε的计算:
ϵ
=
1
−
α
⋅
(
1
−
m
a
x
(
p
m
a
x
,
λ
)
)
,
(6)
\epsilon=1-\alpha\cdot(1-max(p_{max,\lambda})),\tag{6}
ϵ=1−α⋅(1−max(pmax,λ)),(6)
其中,
α
\alpha
α被计算为
p
m
a
x
p_{max}
pmax的相对比率:
α
=
[
p
(
y
t
∣
y
<
t
,
X
)
p
m
a
x
]
2
(7)
\alpha=[\frac{p(y_t|y_{\lt t},X)}{p_{max}}]^2\tag{7}
α=[pmaxp(yt∣y<t,X)]2(7)
其中
p
(
y
t
∣
y
<
t
,
X
)
p(y_t|y_{<t},X)
p(yt∣y<t,X)是目标词
y
t
y_t
yt的预测概率。请注意,如果
α
=
1
α=1
α=1,则等式4和等式6是相等的。直觉上,
α
\alpha
α会加速低频单词的训练,因为如果
y
t
y_t
yt在语料中是低频单词,那么
y
t
y_t
yt通常未被充分训练,因此
p
(
y
t
∣
y
<
t
,
X
)
p(y_t|y_{\lt t},X)
p(yt∣y<t,X)会较小。这导致了一个较小的
α
值
\alpha值
α值,从而增加
y
t
y_t
yt在
p
′
\textbf p'
p′中的概率。
注意到,
ϵ
\epsilon
ϵ,
λ
\lambda
λ,和
α
\alpha
α都是和当前时刻相关的变量,其中只有
η
\eta
η是一个固定值的超参。这允许值会随着上下文动态调整。在我们的实验中,等式6被用于计算
ϵ
\epsilon
ϵ。
3.4 Non-target Words Probabilities
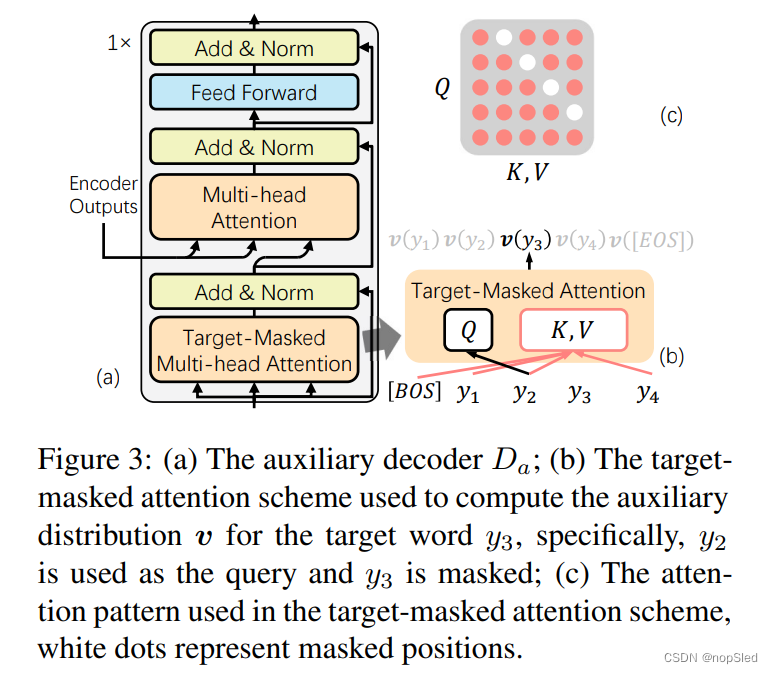
等式2中的辅助分布
v
\textbf v
v是使用一个辅助解码器
D
a
D_a
Da来计算的,该解码器是基于单层transformer的解码器,与生成模型共同优化。图3显示了
D
a
D_a
Da的结构,其设计了一种新的目标MASK注意力方案,以在计算相应的
v
\textbf v
v时mask解码器自注意力模块中的每个目标词
y
t
y_t
yt(见图3B和3C)。这样,在预测
y
t
y_t
yt的辅助分布
v
\textbf v
v时,可以利用双向上下文。此外,重要的是在
D
a
D_a
Da中仅使用一个解码器层,因为在
D
a
D_a
Da中堆叠多个层会泄漏
y
t
y_t
yt的信息。
请注意,在
D
a
D_a
Da中使用一层网络并不一定会降级其性能。在第5.1节中我们的实验结果表明,借助双向上下文,
D
a
D_a
Da的准确性在很大程度上优于比
D
a
D_a
Da更深得多的单向对话解码器。此外,对于响应
Y
Y
Y的训练,
D
a
D_a
Da的结构使我们能够在单个forward内对所有目标单词并行推断辅助分布。这与Chen et al. (2020) 使用的BERTteacher不同,其需要多个独立的forward来获取
y
y
y中所有单词的教师分布。
当训练
D
a
D_a
Da时,我们使用下面标准的MLE损失来优化每个目标单词
y
t
y_t
yt:
L
(
q
,
v
)
=
−
∑
k
=
1
∣
V
∣
q
k
l
o
g
v
k
,
(8)
\mathcal L(\textbf q,\textbf v)=-\sum^{|\mathcal V|}_{k=1}q_klogv_k,\tag{8}
L(q,v)=−k=1∑∣V∣qklogvk,(8)
D
a
D_a
Da的输出用作推断
v
\textbf v
v的logits,以在等式2中进一步使用,具体来说,目标词
y
t
y_t
yt对应的logit在softmax之前被mask至
−
∞
-∞
−∞,以确保
y
t
y_t
yt的概率在
v
\textbf v
v中始终为0。遵循Tang et al. (2020) 使用的方法,在推断等式2的
v
\textbf v
v之前,要截断其余logits的头和尾,即,所有logits均以降序排名,并且仅保留从
n
n
n到
m
m
m的logits值,而将其余logits mask到
−
∞
-∞
−∞。这将
v
\textbf v
v中的头和尾概率mask到零。我们认为,截断
v
\textbf v
v中尾部的概率能过滤噪声,截断
v
\textbf v
v中头部的概率能鼓励对话模型更多地关注低概率单词。在我们的实验中,我们设置
n
=
2
n=2
n=2和
m
=
500
m=500
m=500。广泛的超参数搜索表明我们的方法对n和m的值不敏感。
我们的辅助解码器
D
a
D_a
Da与常规知识蒸馏方法中使用的teacher模型之间存在两个主要区别:首先,传统的teacher模型通常比student更重要,而
D
a
D_a
Da则相当轻巧。其次,通常在蒸馏过程中传统的teacher模型在被使用之前需要先进行训练,而
D
a
D_a
Da则与我们的对话模型共同训练。

















 729
729

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









