






摘要
通过以自然语言提示为条件,大型语言模型(LLMS)显示出令人印象深刻的通用计算能力。但是,任务性能在很大程度上取决于用于指导模型的提示的质量,并且最有效的提示是由人类手工编写的。受经典程序合成和人类提示工程方法的启发,我们提出Automatic Prompt Engineer (APE)来指导提示的生成和选择。在我们的方法中,我们将提示看作“程序”,通过在由LLM提出的提示候选池中进行搜索来优化,以最大化所选的分数函数。为了评估所选提示的质量,我们根据选定的提示评估另一个LLM的zero-shot性能。在24个NLP任务上的实验表明,我们自动生成的提示要优于先前的LLM基线,并在19/24任务个中生成的提示要比人类编写的提示更好或相当。我们进行了广泛的定性和定量分析以探索APE的性能。我们表明,APE工程的提示可以应用于指导模型生成具有真实性和/或信息丰富的文本,并通过简单地将其拼接到标准in-context学习提示前来提高few-shot学习的性能。
1.介绍
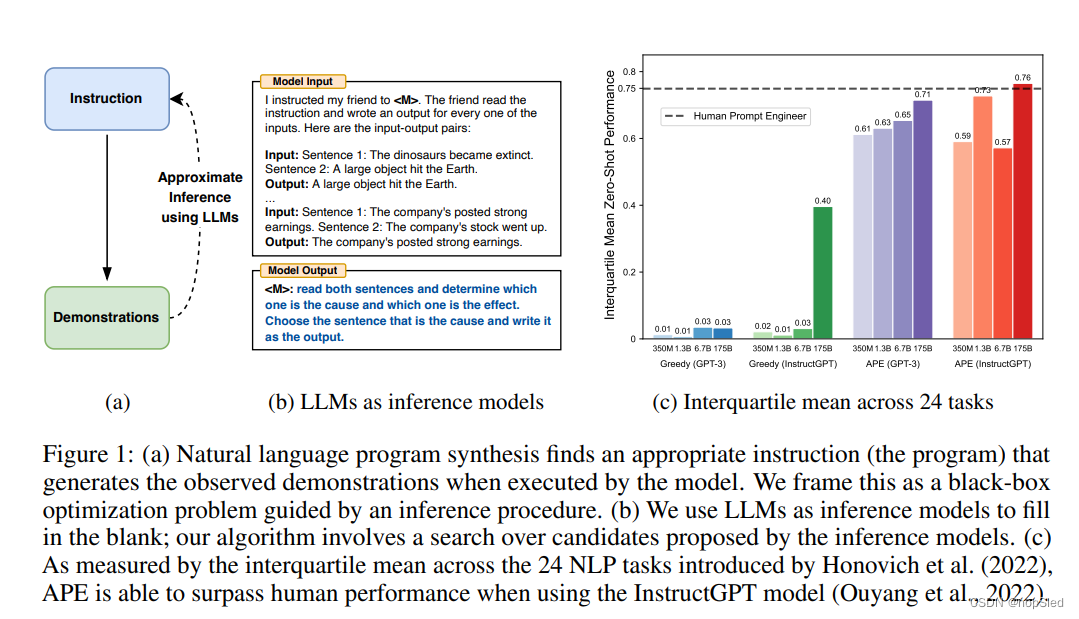
模型规模和基于注意力网络结构的结合使语言模型具有前所未有的通用计算能力。这些所谓的“大型语言模型”(LLMS)在各种任务范围内(包括zero-shot和few-shot学习)表现出了显着的甚至是超越人类的能力。但是,有了通用性,就会出现一个控制问题:我们如何使LLMS做我们想让其做的事?
为了回答这个问题,并指导LLM完成目标行为,最近的工作考虑了微调,in-context学习以及若干提示生成的形式,这包括基于软提示的可微分微调和自然语言提示工程。后者更受研究人员的关注,因为它为人类提供了与机器通信的自然语言接口,并且不仅能应用于LLM,还能与其他通用模型(如基于提示的图像合成器)交互,因此,研究人员对提示的设计和生成表现出了巨大兴趣(有关示例,请参见附录A)。
之所以需要对提示进行设计的原因是,原始的自然语言提示并不是总能生成期望的结果。因此,人类用户必须尝试各种提示来生成所需的行为,因为他们不知道哪些提示是模型能够理解的。我们可以通过将LLM视为执行自然语言特定程序的黑盒计算机来理解这一点:虽然它们可以执行广泛的自然语言程序,但处理这些程序的方式可能对人类而言并不直观,并且只有在下游任务执行这些指令时才能进行评估。
·为了减少创建和验证指令是否有效的所需要的人类成本,我们提出使用LLM自动生成并选择指令的新算法。我们此问题称为natural language program synthesis,并提出使用LLM作为黑盒优化问题来解决它,以生成和搜索启发式可行的候选解决方案。为此,我们通过三种方式来利用LLM的通用能力。首先,我们使用LLM作为推理模型,并使用基于输入-输出对的小演示集合来生成候选指令。然后,我们通过对每一个指令计算一个控制目标的分数,来指导搜索过程。最后,我们提出了一种迭代蒙特卡洛搜索方法,其中LLM通过提出语义上相似的指令变体来改善最佳候选。从直觉上讲,我们的算法要求LLM基于演示生成一组指令候选集合,然后要求他们评估哪些指示更符合目标。我们称我们的算法为Automatic Prompt Engineer (APE)。我们的主要贡献如下:
- 我们将指令生成作为自然语言程序合成的问题,并将其作为引导LLM的黑盒优化问题,然后提出一种简单但有效的迭代蒙特卡洛搜索方法以近似解决方案。
- 我们提出的APE方法通过模型生成的提示,在19/24 NLP任务上达到了zero-shot学习的人类水平。
- 我们提供了广泛的定性和定量分析,以探索APE的各个方面,并展示了APE能改善few-shot学习并指导模型生成具有真实性和/或信息丰富的文本。
2.相关工作
·Large Language Models。已经证明,通过增加transformer语言模型的大小,训练数据并进行训练,可以显著改善各种下游NLP任务的性能。由于这种现象,已经发现了许多LLM的新能力,包括few-shot in-context学习,zero-shot问题解决,思维推理链,指导导归纳。在本文中,我们将LLM视为一个黑盒计算机,该计算机执行由自然语言指令描述的程序,并研究如何使用模型生成的指令来控制LLM的行为。
·Prompt Engineering。提示为人类提供了一种自然而直观的和类似LLM等通用模型交互和使用的接口。由于其灵活性,提示已被广泛用作解决NLP任务的通用方法。但是,LLM需要使用仔细设计的手动或自动提示,因为模型似乎无法像人类一样理解所有提示。尽管许多成功的提示微调方法使用基于梯度的方法在连续空间上进行优化,但随着梯度计算变得越来越昂贵,并且模型可能无法提供访问梯度的API时,这变得不那么实用。在我们的论文中,我们使用了离散提示搜索方法中各种组件,例如提示生成,提示评分和提示释义,以通过直接在自然语言指令空间中搜索来优化指令。与过去的针对每个特定组件使用特定模型,并严重依赖人类模板的工作相比,我们表明整个提示搜索过程可以由单个LLM进行。
Program Synthesis。程序合成涉及在“程序空间”上进行自动搜索,以找到满足特定规范的程序。当前的程序合成能满足各种规格,包括给的输出-输出示例和自然语言。合理的程序空间的范围也已经增长,从特定领域的语言到通用编程语言。与需要合适的结构化假设空间和组件库的先前方法相反,我们利用LLMS提供的结构来搜索自然语言程序的空间。使用的推理模型通过将搜索空间限制为有限的表达空间中来加快搜索。受此方法的启发,我们将LLM用作近似推理模型来基于一小部分症状生成程序候选。与经典程序合成不同,我们的推理模型不需要任何训练,也不需要对各种任务进行概括。
3.NATURAL LANGUAGE PROGRAM SYNTHESIS USING LLMS
我们考虑由数据集
D
t
r
a
i
n
=
{
(
Q
,
A
)
}
\mathcal D_{train}=\{(Q,A)\}
Dtrain={(Q,A)}及用于提示的模型
M
\mathcal M
M指定的一个任务,其中数据集是从种群
X
\mathcal X
X中采样的输入输出演示。自然语言程序合成的目标是找到单个指令
ρ
ρ
ρ,使得, 当使用指令和输入的拼接
[
ρ
;
Q
]
[ρ;Q]
[ρ;Q]进行提示时,
M
\mathcal M
M能产生相应的输出
A
A
A。更正式地,我们将其作为一个优化问题,在该问题中,我们需要寻找一个指令
ρ
ρ
ρ,以最大化样本分数
f
(
ρ
,
Q
,
A
)
f(ρ,Q,A)
f(ρ,Q,A)的期望:
ρ
∗
=
a
r
g
m
a
x
ρ
f
(
ρ
)
=
a
r
g
m
a
x
ρ
E
(
Q
,
A
)
[
f
(
ρ
,
Q
,
A
)
]
(1)
ρ*=\mathop{argmax}\limits_{ρ}f(ρ)=\mathop{argmax}\limits_{ρ}\mathbb E_{(Q,A)}[f(ρ,Q,A)]\tag{1}
ρ∗=ρargmaxf(ρ)=ρargmaxE(Q,A)[f(ρ,Q,A)](1)
请注意,通常,
Q
Q
Q可能是空字符串,因此我们将
ρ
ρ
ρ作为直接能产生输出
{
A
}
\{A\}
{A}的提示来优化。尽管人类已广泛尝试了这项任务,但我们对指令与模型
M
\mathcal M
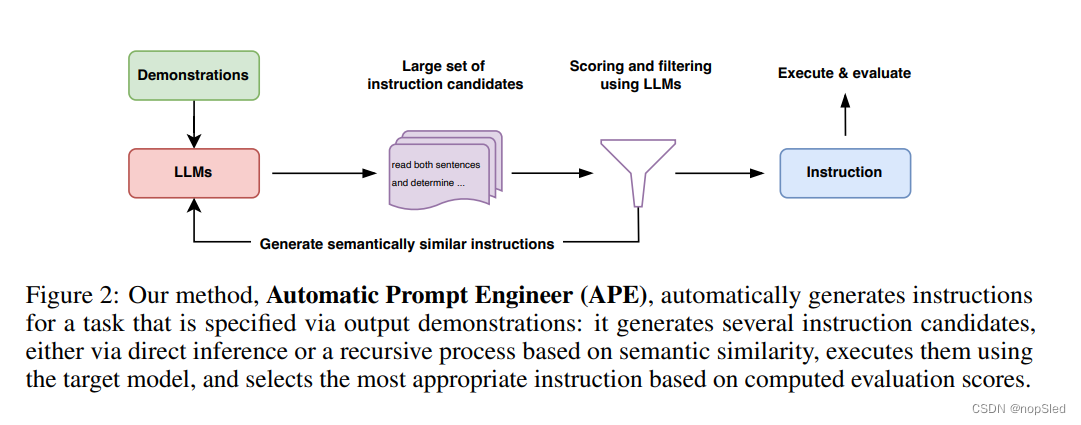
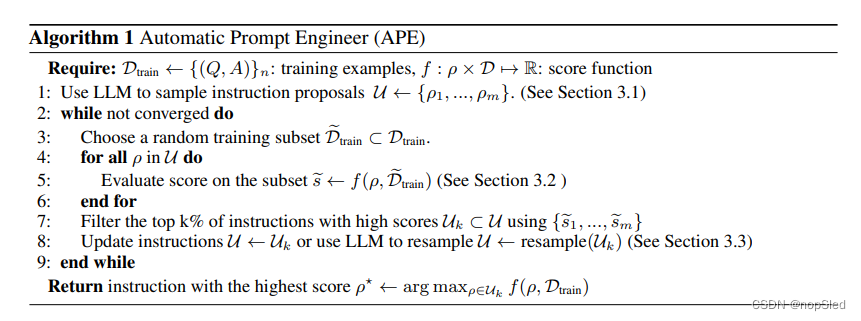
M的兼容程度一无所知。因此,我们提出将这个人类难以解决的问题视为由LLM指导的黑盒优化过程。我们的算法APE在两个关键组件中(生成和评分)都使用了LLM。如图2所示,并在算法1中进行了总结,APE首先提出了一些候选提示,然后根据所选的分数函数过滤/完善候选集,最终选择具有最高分数的指令。我们接下来将分别讨论提示生成和评分。
3.1 INITIAL PROPOSAL DISTRIBUTIONS

由于搜索空间是无限的,因此找到正确的指令可能非常困难,这使自然语言程序合成很棘手。NLP的最新进展表明,语言模型非常擅长生成多样化的自然语言文本。 因此,我们考虑利用经过预训练的LLM提出一套好的候选方案集
U
\mathcal U
U,以指导我们的搜索过程。虽然来自LLM的随机样本不太可能产生所需的
(
Q
,
A
)
(Q,A)
(Q,A)对,但我们可以要求LLM在给定输入-输出演示的情况下大致推断出具有较高分数的最可能的指令; 即,从
P
(
ρ
∣
D
t
r
a
i
n
,
f
(
ρ
)
i
s
h
i
g
h
)
P(ρ|\mathcal D_{train},f(ρ)~is~high)
P(ρ∣Dtrain,f(ρ) is high)中估计样本。
Forward Mode Generation。我们考虑了两种方法来从
P
(
ρ
∣
D
t
r
a
i
n
,
f
(
ρ
)
i
s
h
i
g
h
)
P(ρ|\mathcal D_{train},f(ρ)~is~high)
P(ρ∣Dtrain,f(ρ) is high)中生成高质量候选。首先,我们通过将此分布
P
(
ρ
∣
D
t
r
a
i
n
,
f
(
ρ
)
i
s
h
i
g
h
)
P(ρ|\mathcal D_{train},f(ρ)~is~high)
P(ρ∣Dtrain,f(ρ) is high)转换为单词来采用基于“前向”模式生成的方法。例如,在我们的指令归纳实验(第4.1小节)中,我们采用类似Honovich et al. (2022)的方法,并使用图3(top)所示来提示LLM。在这种情况下,输出的单词建议是根据指令生成的,因此所考虑的分数函数将很高。
Reverse Mode Generation。尽管“正向”模型在大多数预训练LLM中可直接使用的,但是将
P
(
ρ
∣
D
t
r
a
i
n
,
f
(
ρ
)
i
s
h
i
g
h
)
P(ρ|\mathcal D_{train},f(ρ)~is~high)
P(ρ∣Dtrain,f(ρ) is high)转换为单词需要在不同任务上进行自定义工程。这是因为“正向”模型仅生成从左到右的文本,而我们希望该模型在演示之前预测缺失上下文。为了解决这个问题,我们还考虑使用具有填充能力的LLM进行“反向”模式生成,例如,T5,GLM和InsertGPT,以推断缺失的指令。通过填充空白部分,我们的“反向”模型直接从
P
(
ρ
∣
D
t
r
a
i
n
,
f
(
ρ
)
i
s
h
i
g
h
)
P(ρ|\mathcal D_{train},f(ρ)~is~high)
P(ρ∣Dtrain,f(ρ) is high)采样,使其比“正向”补全模型更多样化。例如,在我们的指令归纳实验中,我们使用图3(Middle)中的模板。
Customized Prompts。请注意,根据所使用的分数函数,可能存在比上面样本更合适的提示。例如,在我们的TruthfulQA实验中,我们从原始数据集的人类设计的指令开始。如图3(Bottom)所示,“反向”模型被要求提出适合缺失上下文的初始指令样本。
3.2 SCORE FUNCTIONS
为了将我们的问题作为黑盒问题进行优化,我们选择了一个评分函数,该函数可以准确测量数据集与模型生成数据之间的对齐。在我们的指令归纳实验中,我们考虑了下面描述的两个潜在评分函数。在TruthfulQA实验中,我们主要关注由 Lin et al. (2022) 提出的自动评估指标,类似于执行精度。 在每种情况下,我们都使用公式(1)评估生成指令在测试集
D
t
e
s
t
\mathcal D_{test}
Dtest的质量。
Execution accuracy。首先,我们考虑使用Honovich et al. (2022) 提出的执行精度来评估指令
ρ
ρ
ρ的质量,我们将其表示为
f
e
x
e
c
f_{exec}
fexec。在大多数情况下,执行精度简单地定义为0-1损失,即
f
(
ρ
,
Q
,
A
)
=
I
[
M
(
[
ρ
;
Q
]
)
=
A
]
f(ρ,Q,A)=\mathbb I[\mathcal M([ρ;Q])=A]
f(ρ,Q,A)=I[M([ρ;Q])=A]。在某些任务上,执行精度考虑了不变性,例如,如Honovich et al. (2022) 附录A所述,它可能是顺序不变的匹配损失。
Log probability。我们进一步考虑了较软的概率评分函数,我们认为该函数可以通过在搜索低质量候选指令时提供更细粒度的信号来改善优化。特别是,我们考虑了给的指令
ρ
ρ
ρ和问题
Q
Q
Q时,目标模型
M
\mathcal M
M生成答案
A
A
A的对数概率
l
o
g
p
(
A
∣
[
ρ
;
Q
]
)
log~p(A|[ρ;Q])
log p(A∣[ρ;Q])。
Efficient score estimation。通过计算整个训练数据集上候选指令的分数来估计最终分数,这可能需要很大的计算成本。为了降低计算成本,我们采用了一种过滤方案,其中有希望的候选将获得更多的计算资源,而低质量候选则进行较少的计算。这可以通过使用多阶段计算策略来实现(例如算法1的第2-9行)。我们首先用一小部分训练数据评估所有候选。对于分数大于一定阈值的候选,我们采样训练数据集中新的非重叠子集并评估,然后更新分数的移动平均。然后,我们重复此过程,直到剩下一组较小候选,这些候选在整个训练数据集中进行了评估。这种自适应过滤方案可通过保持高质量样本的计算资源并大大降低低质量候选的计算资源来显着提高计算效率。我们注意到,以前的工作已经使用了类似的分数估计方案。
3.3 ITERATIVE PROPOSAL DISTRIBUTIONS

尽管我们试图直接采样高质量的初始候选指令,但第3.1节中描述的方法可能无法产生良好的指令集
U
\mathcal U
U,因为它缺乏多样性,或者不包含任何适当高分数的候选。为了应对此类挑战,我们探索了迭代采样过程。
Iterative Monte Carlo Search。我与仅从初始指令集中采样不同,我们还考虑围绕当前最佳候选探索局部搜索空间。这使我们能够生成更有可能成功的新指令。我们称此变体迭代APE。在每个阶段,我们评估一组指令,并过滤得分低的候选。然后,要求LLM生成分数高且和当前指令相似的新指令。我们在图4中提供了用于重新采样的提示。
图8(Right)表明,尽管这种方法提高了候选指令集的总体质量,但具有最高评分的指令往往会出现在所有阶段。因此我们得出结论,迭代生成对第3.1节中描述的生成过程的相对简单性和有效性提供了边界改进。因此,除非另有说明,否则我们在实验中使用无迭代搜索的APE。

















 769
769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









