






 Flamingo是一种视觉语言模型,能够在少量样例指导下适应多种图像和视频任务,如视觉问答和图像描述。它结合了强大的视觉和语言预训练模型,处理交替的视觉和文本数据,展示出优秀的in-contextfew-shot学习能力,无需微调即可在多个基准测试中达到SOTA性能。
Flamingo是一种视觉语言模型,能够在少量样例指导下适应多种图像和视频任务,如视觉问答和图像描述。它结合了强大的视觉和语言预训练模型,处理交替的视觉和文本数据,展示出优秀的in-contextfew-shot学习能力,无需微调即可在多个基准测试中达到SOTA性能。
摘要
构建仅需少量带标注数据就可以快速应用到新任务的模型是多模态机器学习研究的一个挑战。我们引入Flamingo,这是一种具有该能力的视觉语言模型(VLM)。我们提出了新的网络结构:(i)桥接强大的纯视觉或语言预训练模型,(ii)处理视觉和文本数据任意交替的序列,以及(iii)无缝将图像或视频数据作为输入。由于它们的灵活性,Flamingo模型可以在包含任意文本和图像的大规模多模态网络语料中进行训练,这是他们具有in-context few-shot学习能力的关键。 我们对模型进行彻底评估,以探索和衡量它们快速应用到各种图像和视频任务上的能力。这包括开放式任务,例如视觉问答,其中使用一个问题提示该模型来进行回答;captioning 任务,用于评估模型描述场景或事件的能力;以及例如多选项选择的视觉问答任务。对于该范围中的任何任务,单个Flamingo模型只需使用特定任务的样例来提示该模型就可以实现新的few-shot学习SOTA。在众多基准测试中,Flamingo的表现要优于在数千倍的特定任务数据上进行微调的模型。
1.介绍

人工智能的一个关键方面是在给定少量指令的情况下,能够快速学习新任务的能力。尽管在计算机视觉方面已经取得了初步进展,但最广泛使用的范式仍然是首先在大量有监督数据上进行预训练,然后在感兴趣的任务上微调模型。但是,成功的微调通常需要数千个标注的数据。此外,它通常需要对每个任务的超参数进行精细调整,并且也是资源密集的。最近,在对比学习目标上训练多模态视觉语言模型,已经能够zero-shot应用到新任务,而无需进行微调。但是,由于这些模型只是在文本和图像之间提供一个相似度得分,因此它们只能解决有限的任务,例如分类,其中一个有限的结果集合被提前给出。他们重要的是缺乏语言生成的能力,这使得它们不适合更开放式的任务,例如图像描述或视觉问答。其他人则探索了以视觉为条件的语言生成,但在低数据领域中尚未表现出良好的性能。
我们介绍了Flamingo,这是一种视觉语言模型(VLM),该模型仅仅通过使用一些输入/输出样例作为提示,就在几种开放视觉和语言任务上达到了新的SOTA,例如在图1中说明的16个任务中,Flamingo在6个任务上也超过了微调的模型,并且使用了远小于相应任务所需训练数据的数量级(见图2)。为了实现这一目标,Flamingo受最近的大型语言模型(LMS)工作的启发,LM是一个很好的few-shot学习器。单个大LM使用其文本接口就能在许多任务上实现强大的性能:使用该任务的一些示例作为提示,同时给定问题输入,然后该模型连续生成该问题的预测输出。 我们表明,对于图像和视频理解任务,例如分类,图像描述或问答,也可以用同样的方法实现:可以将形式化为以视觉输入为条件的文本预测问题。与LM的不同之处在于,该模型必须能够接收包含图像和/或视频与文本交替的多模态提示。Flamingo模型具有此功能 - 它们是以视觉为条件自回归文本生成模型,能够接受一系列文本字符,并与图像和/或视频交替在一起,并产生文本作为输出。Flamingo模型利用了两个互补的预训练和参数固定的模型:一个可以“感知”视觉场景的视觉模型,以及执行基本推理形式的大型LM。Flamingo在这些模型之间添加了新的结构组件,以链接他们在预训练期间积累的知识。由于基于Perceiver的结构,每个图像/视频都可以产生少量固定数目的视觉token,因此Flamingo模型还能够接收高分辨率的图像或视频。
大型LMS具有强大性能的关键方面是,它们接受了大量文本数据进行训练。这种培训练供了通用的生成能力,可以在以任务样例为提示时使LMS表现良好。 同样,我们证明了我们训练Flamingo模型的方式对于他们的最终表现至关重要。他们在精心挑选的来自网络的大规模多模态数据的混合上训练,而无需使用任何标注数据。经过训练,可以通过简单的few-shot学习直接将Flamingo模型适应到新视觉任务,而无需进行任何特定任务的调整。
Contributions。总而言之,我们的贡献如下:(i)我们介绍了仅需少量输入/输出样例就能执行多模态任务(例如图像描述,或视觉问答)的VLM Flamingo。基于新的网络结构,Flamingo模型可以有效地接受任意交替的视觉和文本数据作为输入,并以开放式的方式生成文本。(ii)我们定量评估如何通过few-shot学习将Flamingo模型适应各种任务。我们特意保留了一系列基准测试,这些基准尚未用于验证该方法的任何设计决策或超参数。我们使用这些基准来估计模型的few-shot表现。(iii)Flamingo在16种多模态语言和图像/视频理解任务上通过few-shot学习的方式达到了新的SOTA。在这16个任务中的6个中,Flamingo通过使用32个样例就胜过了微调的最新SOTA,而这要比用于微调的数据少了1000倍。有了更大的标注预算,Flamingo也可以有效地进行微调,以在五个其他具有挑战性的基准下达到新的SOTA:VQAv2,VATEX,VizWiz,MSRVTTQA和HatefulMemes。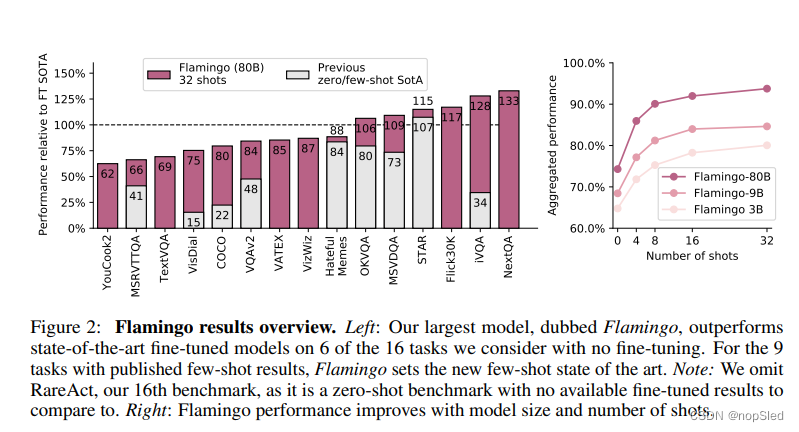
2.方法
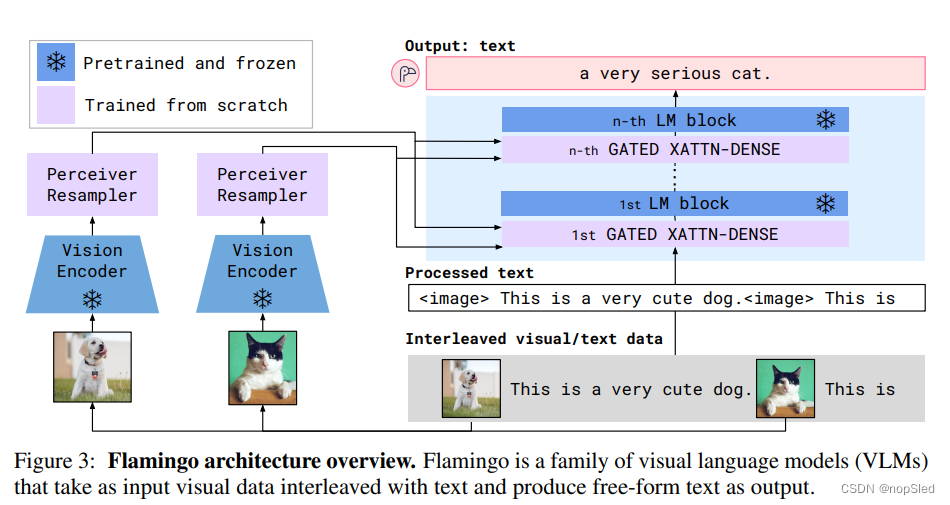
本节介绍了Flamingo:这是一种视觉语言模型,该模型交替接受文本与图像/视频作为输入,然后输出纯文本。选择图3中所示的关键结构组件是为了利用预训练的视觉和语言模型,并有效地桥接它们。首先,Perceiver Resampler(第2.1节)从视觉编码器(从图像或视频中获得)接收时空特征,并输出固定数量的视觉token。其次,这些视觉token作为具有重新初始化的交叉注意力层的参数固定LM的条件(第2.2节),这注意力层是在预训练的LM层之间交替的。这些层为LM提供了一种表达方式,可以将视觉信息整合到下一个单词预测的任务中。Flamingo以交替的图像和视频
x
x
x为条件,建模文本
y
y
y的似然:
p
(
y
∣
x
)
=
∏
l
=
1
L
p
(
y
l
∣
y
<
l
,
x
≤
l
)
,
(1)
p(y|x)=\prod^L_{l=1}p(y_l|y_{\lt l},x_{\le l}),\tag{1}
p(y∣x)=l=1∏Lp(yl∣y<l,x≤l),(1)
其中
y
l
y_l
yl是输入文本
y
y
y的第
l
l
l个文本token,
y
<
l
y_{\lt l}
y<l是历史文本token的集合,
x
≤
l
x_{\le l}
x≤l是处于
y
l
y_l
yl前的图像或视频token集合,并且
p
p
p被Flamingo模型参数化。处理交替的文本和视觉序列的能力(第2.3节)使得使用Flamingo模型进行in-context few-shot学习是很自然的,类似于使用few-shot文本提示的GPT-3。如第2.4节所述,该模型在各种混合数据集中进行了训练。
2.1 Visual processing and the Perceiver Resampler
Vision Encoder: from pixels to features。我们的视觉编码器是一个预训练且参数被固定的NormalizerFree ResNet (NFNet),其中我们使用F6模型。我们使用来自Radford et al.的两项对比损失,在我们收集的图像文本对数据集上预训练视觉编码器。我们使用最后一个阶段的输出,这是一个2D空间网格,其特征被扁平化为1D序列。对于视频输入,以1 FPS采样帧并独立编码,并添加可学习的时间嵌入,以获得3D时空网格特征。然后将特征扁平化到1D序列,然后再送入Perceiver Resampler。附录B.1.3和附录B.3.2分别提供了有关对比模型训练和性能的更多详细信息。
Perceiver Resampler: from varying-size large feature maps to few visual tokens。该模块将视觉编码器连接到图3所示的参数固定的语言模型。它以来自视觉编码器的可变数目的图像或视频特征作为输入,并生成固定数量的视觉输出(64),从而降低了视觉文本交叉注意力的计算复杂度。与Perceiver和DETR类似,我们学习一组提前定义的具有固定数目的query嵌入,这些query被带到Transformer并和视觉特征计算交叉注意力。我们在消融研究(第3.3节)中表明,使用这种视觉的重采样器模块的表现优于普通Transformer和MLP。我们在附录A.1.1中提供了一个阐述,更多的架构细节和伪代码。
2.2 Conditioning frozen language models on visual representations
文本生成是由Transformer解码器执行的,并以由Perceiver Resampler生成的视觉表示为条件。我们交替堆叠了参数固定的纯文本LM块和从头开始训练的交叉注意力块。
Interleaving new GATED XATTN-DENSE layers within a frozen pretrained LM。
Varying model sizes。我们冻结了预训练LM块,并在原始层之间插入门控交叉注意力块(图4),然后从头开始训练。为了确保在初始化时,条件模型生成与原始语言模型相同的结果,我们使用tanh门控机制。这将新添加层的输出乘以
t
a
n
h
(
α
)
tanh(\alpha)
tanh(α),然后将其添加到残差连接的输入表示中,其中
α
\alpha
α是每一层中可学习的标量,并由0来初始化。因此在初始化后,模型的输出和预训练LM相同,这提高了训练稳定性以及最终性能。在我们的消融研究中(第3.3节),我们将所提出的GATED XATTN-DENSE层与最近的替代方案进行了比较,并探讨了这些附加层被插入以在效率和性能之间进行权衡的效果。有关更多详细信息,请参见附录A.1.2。
Varying model sizes。我们在三种模型大小上进行实验,即1.4B,7B和70B参数的Chinchilla模型。分别称他们为Flamingo-3B,Flamingo-9B和Flamingo-80B。为了简化描述,我们将本篇文章的模型统称为Flamingo。 有关更多详细信息,请参见附录B.1.1。
2.3 Multi-visual input support: per-image/video attention masking
在等式(1)中引入的图像因果建模是通过屏蔽完整的文本对图像的交叉注意力矩阵获得的,这限制了该模型在每个文本token上看到的视觉token。在给定的文本token上,该模型使用交替序列中仅出现在该文本前的图像的视觉token进行注意力计算,而不是所有先前的图像(在附录A.1.3中进行了形式化和说明)。尽管该模型每次仅计算单个图像的交叉注意力,但对所有先前图像的依赖仍然是通过LM中的自注意力。这种单图像交叉注意力方案的优势是,无论在训练过程中使用多少张图片,该模型都可以无缝地泛化到任意数量的视觉输入。特别是,当我们在交替数据集中训练时,我们只使用多达5张图像,但是我们的模型能够在评估期间使用的图像/视频和相应文本扩展到32对。我们在第3.3节中表明,该方案比允许模型直接与先前所有图像进行计算更高效。
2.4 Training on a mixture of vision and language datasets
我们在下面三种数据集的混合集合中训练Flamingo模型,这些数据都是从网络上爬取来的:一个交替的图像和文本数据集,该数据集源自网页,图像文本对以及视频文本对。
M3W: Interleaved image and text dataset。Flamingo模型的few-shot能力依赖于在交替的文本和图像数据上的训练。为此,我们收集了MultiModal MassiveWeb (M3W) 数据集。我们从大约4300万个网页的HTML中提取文本和图像,根据Document Object Model (DOM) 中文本和图像元素的相对位置来确定图像相对于文本的位置。然后,通过在页面上图像的位置向纯文本中插入
<
i
m
a
g
e
>
<image>
<image>标签来构造一个样例,并在任何图像前和文档末尾插入一个特殊
<
E
O
C
>
<EOC>
<EOC>字符,并将这些字符添加到词表进行学习。从每个文档中,我们采样了一个长度为
L
=
256
L=256
L=256的随机子序列,并最多可以在采样序列中包含
N
=
5
N=5
N=5张图像。丢弃剩余图像以节省计算。附录A.3提供了更多详细信息。
Pairs of image/video and text。对于我们的图像和文本对,我们首先利用ALIGN数据集,该数据集包含18亿的图像文本对。为了补充该数据集,我们收集了自己的图像和文本对数据集,该数据集质量更好,具有更长的描述:LTIP(长文本和图像对),由3.12亿张图像和文本对组成。我们还收集了一个类似的数据集,但是带有视频而不是静态图像:VTP(视频和文本对)由2700万个短视频(平均约22秒)与句子说明。我们采用了和M3W数据集相同的数据拼接方法(有关详细信息,请参见附录A.3.3)。
Multi-objective training and optimisation strategy。给定视觉输入,我们通过最小化期望数据集中文本的负对数似然的加权总和来训练我们的模型:
∑
m
=
1
M
λ
m
⋅
E
(
x
,
y
)
∼
D
m
[
−
∑
l
=
1
L
l
o
g
p
(
y
l
∣
y
<
l
,
x
≤
l
)
]
,
(2)
\sum^M_{m=1}\lambda_m\cdot \mathbb E_{(x,y)\sim\mathcal D_m}\bigg[-\sum^L_{l=1}log~p(y_l|y_{\lt l},x_{\le l})\bigg],\tag{2}
m=1∑Mλm⋅E(x,y)∼Dm[−l=1∑Llog p(yl∣y<l,x≤l)],(2)
其中
D
m
\mathcal D_m
Dm和
λ
m
\lambda_m
λm分别是第
m
m
m个数据集及其权重。调整每个数据集权重
λ
m
\lambda_m
λm是性能的关键。我们在所有数据集上进行梯度积累,我们发现它们的表现优于“round-robin”方法。我们在附录B.1.2中提供进一步的训练细节和消融对比。
2.5 Task adaptation with few-shot in-context learning
一旦训练了Flamingo,通过以多模态交替提示作为条件输入,我们就可以用它来解决视觉任务。通过以 ( i m a g e , t e x t ) (image,text) (image,text)或 ( v i d e o , t e x t ) (video,text) (video,text)的形式交替输入样例对,然后进行视觉问题输入,来评估模型使用ICL快速适应新任务的能力(附录A.2中的详细信息)。我们使用集束搜索进行解码进行开放式评估,并使用模型的对数似然进行评分来评估每个可能的答案。我们使用任务中的两个纯文本示例来提示模型以探索zero-shot的泛化能力。评估的超参数和其他详细信息在附录B.1.5中给出。

















 8033
8033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









