






 MIMIC-IT数据集引入了280万个多模态指令-响应对,用于改进视觉语言模型的多模态感知、推理和上下文学习能力。Otter模型在多模态基准测试中表现出色,同时通过多语言指令响应对支持跨语言交互。
MIMIC-IT数据集引入了280万个多模态指令-响应对,用于改进视觉语言模型的多模态感知、推理和上下文学习能力。Otter模型在多模态基准测试中表现出色,同时通过多语言指令响应对支持跨语言交互。
摘要
高质量的指令和响应对于大语言模型在自然语言交互任务上的zero-shot表现至关重要。对于涉及复杂视觉场景的视觉语言交互任务,使用大量多样化和创造性的指令-响应对来微调视觉语言模型(VLM)是非常重要的。然而,在数量,多样性和创造性方面,目前的视觉指令-响应对的可用性仍然有限,这对交互式VLM的泛化能力提出了挑战。在这里,我们提出了MultI-Modal In-Context Instruction Tuning (MIMIC-IT),该数据集由280万个多模态指令 - 响应对组成,其中220万个指令来自图像和视频。每一个数据对均具有多模态的上下文信息,形成旨在在感知,推理和计划中增强VLM的对话上下文。使用自动标注pipline将人类专业知识与GPT能力相结合,来构建指令-响应对收集过程,这个过程被称为Syphus。使用MIMIC-IT数据集,我们训练一个名为Otter的大型VLM。基于对视觉基准进行的广泛评估,我们观察到,Otter在多模态感知,推理和上下文学习方面表现出卓越的水平。人类评估表明,它与用户的意图有效地保持一致。我们发布了MIMIC-IT数据集,指令-响应收集pipeline,基准和Otter模型。
1.介绍
人工智能的最新进步集中在对话助手上,该助手具有理解用户意图并执行操作的能力。除了大语言模型(LLM)强大的泛化能力外,这些对话助手的显着成就还可以归因于指令微调的实践。它涉及通过多样化和高质量指令在一系列任务上微调LLM。通过组合指令微调,LLM可以提高对用户意图的理解,从而使他们能够在以前未知的任务中展现出提升的zero-shot能力。通过指令微调增加zero-shot性能的一个潜在原因是,它可以内化上下文,这在用户交互中是必须的,尤其是当用户输入跳过了常识上下文时。
在语言任务中表现出色的对话助手取得了卓越的成功。但是,一个最优的对话助手应该能够解决涉及多种模态的任务。这需要使用多样化和高质量的多模态指令遵循数据集。LLaVA-Instruct-150K数据集(也称为LLaVA)是开创性的视觉语言指令遵循数据集。它是使用基于图像标题和目标边界框的COCO图像,从GPT-4获得指令和响应来构造的。
LLaVA-Instruct-150K虽然鼓舞人心,但表现出三个局限性。(1)有限的视觉多样性:由于其仅依赖于COCO图像,数据集的视觉多样性受到限制。(2)单个图像作为视觉数据:它利用单个图像作为视觉数据,而多模态对话助手应具有处理多个图像甚至广泛视频的能力。例如,当用户提供一系列图像(或一系列视频)并使用时“Help me think of an album title for these images.”时,它应该有效地提供答案。(3)仅使用语言的上下文信息:它仅取决于语言中的上下文信息,而多模态的对话助手应集成多模态的上下文信息,以更好地理解用户指令。例如,如果人类用户提供了所需属性的具体图像示例,则助手应该更准确地将其对图像的描述与音调,风格或其他方面对齐。
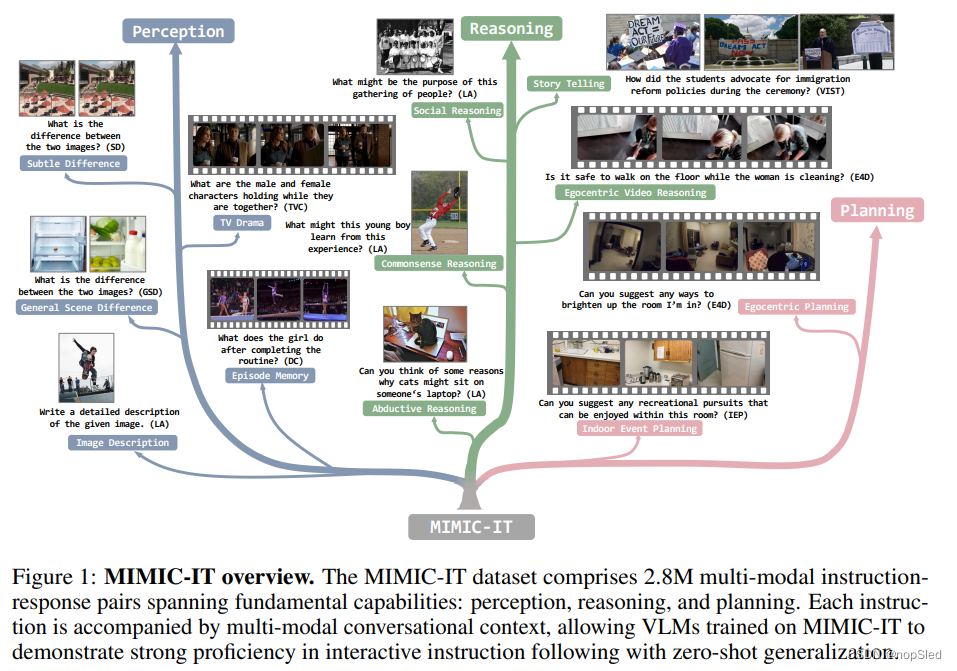
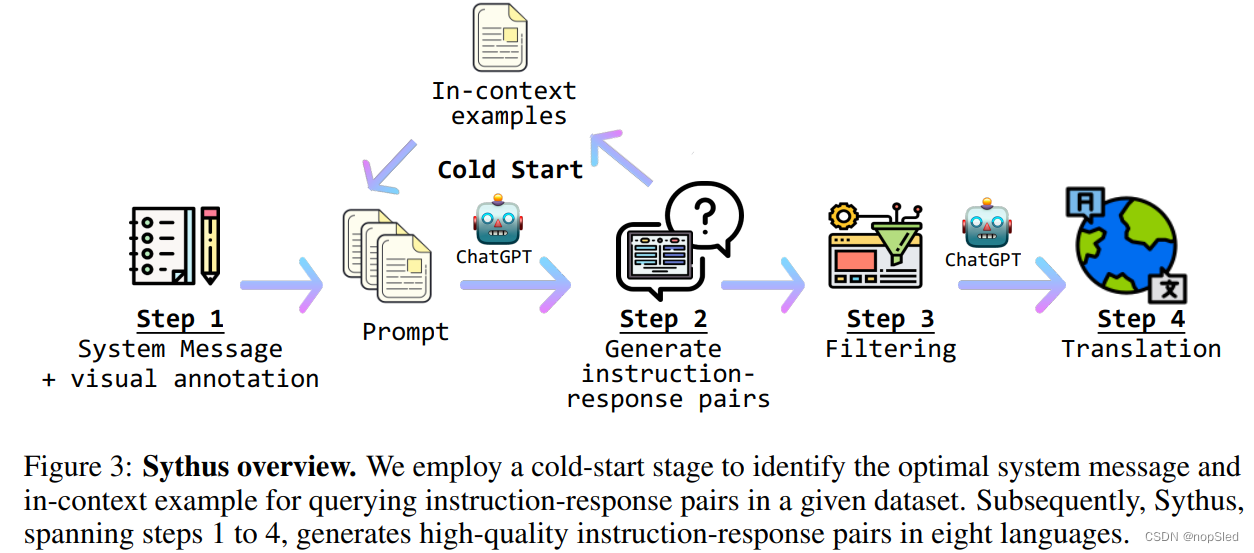
为了解决这些局限性,我们引入了MultI-Modal In-Context Instruction Tuning (MIMIC-IT)。 MIMIC-IT的特点是:(1)多样化的视觉场景,组合了来自通用场景,第一视角场景和室内RGB-D数据等多种数据集的图片和视频。(2)多个图像(或视频)作为视觉数据,通过使用任意数量的图像或视频来支持指令响应对。(3)多模态的上下文信息,通过包含多个指令响应对,以及多个图像或视频,来形式化多模态格式的上下文信息(如图2所示的数据格式申明)。 为了有效地生成指令响应对,我们介绍了Sythus,这是一种自动化pipeline,这是一种受self-instruct方法启发的指令响应对标注方法。Sythus采用系统消息,视觉标注和上下文示例来指导语言模型(GPT-4或ChatGPT),以基于视觉上下文(包括时间戳,字幕和目标信息)生成指令响应对,旨在针对视觉语言模型的三个基本功能:感知,推理和计划(请参阅图1)。此外,指令和响应将从英语翻译成七种语言,以支持多语言使用。
在MIMIC-IT上,我们基于OpenFlamingo训练了一个多模态的Otter。我们在两个方面评估了Otter的多模态能力:(1)在MMAGIBenchmark上进行的ChatGPT评估,与其他最近的视觉语言模型(VLMS)和Otter的感知和推理能力进行了比较,其中Otter倍证明具有最强的性能。(2)多模态领域的人类评估,Otter的表现优于其他VLM,获得了最高的ELO评级。此外,我们使用COCO字幕数据集评估了Otter的few-shot上下文学习能力,结果显示了Otter在few-shot设置中的优越性能。总而言之,我们的贡献包括:
- MultI-Modal In-Context Instruction Tuning (MIMIC-IT) 数据集,该数据集包含约280万个多模态的上下文指令-响应对,并在各种现实生活场景中具有220万个独特的指令。
- Syphus是一种使用LLM构建的自动pipeline,以基于视觉上下文生成高质量和多语言的指令-响应对。
- Otter是一个多模态模型,展示了强大的多模态感知和推理能力,能有效地遵循人类意图,同时在上下文学习中表现出强大性能。
2.相关工作
2.1 Multi-modal Instruction Tuning Dataset
多模态模型中指令微调的概念最初是在称为Multi-Instruct的工作中引入的,该工作涵盖了涉及视觉理解和多模态推理的广泛的多模态任务,例如视觉问答。同样,Mini-GPT4通过将Conceptual Caption,SBU和LAION与手写指令模板合并来创建其基于指令的数据集。最近,LLaVA-Instruct-150K通过利用self-instruct和GPT-4以及COCO图像上的手写种子指令来提高指令微调数据集的质量。尽管这些先前的工作主要针对通用场景图像进行多模态指令微调,但我们的方法将数据源分类为室内场景,室外场景,对话和以第一人称视频的类别。此外,受MMC4数据集的图像文本交替结构的启发,我们的方法通过将多模态的上下文格式合并到指令微调中进一步优化了数据集。
2.2 Multi-modal Foundation Models
随着ChatGPT,GPT-4和其他LLM的最新成功,最近的研究开始探索将其他模态的信息纳入预训练的语言模型。这些研究将LLM的能力扩展到了更多的任务和模态,可以分为两类:(i)Multi-model Aggregation。这些方法将LLM作为调度程序,并通过其连接不同的专家模型,以允许不同的任务。语言是在其各自的任务中调用专家视觉语言模型的接口。但是,这种方法受到限制,即每个模型不能单独在新任务训练。(ii) End-to-End Trainable Models。 这些方法将不同模态的模型连接到集成的端到端可训练模型,也称为多模态基础模型。其中,我们基于大型图像文本的预训练模型OpenFlamingo,Otter是第一个进一步展示多模态上下文指令微调能力的开源模型。
3. Multi-modal In-context Instruction Tuning Dataset
我们旨在构建MIMIC-IT数据集,以支持更多的VLM获取理解现实世界的能力。在本节中,我们提供了MIMIC-IT 数据集的概述,3.1节中介绍了数据格式,并且3.2节介绍了我们的自动指令生成pipline,Sythus。
3.1 MIMIC-IT Data Format

MIMIC-IT数据集中的每个实例
i
i
i都包含一个指令-响应对以及
N
N
N个图像集。我们将其视为具有元组
(
I
q
,
R
q
,
X
q
)
(I_q,R_q,X_q)
(Iq,Rq,Xq)的问答示例,其中
{
x
j
=
1
N
}
∈
X
q
\{x^N_{j=1}\}∈X_q
{xj=1N}∈Xq。在元组中,
I
q
I_q
Iq表示数据集中的第
q
q
q个指令,
R
q
R_q
Rq表示响应,
X
q
X_q
Xq指的是图像或视频。我们的主要目标是开发一个由可训练参数
θ
θ
θ参数化的视觉语言模型
p
θ
(
R
q
∣
(
I
q
,
X
q
)
)
p_θ(R_q|(I_q,X_q))
pθ(Rq∣(Iq,Xq)),该模型为每个问题
(
I
q
,
X
q
)
(I_q,X_q)
(Iq,Xq)生成响应
R
i
R_i
Ri。使用上面的示例表示视觉语言模型的标准指令微调过程。此外,我们可以将一组上下文样例定义为
(
I
k
,
R
k
,
X
k
)
k
=
1
M
(I_k,R_k,X_k)^M_{k=1}
(Ik,Rk,Xk)k=1M,其中
M
M
M是集合的数量。
然后,我们定义一个上下文函数
C
ψ
:
(
I
q
,
X
q
)
↦
{
(
I
k
,
X
k
)
}
k
=
1
M
C_ψ:(I_q,X_q)\mapsto \{(I_k,X_k)\}^M_{k=1}
Cψ:(Iq,Xq)↦{(Ik,Xk)}k=1M,以表示带有当前问题示例的在上下文示例。总而言之,MIMIC-IT数据集中的所有数据将以以下格式表示:
d
q
=
(
I
q
,
R
q
,
X
q
,
C
ψ
(
I
q
,
X
q
)
)
,
d
q
∼
D
M
I
M
I
C
−
I
T
(1)
d_q=(I_q,R_q,X_q,C_{\psi}(I_q,X_q)),d_q\sim D_{MIMIC-IT}\tag{1}
dq=(Iq,Rq,Xq,Cψ(Iq,Xq)),dq∼DMIMIC−IT(1)
现在,可以将包含上下文示例的视觉语言模型表示为
p
θ
(
R
q
∣
(
I
q
,
X
q
,
C
ψ
(
I
q
,
X
q
)
)
)
p_θ(R_q |(I_q,X_q,C_ψ(I_q,X_q)))
pθ(Rq∣(Iq,Xq,Cψ(Iq,Xq)))。
C
ψ
C_ψ
Cψ是任务依赖的,我们采用不同的方法来组织使用当前查询示例的上下文示例。详细信息将在第3.3节中介绍,并且说明样例将在图2中展示。
3.2 Sythus: Automatic Instruction-Response Generation Pipeline

















 1232
1232

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









