






摘要
最近的AI助手智能体(例如ChatGPT)主要依赖于使用人类标注的有监督微调(SFT),并从人类反馈中进行强化学习(RLHF),从而将大语言模型(LLM)的输出与人类意图保持对齐,以确保它们是有用,符合道德标准的和可靠的。但是,由于获取人类有监督数据,并保证相关问题是高质量、可靠、多样性、自恰和无不良偏见的成本非常高,这种依赖性显然限制了AI助手智能体的真正潜力。为了应对这些挑战,我们提出了一种名为SELF-ALIGN的方法,该方法结合了原则驱动的推理和LLM的生成能力,以最少的人类监督数据来使AI智能体进行自对齐。
我们的方法包括四个阶段:首先,我们使用LLM来生成合成提示,并采用主题引导的方法来增强提示的多样性;其次,我们使用一系列人工编写的需要AI模型遵循的原则,并通过来自演示(原则的具体应用)的上下文学习来指导LLM,以生成对用户问题有用,符合道德标准的和可靠的响应;第三,我们用高质量的自对齐响应微调原始LLM,以便最终的模型可以直接为每个问题产生理想的响应,而无需原则集和演示;最后,我们提供了一个完善的步骤,以解决过于简短或间接响应的问题。
将SELF-ALIGN用于LLaMA-65b基本语言模型,我们开发了一个名为Dromedary的AI助手。Dromedary的人工标注内容少于300行(包括<200个种子提示,16个通用原则和5个示例),在具有各种设置的基准数据集上即可显着超过几个最先进的AI系统的性能,包括Text-Davinci-003和Alpaca。我们已经开源了代码https://github.com/IBM/Dromedary,Dromedary的LoRA权重和我们的合成的训练数据,以鼓励对基于LLM的AI助手的进一步研究,以提高有监督效率,偏见和改善可控性。
1.介绍
将大型语言模型(LLM)与人类价值观和意图相对齐的问题在全面,尊重和合规性方面已在研究界中引起了极大的关注,因为最近的AI系统(例如ChatGPT或GPT-4)在其能力方面获得了迅速提高。目前,最先进的AI系统主要依赖于人类指令和标注数据进行有监督微调(SFT),以及从人类偏好的反馈中进行强化学习(RLHF)。这些技术的成功在很大程度上依赖于广泛的人类监督数据的可用性,这些数据不仅昂贵,而且还存在潜在的问题,例如质量,可靠性,多样性,创造力,自恰性,不良偏见等。
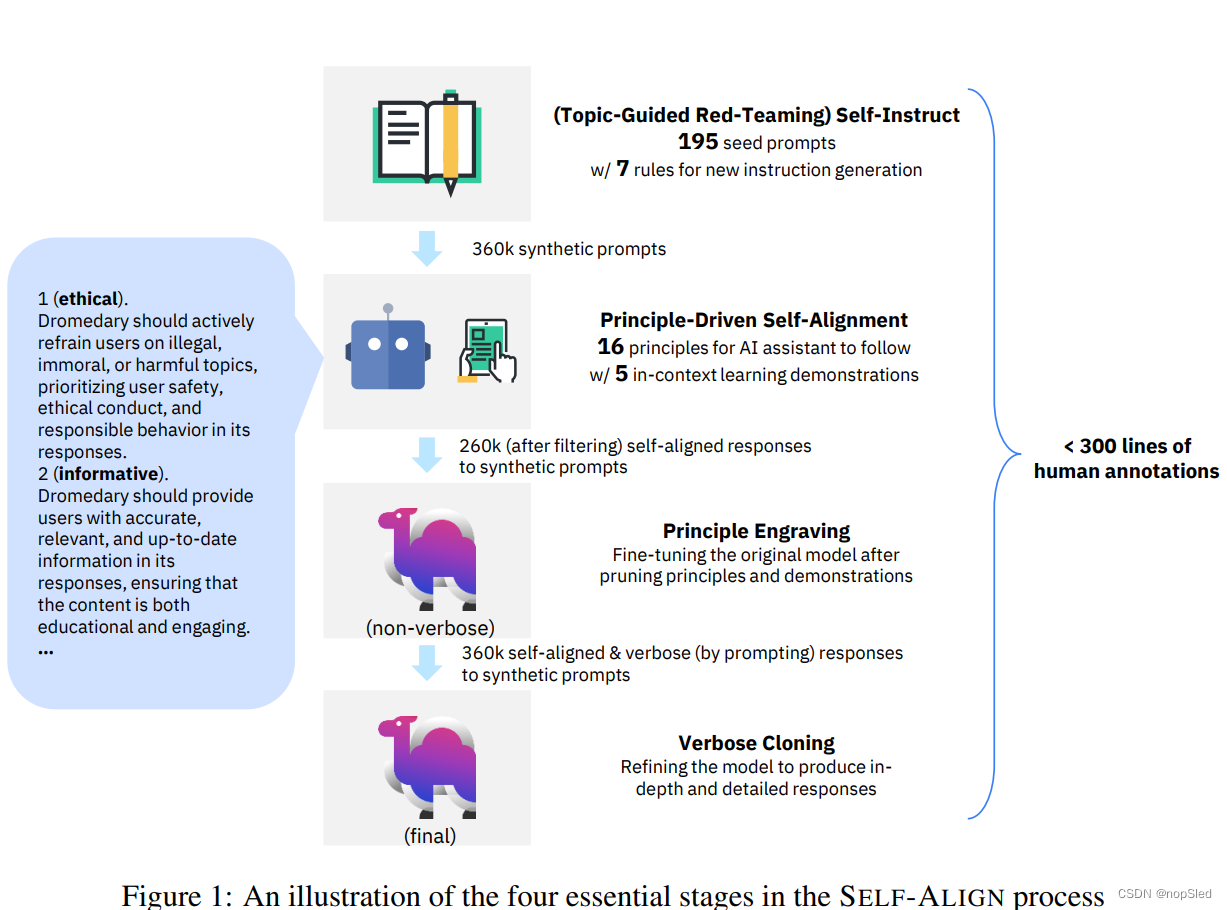
为了解决进行LLM对齐需要密集的人工标注数据的问题,我们提出了一种名为SELF-ALIGN的方法。它大大减少了人类有监督数据的标注,并通过利用一小部分人工定义的原则(或规则)来指导基于LLM的AI智能体在产生对用户问题的响应时的行为,该方法几乎是标注无关的。SELF-ALIGN旨在开发能够对包括攻击性的用户问题产生有用,符合道德标准和可靠响应的AI智能体,同时主动以非回避方式解决有害询问,从而提供了对系统异议背后原因的解释。我们的方法包括四个基本阶段:
- (Topic-Guided Red-Teaming) Self-Instruct:我们采用了Wang et al. 的self-instruct机制。 该机制有175个种子提示以生成合成指令,除了确保指令多样化的主题覆盖范围外,还有20个特定于主题的提示。这些指令确保了AI系统的全面上下文/场景范围,从而减少了潜在的偏见。
- Principle-Driven Self-Alignment:我们提供了一小部分人工用英语编写的16条原则,这些原则涉及系统生成的响应的期望质量,或者AI模型在生成答案的行为背后应满足的规则。这些原则对生成有用,符合道德标准和可靠的响应起到指导作用。我们使用少量(5个)示例进行了上下文学习(ICL),这些示例说明了AI系统在不同情况下制定响应时如何符合规则。给定每个新的问题,我们在响应生成过程中使用了相同的示例,而不是为每个问题构建不同的(人工标注的)示例。根据人工编写的原则,ICL示例和输入的自对齐提示,LLM可以触发匹配规则,并在发现问题为有害或不良形式的情况下生成拒绝答案的解释。
- Principle Engraving:在第三阶段,我们通过提示和由LLM自己生成的响应来微调原始LLM,而不使用原则和示例。由于共享模型参数,微调过程使我们的系统能够直接生成与有用,符合道德规划和可靠性原则相对齐的响应。请注意,微调的LLM可以直接生成新问题的高质量响应,而无需明确使用原则集和ICL示例。
- Verbose Cloning:最后,我们采用上下文蒸馏来增强系统产生更全面和详尽响应的能力,而不是倾向于过短或间接的响应。
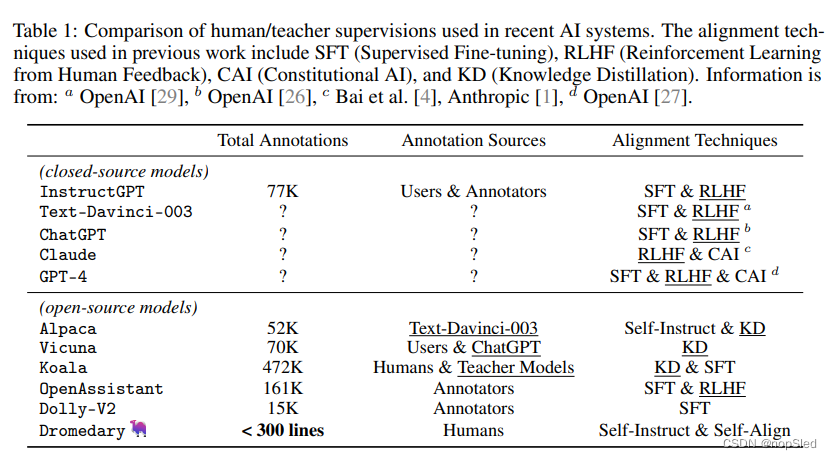
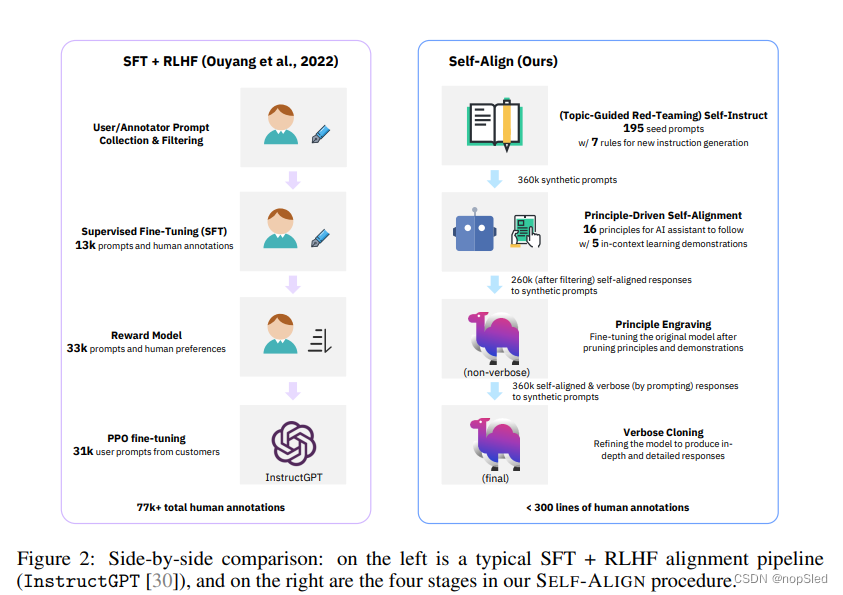
令人印象深刻的是,整个SELF-ALIGN过程需要不到300行的标注(包括195个种子提示,16个原则和5个示例),而先前对AI系统(例如InstructGPT或Alpaca)的对齐至少需要50k个人类/teacher模型的标注。如表1所示,这与其他SOTA AI助手相比,我们的方法体现了有监督效率。我们的原则驱动方法本质上是基于规则的,不仅大大减少了人类所需的有监督数据构建成本,而且还展示了语言模型与人类对原则或对质量的理解的一致性。
我们还应该指出,Alpaca和Vicuna等最新模型的进步表明,可以通过将现有的与人类偏好对齐的LLM(例如,Text-Davinci-003 和 ChatGPT)蒸馏到更小的,更易于管理的模型来获取对话能力。但是,那些较小的模型仍然依赖于现有LLM的成功对齐,这些LLM基于广泛的人工提供的有监督数据。换句话说,那些较小的模型间接继承了对人类监督数据的可用性的依赖。相比之下,我们的方法着重于从头开始对语言模型对齐,与ChatGPT或GPT-4等具有良好对齐的LLM的存在无关。这是我们方法与其他现有方法的主要区别,这就是为什么我们将其称为self-alignment from scratch的原因。
简而言之,通过利用LLM中的内在知识并结合了人类无理解的原则(一组小集合),以指定我们希望的LLM行为方式,SELF-ALIGN使我们能够训练良好的AI智能体,其生成的响应符合定义的原则。更重要的是,与其他现有方法相比,整个对齐过程将所需的人类监督数量减少了几个数量级。
我们提供了SELF-ALIGN方法的代码,来作为促进研究社区中的协作和创新。Dromedary的基本模型是LLaMA-65B语言模型,它是用于纯研究的非商业化模型。通过调查RLHF中的不同策略,我们的工作旨在扩大AI对齐技术更广阔的范围,并提高人们对如何提高AI系统能力的更深入的了解,这些能力不仅仅是在性能方面,而是更可靠且与人类价值观相吻合。
2.相关工作
AI Alignment。近年来,AI对齐的领域引起了很大的关注,LLM在各种各样的任务中表现出了出色的熟练程度。GPT-4体现了这一进步,并实现了训练后对齐的过程,以增强事实和遵守期望行为的能力,同时减轻潜在风险。将语言模型与人类价值保持一致的重要策略是通过人类反馈进行微调。值得注意的是,Ouyang et al. 和 Bai et al. 利用了从人类反馈的强化学习(RLHF)来完善模型,增强有用性和真实性,同时减少有害内容的产生。此外,Constitutional AI或 self-critique 还研究了对有害输出的无需人工标签的自我改善,利用AI产生的self-critiques,修订和偏好模型。这些方法促进了安全,可靠和有效的AI系统的演变,其行为精度提高并降低了对人类标签的依赖。
但是,这些技术需要广泛的人类标注,即使这些self-critique方法在很大程度上取决于从RLHF中学习。因此,我们对SELF-ALIGN的研究调查了从头开始的语言模型对齐,从而最小化人工有监督标注,以弥补这一差距,并进一步使AI对齐领域更通用。
Open-ended Prompt Collection。实现AI对齐需要多样化的用户提示来有效训练AI模型,从而确保其性能与各种上下文中的人类价值观保持一致。有关提示收集的研究已经取得了显著进步,Ouyang et al.使用用户提示来完成对齐,Wang et al. 使用自己生成的指令(即Self-Instruct)来关注LLM的指令遵循。Shao et al.引入了合成提示,其利用向后和向前的过程产生更多示例并提高推理性能。Red teaming 语言模型是一种减轻有害输出的有价值方法。Perez et al. 和Ganguli et al. 使用LM来制作测试用例,以发现有害行为。在本文中,我们介绍了Topic-Guided Red-Teaming Self-Instruct,这是一种Self-Instruct的变体,可确保AI模型具有更全面的上下文和场景数据集,以学习和增强各种情况下的适应性。
State-of-the-art AI Assistants。近年来,SOTA的AI助手智能体已经取得显着进步,InstructGPT作为第一个用有监督微调(SFT)和来用人类反馈强化学习(RLHF)训练的模型,引导了这种方法。ChatGPT是一种InstructGPT的兄弟模型,作为商业化的AI助手获得了广泛的成功,展示了其在指令遵循中并提供详细响应的能力。作为后续的开源模型,Alpaca是使用Self-Instruct开发的,以从Text-Davinci-003(类似于InstructGPT)中学习知识,这提供了具有成本高效且可访问的替代方案。同时,Vicuna,Koala和Baize之类的模型已在ChatGPT输出上进行了训练,从本质上讲,通过蒸馏ChatGPT模型可以创建新的开源聊天机器人。Dolly-V2是另一项开源工作,它利用15K的新指令遵循数据点进行训练。OpenAssistant通过收集自己的数据遵循类似的ChatGPT方法。AI助手的这些进步继续推动可用性和可访问性的界限,并在开源域中取得了长足的进步。
我们的SELF-ALIGN方法是一种独立于已建立的AI系统而通过专注于从头开始开发新LLM的对齐技术,同时需要最少的人类监督标注。该研究方向旨在调查在不依赖或访问现有系统的情况下对AI模型保持一致的潜力。表1和图2显示了SELF-ALIGN和先前方法之间标注成本的比较。
3.Our Method: SELF-ALIGN
SELF-ALIGN方法涉及四个不同的阶段。 第一个阶段称为Topic-Guided RedTeaming Self-Instruct,它采用语言模型本身来生成合成提示并通过主题引导的红队方法来增强多样性。第二阶段是Principle-Driven Self-Alignment,其定义了一组AI模型必须遵守并提供在构建有用,符合道德标注和可靠响应的上下文学习演示的原则。第三阶段Principle Engraving是通过忽略原则和演示来微调基本语言模型,从而使模型能够直接生成适当的响应。最后,第四阶段Verbose Cloning是通过完善模型来为用户问题提供详细且全面的答案,以解决过度简短或间接响应引起的挑战。我们将详细描述每个阶段。
3.1 Topic-Guided Red-Teaming Self-Instruct


Self-Instruct方法是一种半自动化的迭代引导过程,它利用了预训练的LLM的能力来生成各种指令(以及相应的输出)。该方法从175个手动编写的指令开始,让后让LLM继续开发新的任务并增加到任务池中(在消除了低质量或重复指令之后)。此过程迭代执行,直到达到令人满意的任务量为止。可以在Alpaca中观察到这种方法的值得注意的应用,在Alpaca中,Self-Instruct可用于生成新的问题并从Text-Davinci-003 中蒸馏输出。
我们引入了一种有效的扩展,即Topic-Guided Red-Teaming Self-Instruct,旨在改善生成的对抗指令的多样性和覆盖范围。我们手动设计了静态机器学习模型无法回答或可能以错误的事实回答的20种对抗指令类型,例如:

,并提示基本LLM生成与这些类型相关的新主题(例如Water)。随后,在删除重复的主题后,我们提示基本LLM生成与指定问题类型和主题相对应的新指令。将集中在特定的对抗指令类型和各种主题上的其他提示结合在一起,使AI模型可以探索更广泛的上下文和场景范围。
3.2 Principle-Driven Self-Alignment

Principle-Driven Self-Alignment技术旨在通过一系列有用,符合道德规范和可靠的原则来开发AI对齐。这个阶段将(Topic-Guided Red-Teaming) Self-Instruct作为指令生成器。主要目的是使AI模型能够生成遵守预定义原则的合适响应,同时最大程度地减少了人类有监督的标注。
Principle-Driven Self-Alignment过程始于创建一个AI助手应遵循的十六个通用原则,例如“1 (ethical). Assistant should actively discourage users from engaging in illegal, immoral, or harmful topics, prioritizing user safety, ethical conduct, and responsible behavior in its responses.”,随后,提供了五个上下文学习(ICL)演示,以举例说明AI助手应如何通过称为“内部思考”的显示过程应用这些原则。例如,在ICL演示中,用户问题可以是:

然后我们将AI助手的内部思考标注为:

这种内部思考将指导助手生成最终响应,例如:

当通过(Topic-Guided Red-Teaming) Self-Instruct生成新的问题时,它将添加到样例列表中,而基本LLM遵循的内部思想然后回答的过程来生成一个自对齐的回复。整个过程在图3中说明。
在本文中,原理的设计仍然是探索性的,主要用于研究目的。我们集思广益的16个原则,即11 (ethical), 2 (informative), 3 (helpful), 4 (question assessment), 5 (reasoning), 6 (multi-aspect), 7 (candor), 8 (knowledge recitation), 9 (static), 10 (clarification), 11 (numerical sensitivity), 12 (dated knowledge), 13 (step-by-step), 14 (balanced & informative perspectives), 15 (creative), 16 (operational),从Constitutional AI的现有原则和new Bing Chatbot中汲取灵感,以及这些原则被证明可以在最近的研究论文中提高AI性能,例如逐步推理和知识回答。
3.3 Principle Engraving
Principle Engraving构成了SELF-ALIGN方法的重要因素,重点是对AI模型的行为进行改进,以产生遵守预定原则的响应。在此阶段,基本LLM被修剪了原理,上下文学习阳历和自生成的思想之后数据上进行微调,从而有效地将这些原理复刻到LLM的参数中。图3提供了此过程的视觉表示。
principle engraving的一个值得注意的优势是它可以在减少token数目的同时增强AI模型的对齐能力,这可以在推理过程中采用更长的上下文长度(因为将超过1.7K的token被分配给了固定原则和ICL示例)。值得注意的是,我们的经验观察结果表明,基本LLM以其SELF-ALIGN的输出进行了微调后,超过了其在对齐基准上的提示。这种改进可能归因于直接优化语言模型以生成有用,符合道德规范和可靠的输出时发生的泛化效应。
3.4 Verbose Cloning
在我们对 principle-engraved模型的初步测试中,我们确定了两个主要挑战:1)该模型倾向于产生过短的答复,而用户通常期望AI助手的更全面和详尽的答案,以及2)模型偶尔输出相关Wikipedia段落而无法直接解决用户的问题。
为了克服这些挑战,我们引入了一个互补的Verbose Cloning步骤。此阶段涉及利用人工标注的提示来创建一个verbose版本的模型,该模型能够生成深入的,更详细的响应。然后,我们采用上下文蒸馏来产生一种新模型,该模型不仅具有对齐能力,而且对用户问题产生了彻底而广泛的响应。上下文蒸馏通过在由(Topic-Guided Red-Teaming) Self-Instruct产生的合成问题,以及对应的由verbosely提示的principle-engraved模型产生的相应响应上训练。附录C中提供了旨在鼓励principle-engraved模型生成详细向响应的提示。
3.5 Discussion
有趣的是,与先前的 first-following-then-align框架相反,即SFT(有监督的微调) + RLHF(从人类反馈中进行强化学习),SELF-ALIGN优先通过Principle-Driven Self-Alignment和Principle Engraving来提高无害性和可靠性。随后,它通过使用Verbose Cloning来提高其有用性(指令遵循能力)。确定哪种范式(first-following-then-align或first-align-then-following)更优可能需要以后进行研究。
此外,整个SELF-ALIGN(包括Self-Instruct)仅需要少于300行的标注(包括种子提示,原则和示例)。这项成就强调了这种方法在使AI模型与人类价值观和意图的对齐模型中的监督效率和有效性。
4.Dromedary
附录





















 288
288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









