






摘要
我们提出了 Chameleon,这是一系列早期融合的基于token的混合模态模型,能够理解和生成任意序列的图像和文本。我们从一开始就概述了稳定的训练方法、对齐方法以及为早期融合、基于token的混合模态设置量身定制的架构参数化。这些模型在一系列全面的任务上进行评估,包括视觉问答、图像释义、文本生成、图像生成和长格式混合模态生成。Chameleon 展示了广泛而通用的功能,包括在图像释义任务中最先进的性能,在纯文本任务中优于 Llama-2,同时与 Mixtral 8x7B 和 Gemini-Pro 等模型相当,并可进行复杂图像生成,这全部都在一个模型中。根据人类对新的长格式混合模态生成评估的判断,它还匹配或超过了更大模型(包括 Gemini Pro 和 GPT-4V)的性能,其中提示或输出是包含图像和文本的混合序列。Chameleon 标志着完整多模态文档的统一建模向前迈出了重要一步。
1.介绍
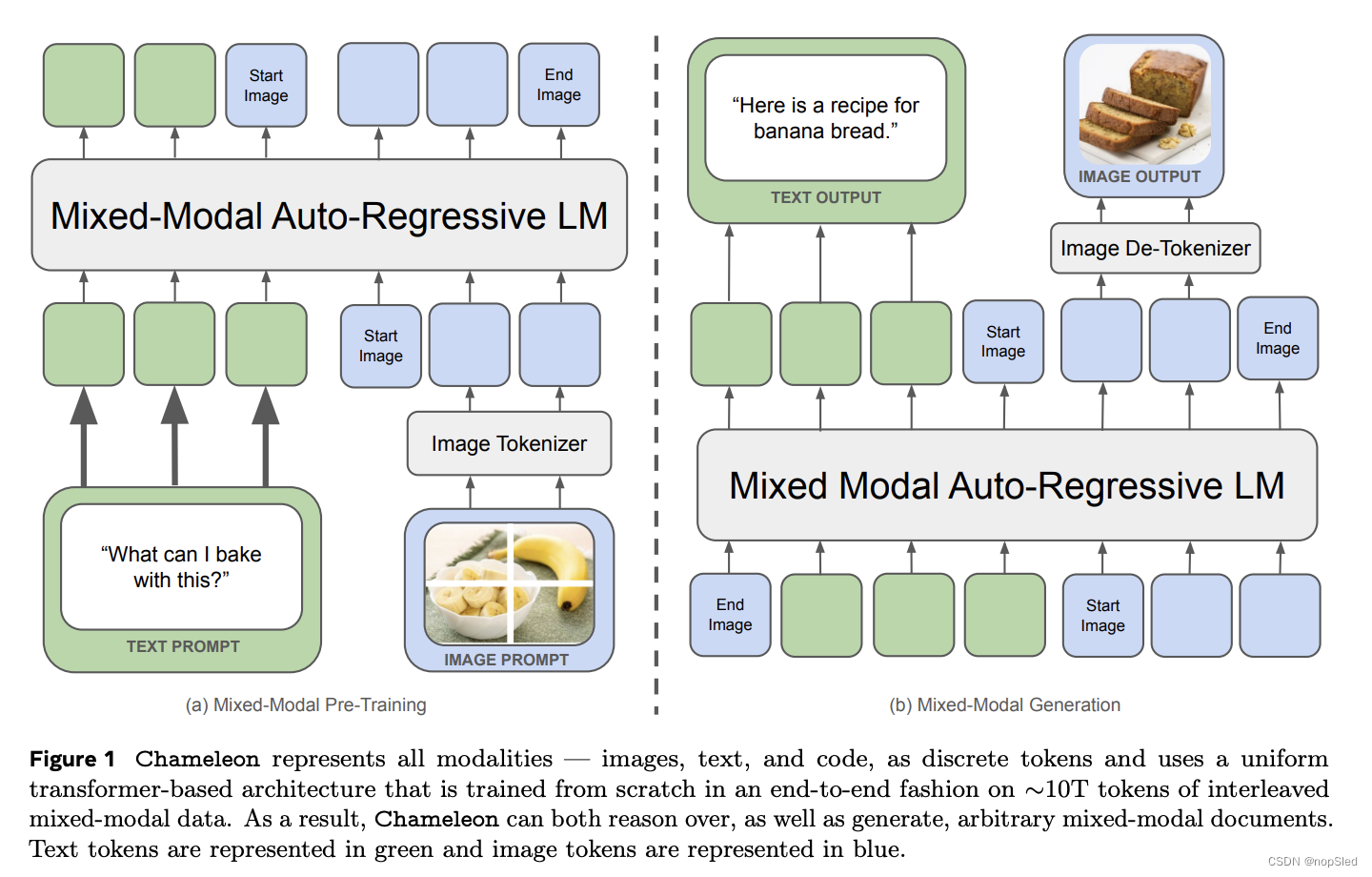
最近的多模态基础模型被广泛采用,但仍然单独对不同模态进行建模,通常使用特定模态的编码器或解码器。这可能会限制他们跨模态集成信息并生成可包含任意图像和文本序列的多模态文档的能力。在本文中,我们提出了 Chameleon,这是一系列混合模态基础模型,能够生成任意交替的文本和图像内容的混合序列并进行推理(图 2-4)。这允许完整的多模态文档建模,这是标准多模态任务的直接概括,例如图像生成、图像理解和推理以及纯文本LLM。Chameleon 从一开始就被设计为混合模型,并使用从头开始以端到端方式在所有模态(即图像、文本和代码)的交替混合数据上训练的统一架构。
我们的统一方法对图像和文本模态使用完全基于token的表示(图 1)。通过将图像量化为离散token(类似于文本中的单词),我们可以将相同的transformer架构应用于图像和文本token的序列,而不需要单独的图像/文本编码器或特定领域的解码器。这种早期融合方法从一开始就将所有模态投射到共享的表示空间中,允许跨模态的无缝推理和生成。然而,它也带来了重大的技术挑战,特别是在优化稳定性和扩展方面。
我们通过结构创新和训练技术的结合来应对这些挑战。我们对 Transformer 架构进行了新的修改,例如query-key归一化和层归一化的修改,我们发现这对于混合模态设置中的稳定训练至关重要(第 2.3 节)。我们进一步展示了如何将用于纯文本LLM的监督微调方法适应混合模态设置,从而实现大规模的强对齐(第 3 节)。使用这些技术,我们成功地训练了 Chameleon-34B,其token数量是 Llama-2 的 5 倍,其支持新的混合模态应用,同时在单模态基准上仍然匹配甚至超越现有的 LLM。
广泛的评估表明 Chameleon 是一个能够广泛执行多种任务的模型。在视觉问答和图像释义基准测试中,Chameleon-34B 实现了最先进的性能,优于 Flamingo、IDEFICS 和 Llava-1.5(第 5.2 节)等模型。同时,它在纯文本基准测试中保持了可比的性能,在常识推理和阅读理解任务上与 Mixtral 8x7B 和 Gemini-Pro 等模型相当(第 5.1 节)。但也许最令人印象深刻的是,Chameleon 在混合模态推理和生成方面解锁了全新的功能。
由于仅使用静态的公开基准来评估模型性能可能受到限制,因此我们还通过测量对开放提示的混合模态长格式响应的质量来进行精心设计的人类评估实验。Chameleon-34B 大大优于 Gemini-Pro 和 GPT-4V(第 4 节)等强基线,在成对比较中,相对 Gemini-Pro 的偏好率为 60.4%,相对 GPT-4V 的偏好率为 51.6%。
总之,我们提出以下贡献:
- 我们推出了 Chameleon,这是一系列基于早期融合token的混合模态模型,能够推理并生成交替的图像文本文档,为开放多模态基础模型树立了新的标准。
- 我们引入了架构创新和训练技术,可以对基于早期融合token的模型进行稳定且可扩展的训练,解决混合模态学习中的关键挑战。
- 通过广泛的评估,我们在不同的视觉语言基准测试中展示了最先进的性能,同时在纯文本任务和高质量图像生成上保持竞争性能,所有这些都在同一模型中进行。
- 我们对开放式混合模态推理和生成进行了首次大规模人类评估,展示了 Chameleon 在这种新环境中的独特能力。
Chameleon 代表着朝着实现能够灵活推理和生成多模态内容的统一基础模型的愿景迈出了重要一步。
2.Pre-Training
除了文本之外,Chameleon 将图像表示为一系列离散token,并利用自回归 Transformer 的缩放特性。我们在训练过程中呈现图像和文本的任何顺序,从纯文本到单个文本/图像对,再到完整交替的文本图像文档。
2.1 Tokenization
Image Tokenization。我们基于 Gafni et al. (2022) 训练了一个新的图像tokenizer,它将 512 × 512 图像从大小为 8192 的code编码为 1024 个离散token。为了训练这个tokenizer,我们仅使用许可图像。考虑到生成人脸的重要性,我们在预训练期间将人脸图像的百分比上采样了 2 倍。我们tokenizer的一个核心弱点是重建具有大量文本的图像,因此在涉及繁重的 OCR 相关任务时,我们的模型的能力受到限制。
Tokenizer。我们使用sentencepiece库在下面概述的训练数据子集上训练一个新的 BPE tokenizer,词表大小为 65,536,其中包括 8192 个图像code token。
2.2 Pre-Training Data
我们将预训练阶段划分为两个单独的阶段。第一阶段占训练的前80%,第二阶段占训练的后20%。对于所有文本到图像对,我们进行旋转,以便 50% 的占比图像出现在文本之前(即图像释义)。
2.2.1 First Stage
在第一阶段,我们使用由以下超大规模完全无监督数据集组成的数据混合物。
Text-Only:我们使用各种文本数据集,包括用于训练 LLaMa-2 和 CodeLLaMa 的预训练数据的组合,总共 2.9 万亿个纯文本token。
Text-Image:预训练的文本图像数据是公开数据源和许可数据的组合。然后调整图像大小并居中裁剪为 512 × 512 图像以进行tokenizer。总共我们包含 14 亿个文本-图像对,这会产生 1.5 万亿个文本-图像token。
Text/Image Interleaved:我们从公开的网络来源获取数据,不包括来自 Meta 产品或服务的数据,总共 4000 亿个交替文本和图像数据的token,与 Laurençon et al. (2023) 类似。我们对图像应用与“文本到图像”中应用的相同的过滤。
2.2.2 Second Stage
在第二阶段,我们将第一阶段数据的权重降低了 50%,并混合更高质量的数据集,同时保持图像文本token的相似比例。我们还包括来自大量指令微调数据集中经过过滤的训练集子集。
2.3 Stability
当 Chameleon 模型的参数超过 8B 且 token 数量超过 1T 时,维持稳定的训练是一项挑战,不稳定性通常只会在训练后期出现。我们采用以下架构和优化方法来实现稳定性。
Architecture。我们的架构在很大程度上遵循了 LLaMa-2。对于归一化,我们继续使用 RMSNorm;我们使用 SwiGLU 激活函数和旋转位置嵌入 (RoPE)。
我们发现,由于训练中后期范数增长缓慢,标准 LLaMa 架构表现出复杂的发散。我们将发散的原因缩小到当使用熵值变化很大的多种模态进行训练时,由于 softmax 的平移不变性(即
s
o
f
t
m
a
x
(
z
)
=
s
o
f
t
m
a
x
(
z
+
c
)
softmax(z) = softmax(z + c)
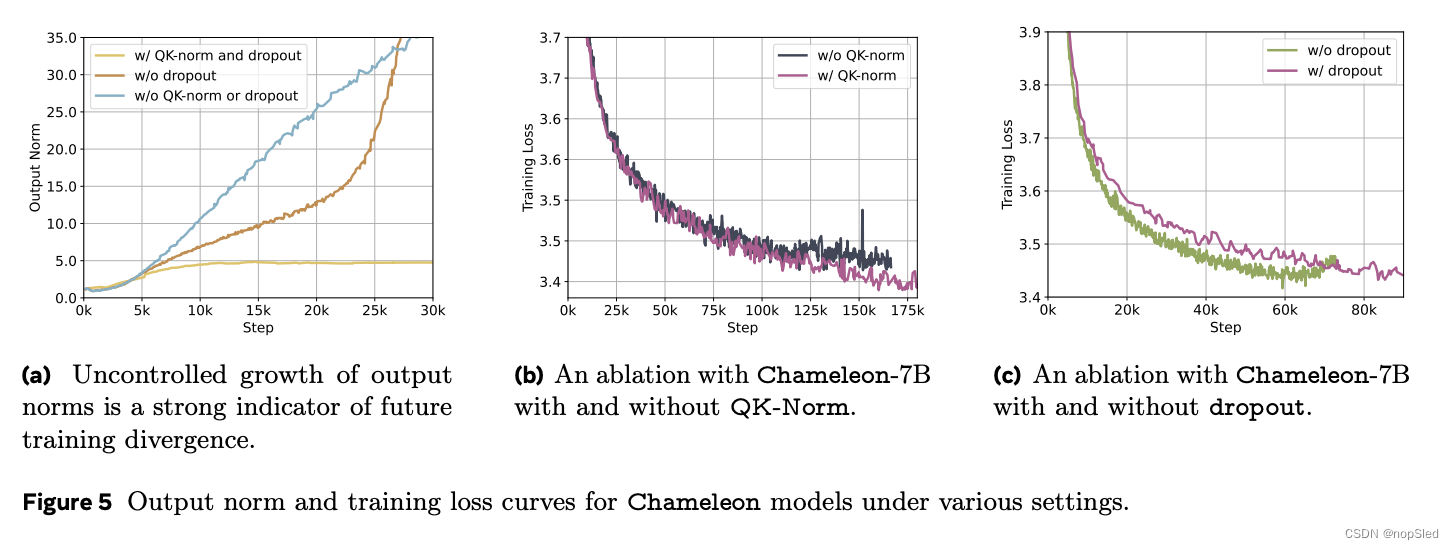
softmax(z)=softmax(z+c)),softmax 操作会出现问题。由于我们在模态之间共享模型的所有权重,因此每种模态都会尝试通过略微增加其范数来与其他模态“竞争”;虽然在训练开始时没有问题,但一旦我们超出 bf16 的有效表示范围,就会出现发散(在图 6b 中,我们表明没有图像生成的消融实验是没有发散的)。在单峰设置中,这个问题也被称为 logit 漂移问题。在图 5a 中,我们绘制了训练过程中最后一层 Transformer 的输出范数,我们发现,尽管训练发散可能在训练进度的 20-30% 之后显现,但监控输出范数的不受控制的增长与预测未来的损失发散密切相关。
softmax 运算出现在 transformer 中的两个地方:核心注意力机制和 logits 上的 softmax。受 Dehghani et al. (2023) 和 Wortsman et al. (2023) 的启发,我们首先通过使用query-key归一化 (QK-Norm) 来修改 Llama 架构。QK-Norm 通过将层归一化应用于注意力中的query和key向量来直接控制输入到 softmax 的范数增长。
在图 5b 中,我们展示了使用和不使用 QK-Norm 的 Chameleon-7B 的训练损失曲线,后者在训练周期的大约 20% 后出现分歧。
我们发现,要通过控制范数增长来稳定 Chameleon-7B,除了 QK 归一化之外,还需要在注意力层和前馈层之后引入 dropout(见图 5c)。然而,这种方法不足以稳定 Chameleon-34B,这需要对范数进行额外的重新排序。具体来说,我们在 transformer 块中使用了 Liu et al. (2021) 中提出的归一化策略。Swin Transformer 策略的归一化好处是它限制了前馈块的范数增长,考虑到 SwiGLU 激活函数的乘法性质,这可能会带来额外的问题。如果
h
h
h 表示在将自注意力应用于输入
x
x
x 后时刻
t
t
t 的隐藏向量,则:
Chameleon-34B:
h
=
x
+
a
t
t
e
n
t
i
o
n
_
n
o
r
m
(
a
t
t
e
n
t
i
o
n
(
x
)
)
o
u
t
p
u
t
=
h
+
f
f
n
_
n
o
r
m
(
f
e
e
d
_
f
o
r
w
a
r
d
(
h
)
)
\begin{array}{cc} h=x+attention\_norm(attention(x))\\ output=h+ffn\_norm(feed\_forward(h)) \end{array}
h=x+attention_norm(attention(x))output=h+ffn_norm(feed_forward(h))
Llama2:
h
=
x
+
a
t
t
e
n
t
i
o
n
(
a
t
t
e
n
t
i
o
n
_
n
o
r
m
(
x
)
)
o
u
t
p
u
t
=
h
+
f
e
e
d
_
f
o
r
w
a
r
d
(
f
f
n
_
n
o
r
m
(
h
)
)
\begin{array}{cc} h=x+attention(attention\_norm(x))\\ output=h+feed\_forward(ffn\_norm(h)) \end{array}
h=x+attention(attention_norm(x))output=h+feed_forward(ffn_norm(h))
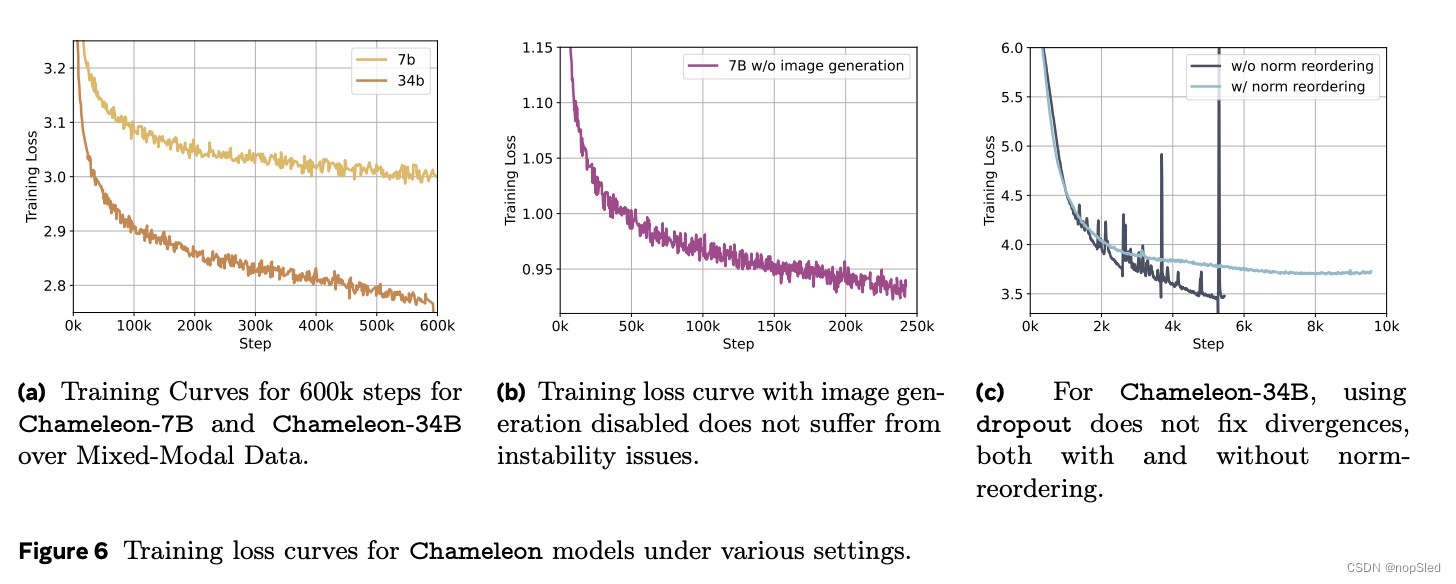
在 LLaMa-2 参数化时,使用和不使用归一化重排序从头开始训练模型时,困惑度没有差异。此外,我们发现这种类型的归一化与 dropout 结合使用效果不佳,因此,我们在不使用 dropout 的情况下训练 Chameleon-34B(图 6c)。此外,我们回溯发现,当使用归一化重排序时,Chameleon 7B 也可以在没有 dropout 的情况下稳定地进行训练,但 QK 归一化在这两种情况下都是必不可少的。我们在图 6a 中绘制了 Chameleon-7B 和 Chameleon-34B 的前 600k 步的训练曲线。
Optimization。我们的训练过程使用 AdamW 优化器,
β
1
β_1
β1 设置为 0.9,
β
2
β_2
β2 设置为 0.95,
ϵ
=
1
0
−
5
ϵ = 10^{−5}
ϵ=10−5。我们使用 4000 步的线性warm-up,学习率呈指数衰减,直至 0。此外,我们应用 0.1 的权重衰减和阈值为 1.0 的全局梯度裁剪。我们对 Chameleon-7B 使用 0.1 的 dropout 来保证训练稳定性,但对 Chameleon-34B 则不使用(见图 5c 和 6c)。
在 Transformer 内部进行 softmax 时应用 QK-Norm 并不能解决最终 softmax 中的 logit 偏移问题。根据 Chowdhery et al. (2022); Wortsman et al. (2023) 的研究,我们应用了 z-loss 正则化。具体来说,我们通过在我们的损失函数中添加
1
0
−
5
l
o
g
2
Z
10^{−5} log^2 Z
10−5log2Z 来正则化 softmax 函数
σ
(
x
)
i
=
e
x
i
Z
σ(x)_i =\frac{e^{x_i}}{Z}
σ(x)i=Zexi 的配分函数
Z
Z
Z,其中
Z
=
∑
i
e
x
i
Z =\sum_ie^{x_i}
Z=∑iexi。
对于 Chameleon-7B,使用 dropout 和 z-loss 来实现稳定性非常重要,而 Chameleon-34B 只需要 z-loss(图 6c)。
Chameleon-7B 的训练全局batch大小为
2
23
2^{23}
223(约 8M)个 token,而 Chameleon-34B 的训练全局batch大小为
3
×
2
22
3×2^{22}
3×222(约 12M)个 token。我们在整个训练数据集上进行了 2.1 个 epoch,训练期间总共看到了 9.2 万亿个 token。我们在图 6a 中展示了前 60 万个训练步骤(Chameleon-7B 为 55%,Chameleon-34B 为 80%)。
Pre-Training Hardware。我们的模型预训练是在 Meta 的研究超级集群 (RSC) 上进行的,我们的对齐是在其他内部研究集群上进行的。NVIDIA A100 80 GB GPU 为这两种环境提供支持。主要区别在于互连技术:RSC 采用 NVIDIA Quantum InfiniBand,而我们的研究集群采用 Elastic Fabric。我们在表 2 中报告了预训练的 GPU 使用情况。

2.4 Inference
为了支持自动化和人工的对齐和评估,并展示我们的方法的应用就绪性,我们增强了关于交替生成的推理策略,以提高吞吐量并减少延迟。
自回归混合模态生成在推理时引入了与性能相关的独特挑战。这些包括:
- Data-dependencies per-step:鉴于我们的解码公式会根据模型在特定步骤中生成图像还是文本而变化,因此必须在每个步骤中检查token(即以阻塞方式从 GPU 复制到 CPU)以指导控制流。
- Masking for modality-constrained generation:为了促进特定模态的生成(例如,仅图像生成),在去tokenizer时必须屏蔽和忽略不属于特定模态空间的token。
- Fixed-sized text units:与本质上长度可变的纯文本生成不同,基于token的图像生成会生成与图像相对应的固定大小的token块。
鉴于这些独特的挑战,我们基于 PyTorch 构建了一个独立的推理管道,并由 xformers 的 GPU 内核提供支持。
我们的推理实现支持文本和图像的流式传输。以流式传输方式生成时,每个生成步骤都需要依赖于token的条件逻辑。但是,如果没有流式传输,则可以以融合方式生成图像token块而无需条件计算。在所有情况下,token掩码都会消除 GPU 上的分支。但是,即使在非流式传输设置中,在生成文本时,也必须检查每个输出token是否有图像起始token,以调节特定于图像的解码增强。
3.Alignment
我们遵循最近的研究成果,使用基于有监督微调的轻量级对齐阶段对精心设计的高质量数据集进行调整。我们包括一系列不同类型的数据,旨在展示模型能力并提高安全性
3.1 Data

我们将有监督微调 (SFT) 数据集分为以下类别:文本、代码、视觉对话、图像生成、交替文本/图像生成和安全。我们在图 7 中包括了 Chameleon-SFT 数据集中每个类别的示例。
我们从 LLaMa-2 继承了 Text SFT 数据集,从 CodeLLaMa 继承了 Code SFT 数据集。对于 Image Generation SFT 数据集,我们使用 Schuhmann et al. (2022) 的aesthetic分类器,通过应用和过滤我们授权数据中的每幅图像来整理出效果极佳的图像。我们首先从aesthetic分类器中选择评分至少为 6 的图像,然后选择尺寸和长宽比最接近 512 × 512(我们图像标记器的原始分辨率)的前 64K 张图像。
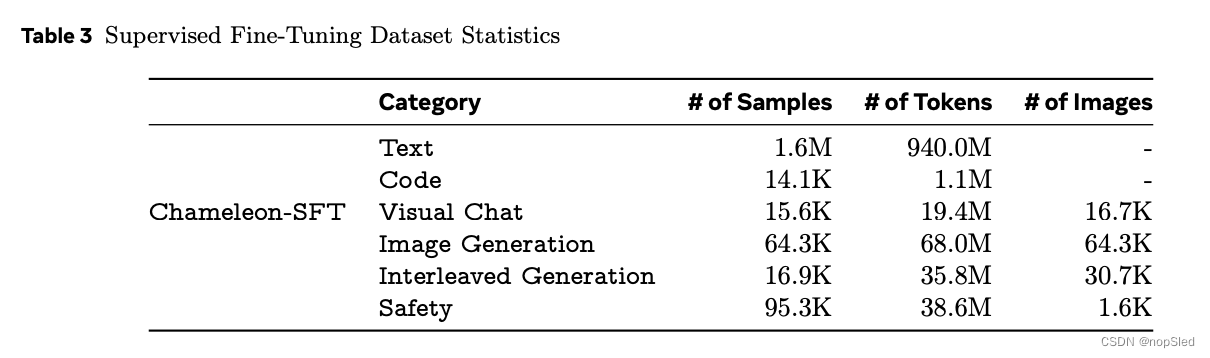
对于视觉对话和交替文本/图像生成 SFT 数据,我们专注于使用第三方供应商进行非常高质量的数据收集,遵循 Touvron et al. (2023); Zhou et al. (2023) 推荐的类似策略。我们不包括任何 Meta 用户数据。我们在表 3 中展示了数据集的统计数据。
Safety Data。我们收集了一系列可能引发模型生成不安全内容的提示,并将它们与拒绝响应(例如“I can’t help with that.”)进行匹配。这些提示涵盖了各种敏感话题,例如暴力、管制物质、隐私和性内容。我们收集的安全调优数据包括来自 LLaMa-2-Chat 的示例、使用 Rainbow Teaming 生成的基于合成文本的示例、从 Pick-A-Pic 手动选择用于安全测试的图像生成提示、网络安全示例,以及通过手动标注和自动扩展内部收集的混合模态提示。收集混合模态提示尤为重要,因为它解决了潜在的多模态攻击,这些数据不在纯文本和文本到图像安全调优数据集的分布范围内。
3.2 Fine-Tuning Strategy
Data Balancing。我们发现,在 SFT 阶段平衡各模态数据对于高质量对齐非常重要。具体来说,在 SFT 阶段,如果模态配比之间存在严重不平衡(或者当特定模态应该触发时),模型会学习生成该模态的无条件先验,这可能会抑制或过度夸大单个模态的生成。
Optimization。我们的有监督微调策略采用余弦学习率,初始速率为 1e-5,权重衰减设置为 0.1。我们保持batch大小为 128,可容纳最多 4096 个token的序列。在微调期间,每个数据集实例都包含一个成对的提示及其对应的答案。为了提高效率,我们将尽可能多的提示和答案pack到每个序列中,插入一个不同的token来划分提示的结束和答案的开始。我们使用自回归训练目标,有选择地mask提示token的损失。这种有针对性的方法使我们能够仅根据答案标记优化模型,从而总体上带来轻微的收益。我们还应用了 0.05 的 dropout。此外,我们保持与预训练期间使用的相同的 z-loss。在有监督微调期间,提示中的图像会使用边框填充调整大小,以确保图像中包含所有信息,而答案中的图像则会进行中心裁剪,以确保视觉上良好的图像生成质量。

















 658
658

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









