







转载请注明作者和出处:https://blog.csdn.net/qq_28810395
运行平台: Windows 10
AIstudio官网:https://aistudio.baidu.com/ --飞桨领航团AI达人创造营

核心任务
- 数据的获取途径
- 数据处理与标注
- 数据预处理方法
- 模型训练评估
一、数据集的获取
通常来说,我们进行深度学习肯定需要大数据支持,我们的数据来源于各个比赛平台,公司开源,互联网爬虫等,也可将其获取类型分为公开数据集(MNIST ImageNet)与自建数据集(图片爬虫(ImageDownloader)、视频爬虫 (Annie)与数据采集(摄像头采集,数据众包)等)
下文列出了一系列高质量(CV领域)的数据集,每个深度学习爱好者都可以使用这些数据集来提高自己的能力。应用这些数据集将使您成为一名更好的数据科学家,并且您从中获得的东西将在您的职业生涯中具有无可估量的价值。我们还收录了具有当前最好结果(SOTA)的论文,供您浏览并改进您的模型。
-
MNIST
 MNIST是最受欢迎的深度学习数据集之一。它是一个手写数字数据集,包含一个60,000个样本的训练集和一个10,000个样本的测试集。这是一个很不错的数据集,它可用于在实际数据中尝试学习技术和深度识别模式,并且它花费极少的时间和精力在数据预处理上。
MNIST是最受欢迎的深度学习数据集之一。它是一个手写数字数据集,包含一个60,000个样本的训练集和一个10,000个样本的测试集。这是一个很不错的数据集,它可用于在实际数据中尝试学习技术和深度识别模式,并且它花费极少的时间和精力在数据预处理上。
大小: 约50 MB
数量: 10个类别,70,000张图片
SOTA:Dynamic Routing Between Capsules -
MS-COCO

COCO是一个可用于object detection, segmentation and caption的大型数据集。
大小:约25 GB(压缩包)
数量: 330K张图像,80个对象类别,每个图像5个描述,25万个人(已标记)
SOTA: Mask R-CNN -
ImageNet

ImageNet是基于WordNet层次结构组织的图像数据集。WordNet包含约100,000个短语,ImageNet平均提供了约1000个图像来说明每个短语。
大小:约150GB
数量:图像总数约1,500,000; 每个都有多个边界框和相应的类标签。
SOTA: Aggregated Residual Transformations for Deep Neural Networks -
Open Images Dataset
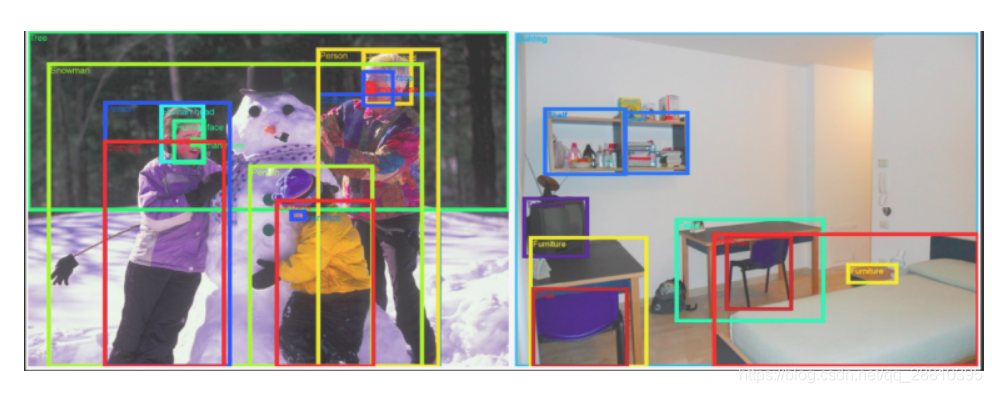
Open Images Dataset是一个包含超过900万个链接图像的数据集。其中包含9,011,219张图像的训练集,41,260张图像的验证集以及125,436张图像的测试集。它的图像种类跨越数千个类别,且有图像层级的标注框进行注释。
大小: 500 GB(压缩包)
数量: 9,011,219张超过5k标签的图像
SOTA: Resnet 101 image classification model (trained on V2 data):Model checkpoint, Checkpoint readme, Inference code. -
VisualQA
 VQA是一个包含有关图像的开放式问题的数据集。这些问题需要理解视野和语言。
VQA是一个包含有关图像的开放式问题的数据集。这些问题需要理解视野和语言。
大小: 25 GB(压缩包)
数量: 265,016张图片,每张图片至少3个问题,每个问题10个基本事实
SOTA: Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challenge -
The Street View House Numbers (SVHN)

SVHN是一个为训练目标检测算法而“真实”存在的一个图像数据集–来自于谷歌街景中的房屋号码。它对图像预处理和格式要求较低。与上边提到的MNIST数据集类似,但SVHN包含更多的标记数据(超过600,000个图像)。
大小: 2.5 GB
数量: 10个类别,共6,30,420张图片
SOTA:Distributional Smoothing With Virtual Adversarial Training -
CIFAR-10

CIFAR-10数据集是图像分类的另一个神级入门数据集。它由10个类别60,000个图像组成(每个类在上图中表示为一行)。总共有50,000个训练图像和10,000个测试图像。数据集分为6个部分 - 5个训练批次(training batches)和1个测试批次(test batches)。每个批次(batch)有10,000个图像。
大小:170 MB
数量:10个类别,共60,000张图片
SOTA:ShakeDrop regularization -
Fashion-MNIST

Fashion-MNIST包含60,000个训练图像和10,000个测试图像。它是一个类似MNIST的时尚产品数据库。开发人员认为MNIST已被过度使用,因此他们将其作为该数据集的直接替代品。每张图片都以灰度显示,并与10个类别的标签相关联。
大小:30 MB
数量:10个类,70,000张图片
SOTA:Random Erasing Data Augmentation
二、 完整流程概述
1. 图像处理完整流程
- 图片数据获取如上述
- 图片数据清洗
----初步了解数据,筛选掉不合适的图片 - 图片数据标注
- 图片数据预处理(data preprocessing)
----标准化 standardlization
一 中心化 = 去均值 mean normallization
一 将各个维度中心化到0
一 目的是加快收敛速度,在某些激活函数上表现更好
一 归一化 = 除以标准差
一 将各个维度的方差标准化处于[-1,1]之间
一 目的是提高收敛效率,统一不同输入范围的数据对于模型学习的影响,映射到激活函数有效梯度的值域 - 图片数据准备data preparation(训练+测试阶段)
----划分训练集,验证集,以及测试集 - 图片数据增强data augjmentation(训练阶段 )
----CV常见的数据增强
· 随机旋转
· 随机水平或者重直翻转
; · 缩放
· 剪裁
· 平移
· 调整亮度、对比度、饱和度、色差等等
· 注入噪声
· 基于生成对抗网络GAN做数搪增强AutoAugment等


2. 纯数据处理完整流程
-
感知数据
----初步了解数据
----记录和特征的数量特征的名称
----抽样了解记录中的数值特点描述性统计结果
----特征类型
----与相关知识领域数据结合,特征融合 -
数据清理
----转换数据类型
----处理缺失数据
----处理离群数据 -
特征变换
----特征数值化
----特征二值化
----OneHot编码
----特征离散化特征
----规范化
区间变换
标准化
归一化 -
特征选择
----封装器法
循序特征选择
穷举特征选择
递归特征选择
----过滤器法
----嵌入法 -
特征抽取
----无监督特征抽取
主成分分析
因子分析
----有监督特征抽取
三、数据处理
官方数据处理成VOC或者COCO
-
Microsoft COCO(Common Objects in Context)
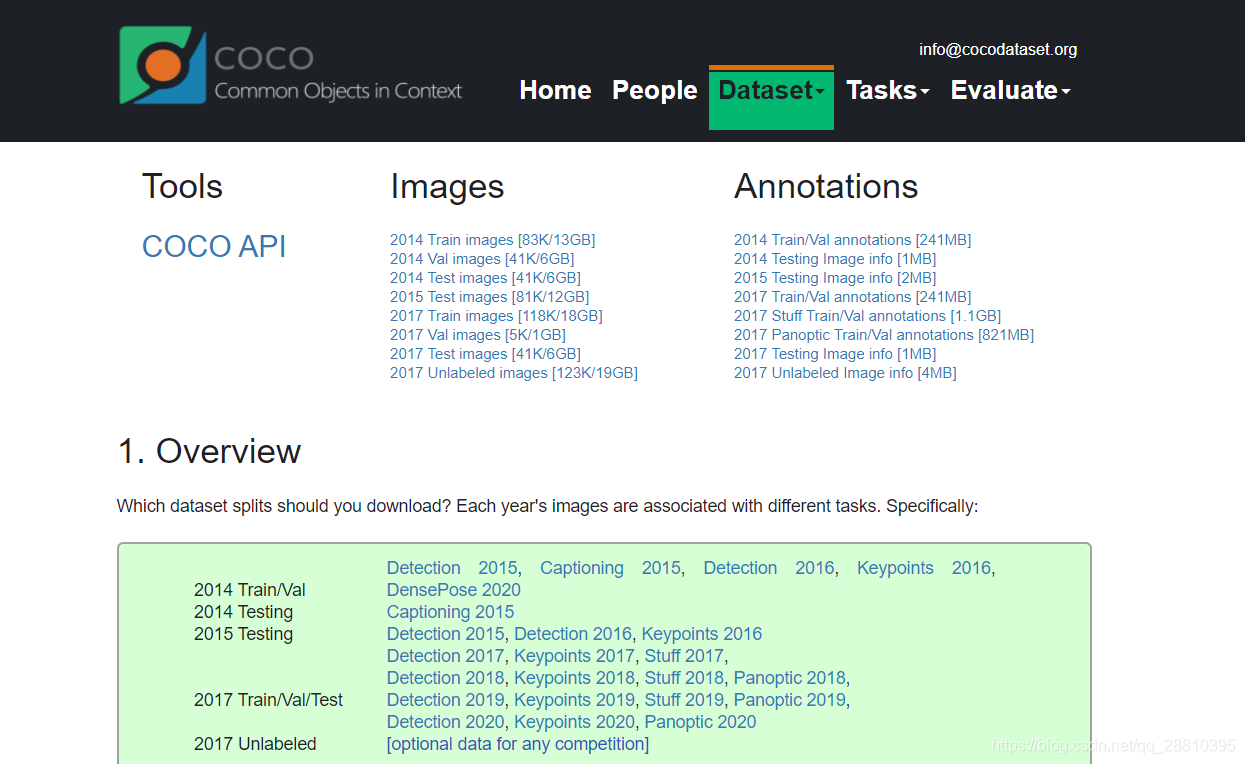
COCO的 全称是Common Objects in COntext,是微软团队提供的一个可以用来进行图像识别的数据集。MS COCO数据集中的图像分为训练、验证和测试集。COCO通过在Flickr上搜索80个对象类别和各种场景类型来收集图像,其使用了亚马逊的Mechanical Turk(AMT)。
COCO数据集是微软团队获取的一个可以用来图像recognition+segmentation+captioning 数据集,其官方说明网址:http://mscoco.org/
该数据集主要有的特点如下:(1)Object segmentation(2)Recognition in Context(3)Multiple objects per image(4)More than 300,000 images(5)More than 2 Million instances(6)80 object categories(7)5 captions per image(8)Keypoints on 100,000 people
该数据集主要解决3个问题:目标检测,目标之间的上下文关系,目标的2维上的精确定位。数据集的对比示意图:
COCO的2019挑战赛有如下内容COCO 2019 Detection, Keypoint, Panoptic, and DensePose Challenges。
COCO通过大量使用Amazon Mechanical Turk来收集数据。COCO数据集现在有3种标注类型:object instances(目标实例), object keypoints(目标上的关键点), 和image captions(看图说话),使用JSON文件存储。比如下面就是Gemfield下载的COCO 2017年训练集中的标注文件:
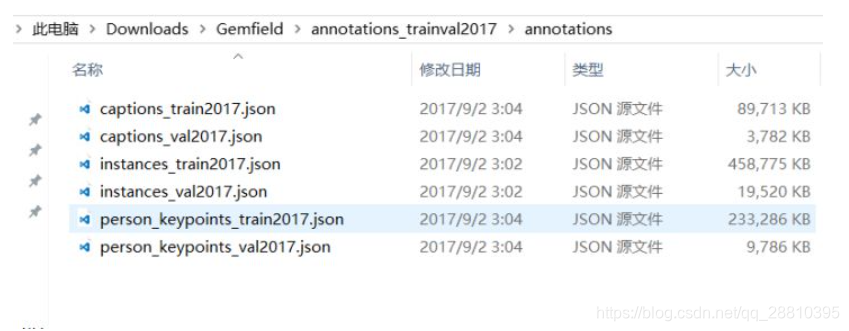
可以看到其中有上面所述的三种类型,每种类型又包含了训练和验证,所以共6个JSON文件。
COCO格式文件夹路径样式:COCO_2017/ ├── val2017 # 总的验证集 ├── train2017 # 总的训练集 ├── annotations # COCO标注 │ ├── instances_train2017.json # object instances(目标实例) ---目标实例的训练集标注 │ ├── instances_val2017.json # object instances(目标实例) ---目标实例的验证集标注 │ ├── person_keypoints_train2017.json # object keypoints(目标上的关键点) ---关键点检测的训练集标注 │ ├── person_keypoints_val2017.json # object keypoints(目标上的关键点) ---关键点检测的验证集标注 │ ├── captions_train2017.json # image captions(看图说话) ---看图说话的训练集标注 │ ├── captions_val2017.json # image captions(看图说话) ---看图说话的验证集标注 -
Pascal VOC(Pascal Visual Object Classes)

VOC数据集是目标检测经常用的一个数据集,从05年到12年都会举办比赛(比赛有task: Classification 、Detection(将图片中所有的目标用bounding box框出来) 、 Segmentation(将图片中所有的目标分割出来)、Person Layout)
VOC2007:中包含9963张标注过的图片, 由train/val/test三部分组成, 共标注出24,640个物体。 VOC2007的test数据label已经公布, 之后的没有公布(只有图片,没有label)。
VOC2012:对于检测任务,VOC2012的trainval/test包含08-11年的所有对应图片。 trainval有11540张图片共27450个物体。 对于分割任务, VOC2012的trainval包含07-11年的所有对应图片, test只包含08-11。trainval有 2913张图片共6929个物体。
————————————————
这些物体一共分为20类:- Person: person
- Animal: bird, cat, cow, dog, horse, sheep
- Vehicle:aeroplane, bicycle, boat, bus, car, motorbike, train
- Indoor: bottle,chair, dining table, potted plant, sofa, tv/monitor
数据集下载后解压得到一个名为VOCdevkit的文件夹,该文件夹结构如下:
VOC_2017/ ├── Annotations # 每张图片相关的标注信息,xml格式 ├── ImageSets │ ├── Main # 各个类别所在图片的文件名 ├── JPEGImages # 包括训练验证测试用到的所有图片 ├── label_list.txt # 标签的类别数 ├── train_val.txt #训练集 ├── val.txt # 验证集 -
Object Keypoint 类型的标注格式
{ "info": info, "licenses": [license], "images": [image], "annotations": [annotation], "categories": [category] }其中,info、licenses、images这三个结构体/类型,在不同的JSON文件中这三个类型是一样的,定义是共享的(object instances(目标实例), object keypoints(目标上的关键点), image captions(看图说话))。不共享的是annotation和category这两种结构体,他们在不同类型的JSON文件中是不一样的。 新增的keypoints是一个长度为3 X k的数组,其中k是category中keypoints的总数量。每一个keypoint是一个长度为3的数组,第一和第二个元素分别是x和y坐标值,第三个元素是个标志位v,v为0时表示这个关键点没有标注(这种情况下x=y=v=0),v为1时表示这个关键点标注了但是不可见(被遮挡了),v为2时表示这个关键点标注了同时也可见。
um_keypoints表示这个目标上被标注的关键点的数量(v>0),比较小的目标上可能就无法标注关键点。annotation{ "keypoints": [x1,y1,v1,...], "num_keypoints": int, "id": int, "image_id": int, "category_id": int, "segmentation": RLE or [polygon], "area": float, "bbox": [x,y,width,height], "iscrowd": 0 or 1, }示例:
{ "segmentation": [[125.12,539.69,140.94,522.43,100.67,496.54,84.85,469.21,73.35,450.52,104.99,342.65,168.27,290.88,179.78,288,189.84,286.56,191.28,260.67,202.79,240.54,221.48,237.66,248.81,243.42,257.44,256.36,253.12,262.11,253.12,275.06,299.15,233.35,329.35,207.46,355.24,206.02,363.87,206.02,365.3,210.34,373.93,221.84,363.87,226.16,363.87,237.66,350.92,237.66,332.22,234.79,314.97,249.17,271.82,313.89,253.12,326.83,227.24,352.72,214.29,357.03,212.85,372.85,208.54,395.87,228.67,414.56,245.93,421.75,266.07,424.63,276.13,437.57,266.07,450.52,284.76,464.9,286.2,479.28,291.96,489.35,310.65,512.36,284.76,549.75,244.49,522.43,215.73,546.88,199.91,558.38,204.22,565.57,189.84,568.45,184.09,575.64,172.58,578.52,145.26,567.01,117.93,551.19,133.75,532.49]], "num_keypoints": 10, "area": 47803.27955, "iscrowd": 0, "keypoints": [0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,142,309,1,177,320,2,191,398,2,237,317,2,233,426,2,306,233,2,92,452,2,123,468,2,0,0,0,251,469,2,0,0,0,162,551,2], "image_id": 425226,"bbox": [73.35,206.02,300.58,372.5],"category_id": 1, "id": 183126}, -
categories字段
最后,对于每一个category结构体,相比Object Instance中的category新增了2个额外的字段,keypoints是一个长度为k的数组,包含了每个关键点的名字;skeleton定义了各个关键点之间的连接性(比如人的左手腕和左肘就是连接的,但是左手腕和右手腕就不是)。
目前,COCO的keypoints只标注了person category (分类为人)。{ "id": int, "name": str, "supercategory": str, "keypoints": [str], "skeleton": [edge] }示例:
{ "supercategory": "person", "id": 1, "name": "person", "keypoints": ["nose","left_eye","right_eye","left_ear","right_ear","left_shoulder","right_shoulder","left_elbow","right_elbow","left_wrist","right_wrist","left_hip","right_hip","left_knee","right_knee","left_ankle","right_ankle"], "skeleton": [[16,14],[14,12],[17,15],[15,13],[12,13],[6,12],[7,13],[6,7],[6,8],[7,9],[8,10],[9,11],[2,3],[1,2],[1,3],[2,4],[3,5],[4,6],[5,7]] } -
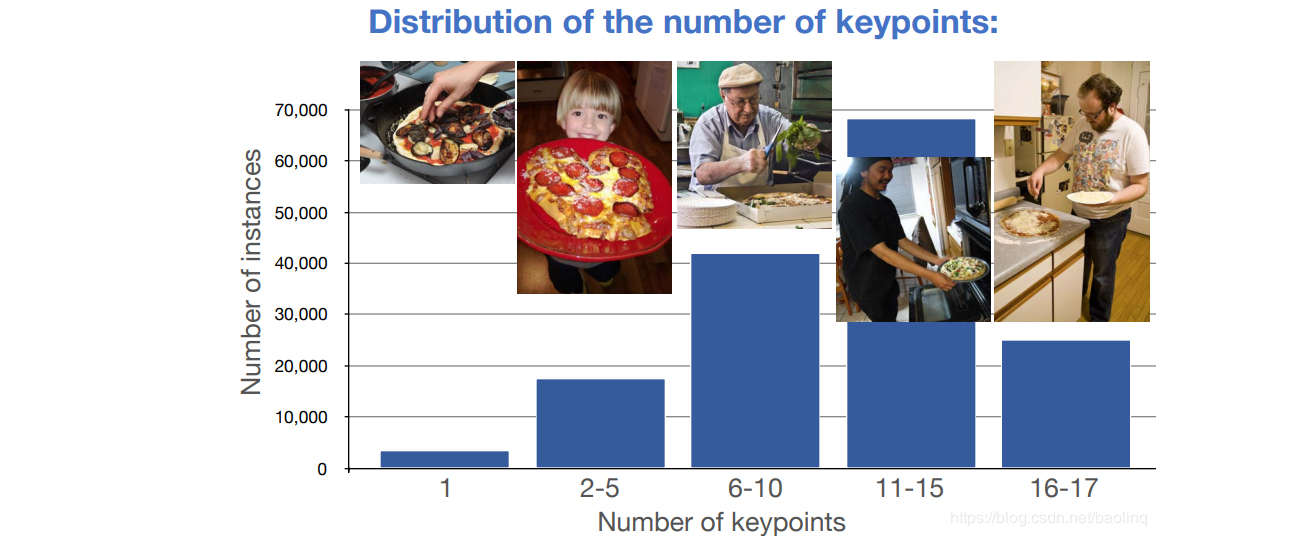
数据集统计信息
人体关键点标注,每个人体关键点个数的分布情况,其中11-15这个范围的人体是最多的,有接近70000人,6-10其次,超过40000人,后面依次为16-17,2-5,…
-
自定义数据集常见标注工具
对于图像分类任务,我们只要将对应的图片是哪个类别划分好即可。对于检测任务和分割任务,目前比较流行的数据标注工具是labelimg、labelme,分别用于检测任务与分割任务的标注。 标注工具Github地址:
labelimg (https://github.com/tzutalin/labelImg)
labelme (https://github.com/wkentaro/labelme)
PPOCRLabel (https://github.com/PaddlePaddle/PaddleOCR)
四、数据处理方法
-
图像的本质
我们常见的图片其实分为两种,一种叫位图,另一种叫做矢量图。如下图所示:

位图由像素组成,采用点阵、矩阵来存储,每个像素的取值范围为[0, 255],0为黑色,255为白色,中间值为灰色。有三通道R、G、B。
位图的特点:- 由像素点定义一放大图片会糊(即失真)
- 文件体积较大
- 色彩表现丰富逼真

矢量图的基础信息由数学矢量记载,记载一些线条、形状信息。
矢量图的特点:- 超矢量定义
- 放大不模糊
- 文件体积较小
矢量图的缺点:
表现力差 通常用于CNN卷积的图片,不能用矢量图去计算,因为矢量图没有矩阵。
-
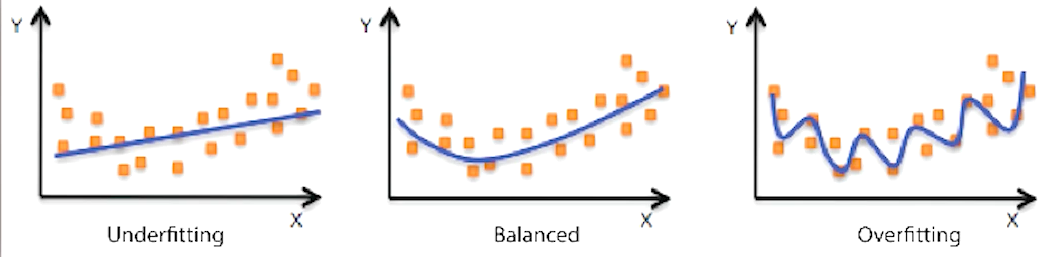
数据增强
很多深度学习的模型复杂度太高了,且在数据量少的情况下,比较容易造成过拟合(通俗来说就是训练的这个模型它太沉浸在这个训练样本当中的一些特质上面了),表现为的这个模型呢受到了很多无关因素的影响。
所得出的结果就是在没有看到过的样本上对它做出预测呢就表现的不太好。
五、模型训练与评估
- 模型训练
-
模型选择
对于特定任务最优建模方法的选择或者对特定模型最佳参数的选择 -
交叉验证
在训练数据集上运行模型(算法)并且在测试数据集上测试效果,迭代 更新数据模型的修改,这种方式被称为“交叉验证”(将数据分为训练集 和 测试集),使用训练集构建模型,并使用测试集评估模型提供修改建议。
模型的选择会尽可能多的选择算法进行执行,并比较每个算法的执行结果
- 模型评估
-
拓展介绍mAP:
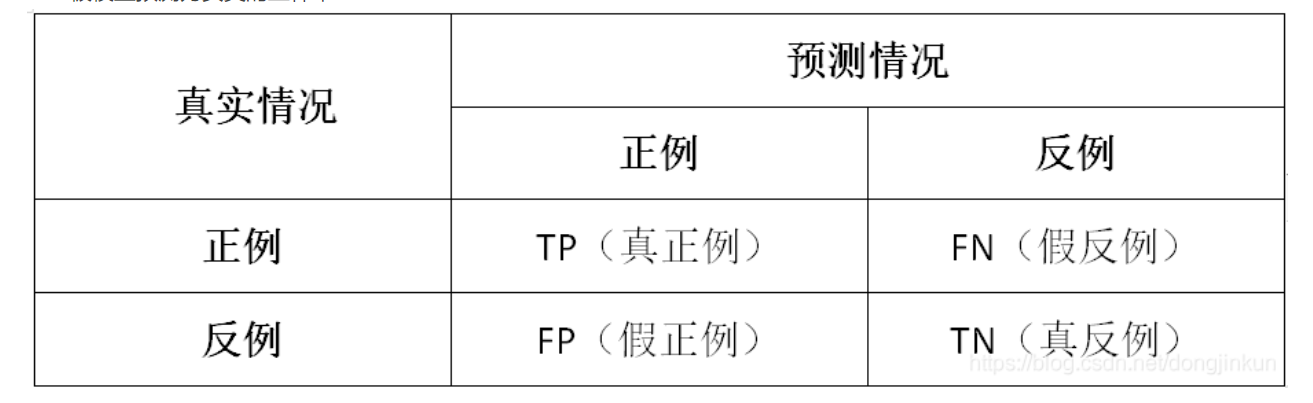
在机器学习领域中,用于评价一个模型的性能有多种指标,其中几项就是FP、FN、TP、TN、精确率(Precision)、召回率(Recall)、准确率(Accuracy)。
mean Average Precision, 即各类别AP的平均值,是AP:PR 曲线下面积。
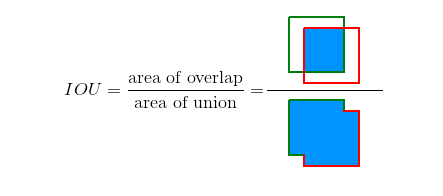
此前先了解一下IOU评判标准:
TP、FP、FN、TN
常见的评判方式,第一位的T,F代表正确或者错误。第二位的P和N代表判断的正确或者错误-
True Positive (TP): I o U > I O U threshold \mathrm{IoU}>I O U_{\text {threshold }} IoU>IOUthreshold (IOU的阈值一般取0.5)的所有检测框数量(同一Ground Truth只计算一次),可以理解为真实框,或者标准答案
-
False Positive (FP): I o U < I O U threshold \mathrm{IoU}<I O U_{\text {threshold }} IoU<IOUthreshold 的所有检测框数量
-
False Negative (FN): 没有检测到的 GT 的数量
-
True Negative (TN): mAP中无用到
查准率(Precision): Precision = T P T P + F P = T P all detections =\frac{T P}{T P+F P}=\frac{T P}{\text { all detections }} =TP+FPTP= all detections TP
查全率(Recall): Recall = T P T P + F N = T P all ground truths =\frac{T P}{T P+F N}=\frac{T P}{\text { all ground truths }} =TP+FNTP= all ground truths TP
二者绘制的曲线称为 P-R 曲线:
查准率:P 为纵轴y 查全率:R 为横轴x轴,如下图

mAP值即为,PR曲线下的面积。 -
六、模型推理预测
使用模型进行预测,同时使用pdx.det.visualize将结果可视化,
可视化结果将保存到work/PaddleDetection/output/PPYOLO/vdl_log下,
载入模型推理保存图片至work/PaddleDetection/output/PPYOLO/img下。
七、 总结
本次课程主要为大家介绍了数据集获取,以及数据标注、数据划分、数据增强处理方法和简单的口罩检测实现,及其用数据增强和不用数据增强的对比实验,体现了数据增强在AI学习中的重要性。
八、参考信息
- https://blog.csdn.net/fendouaini/article/details/79871922?
- https://aistudio.baidu.com/aistudio/projectdetail/2250040
- https://blog.csdn.net/bestrivern/article/details/88846977?
- https://blog.csdn.net/Daycym/article/details/84206786?















 1207
1207











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









