







之所以这一篇又开始学习,之前使用markdown版本,观感不是那么自然,所以一直没有完成。而我沉迷于心态的各种调整与周遭环境的动态适应中,没有动起笔,完成这篇早就该在四月底完成的博文(课程学习)。
所以,谴责的话要少讲一点。学习的动力提升一点,比如,顺利毕业什么的。
这节复习课就从存储过程开始讲起,首先我们要知道,我们学习的存储过程到底是个什么东西?
目录
19.1 存储过程
这就要跟我们前面学习到的大多数SQL语句联系起来,那些针对一表或多表操作的单条语句完成了,许多业务场景下的数据需求。但实际业务场景下,我们操出一条一条的SQL语句来满足数据需求,不太现实,所以需要有多条语句组合起来,完成以下这些情况的目标:
-
□ 为了处理订单,必须核对以保证库存中有相应的物品。
-
□ 如果物品有库存,需要预定,不再出售给别的人,并且减少物品数据以反映正确的库存量。
-
□ 库存中没有的物品需要订购,这需要与供应商进行某种交互。
-
□ 关于哪些物品入库(并且可以立即发货)和哪些物品退订,需要通知相应的顾客。
上面这些情况,并不罕见,业务中很多处理确实需要针对多表操作(虽然身为学习者的我并没有多少多表经验),需要执行的具体SQL语句次序啥的也不固定,可能根据库存物品余量而变化。
那么我们的代码编写工作,就可以创建一个存储过程,存储过程就是为了多次使用而保存的一或多条SQL语句,理解成批文件,和有些脚本文件类似,虽然它们的作用并不仅仅为批处理。
加个备注:因为Access和SQLite不支持存储过程,而MySQL 5 已经支持存储过程(最开始的学习介绍已经提到过,这次的复习使用MySQL的版本是5.7,所以可以顺利跟进)。书里只提到Oracle和SQL Server的语法,如果我需要MySQL,我肯定会直接上网搜的(希望看到学习笔记的你,有需要也自行检索)。
19.2 为什么要使用存储过程
了解存储过程是啥,那么我们为啥用它,这里我还没往下看,大概率猜测一下,节省重复劳动。再来看看书上的,书上这样提到:
□ 通过把处理封装在一个易用的单元中,可以简化复杂的操作。
□ 由于不要求反复建立一系列处理步骤,因而保证了数据的一致性。如果所有开发人员和应用程序都使用同一存储过程,则所使用的代码都是相同的。这一点的延伸就是防止错误。需要执行的步骤越多,出错的可能性就越大。防止错误保证了数据的一致性。□ 简化对变动的管理。如果表名、列名或业务逻辑(或别的内容)有变化,那么只需要更改存储过程的代码。使用它的人员甚至不需要知道这些变化。这一点的延伸就是安全性。通过存储过程限制对基础数据的访问,减少了数据讹误(无意识的或别的原因所导致的数据讹误)的机会。
□ 因为存储过程通常以编译过的形式存储,所以DBMS处理命令所需的工作量少,提高了性能。
□ 存在一些只能用在单个请求中的SQL元素和特性,存储过程可以使用它们来编写功能更强更灵活的代码。
我并不打算把这段内容展开来说,一是一眼扫过去,感觉把简单的东西复杂化了,二是下面有个很准确的概括,就是简单、安全、高性能。
这当然算是存储过程的优点,也是我们选择它解决需求的理由,但它有没有不好的地方?当然。
如果算是不同DBMS语法不同的话,可移植性不高是一个。
另外,编写它并不是什么简单的事情,我们需要再学习学习,简单的基本SQL语句会了不一定能写出准确优美的存储过程,这里提到许多DBA(数据库管理员,后不再说明)把限制存储过程的创建作为安全措施。
具体编写,得参看相应的DBMS文档。大多数DBMS将编写存储过程所需的安全和访问权限与执行存储过程所需的安全和访问权限区分开了,即使不编写自己的存储过程,也能用别人的。
19.3 执行存储过程
那么,我们还是来看看怎么执行,怎么使用。一次编写,多次执行。
执行的SQL语句为:EXECUTE。 接受存储过程名和需要传递来的任何参数,来,走个例子:

EXECUTE AddNewProduct('JTS01','Stuffed Eiffel Tower',6.49,'Plush stuffed toy with the text LaTour Eiffel in red white and blue');很奇怪,一直在报错。
瞄了一眼时间,居然十一点半了,有些拖拉星人要养成习惯啊,回家学习,早日完成这个课程的学习,加强对SQL的理解。
打个中断先睡觉,明天接着写。
slogan是要喊的!刻意练习,每日精进!!!
续: 今天20200516,接着来学上次没学完的部分!
那天有个练习,是关于执行存储过程的。执行出现错误,我特地查了一下,为什么呢?首先我们要了解一下,执行语法是没问题的,一是对着书敲得不太可能出错(我已检查,无误),再就是执行存储过程的前提是,存储过程已经被创建,那么我们是否已经创建了呢?根据本文顺序,先讲的执行,所以这里问题定位在,未创建就执行。同时,找到一个使用MySQL创建执行存储过程的练习,需要自入。
先搁置这个问题,等后面创建好了,再来练习这个部分。往后走。
分析一下文中执行练习中名为AddNewProduct的存储过程,将新产品添加到Products表中,共有四个参数(供应商ID、产品名、价格和描述),匹配存储、预期变量、新行入表、属性入列。简单来说,就是把新产品的值新增进去,这里发现Products(被添加表)中还有一个pro_id列,作为该表主键,居然没有被添加,为什么不作为属性传递呢?文中提到:为了保证ID的自动生成,最好使用过程自动化,也就是我们日常使用表时候ID设置为自增而不是人为的去输入,这也是这个例子使用存储过程的意义所在。
接下来看看存储过程完成了操作:
-
□ 验证传递的数据,保证所有4个参数都有值;
-
□ 生成用作主键的唯一ID;
-
□ 将新产品插入Products表,在合适的列中存储生成的主键和传递的数据
上面三个基本操作,是存储过程在执行中主要完成的,具体DBMS,还可能包括以下这些执行选择:
-
□ 参数可选,具有不提供参数时的默认值;
-
□ 不按次序给出参数,以“参数=值”的方式给出参数值。
-
□ 输出参数,允许存储过程在正执行的应用程序中更新所用的参数。
-
□ 用SELECT语句检索数据。
-
□ 返回代码,允许存储过程返回一个值到正在执行的应用程序。
好,执行版块就学到这里,接下来进入创建部分。
19.4 创建存储过程
创建部分非常重要,书中用引例证明,做一个简单的存储过程:对邮件发送清单中具有邮件地址的顾客进行计数:
有点遗憾的是:书中选择的代码范例是Oracle和SQL Server的,并不适配我的学习背景,只好一边理解文中范例,一边配合MySQL语法进行实地操作:
(长达二十几分钟的探索,终于出现了Query OK的提示,泪目)下面介绍一下我的思路:
书中两个案例其实在用不同的DBMS语法讲述一个操作,类比创建方法,别名/输入/输出,方法体的构造,不同语法的原因,找寻MySQL的时候还误入了一下用户变量的坑,这里先放代码及截图再来解释一下:
记住,先设置一下结束标志:
DELIMITER $$ 或 DELIMITER //
至于为什么这样做,一条SQL操作结束了就跳出了,那么我们为了顺利存入整个操作并关闭也就是BEGIN和|END成功,就修改跳出逻辑,最后不操作了改回来就行(DELIMITER ;),除非你想后面都用这个操作符。
CREATE PROCEDURE MailingListCount(OUT ListCount int)
-> BEGIN
-> SELECT ListCount = COUNT(*)
-> FROM Customers
-> WHERE NOT ISNULL(cust_email);
-> END$$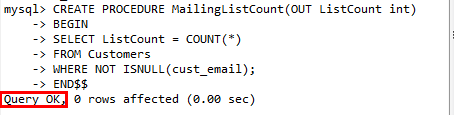
文章结尾会放这一段的探索,这里便于梳理逻辑,就不放了。介绍一下我的思路,顺便贴一下MySQL存储过程的语法。
对比书中给的另两种DBMS语法,可以看出共同的操作其实是从Customer表中取出cust_email为空的数,并赋给我们的输出,那么,MySQL语法特点是:BEGIN和END中间放操作和赋值,CREATE那一行用来声明别名、变量以及变量类型是输入还是输出,按照给的样例就是 先输入还是输出(IN or OUT or INOUT)最后一种慎用,很明显从我们最开始的样例需求来看,是输出,那么选择OUT,再就是起个别名,这里沿用Oracle中的命名ListCount,再就是变量类型,计数当然用int,这里有点小出入,文中样例给出的类型皆为INTERGER,其实都是一样的,不同的命名而已,我遵循参考教程中MySQL存储过程语法,使用int。
打出我们的BENGIN,因为输出参数已经设置好了,那么就直接来找我们需要的结果,SELECT-FROM-WHERE三件套,这里有个小问题需要注意,因为判断的结果是看cust_email值的有无,MySQL中用ISNULL函数,而不是像SQL Server版本中 NOT XX IS NULL,所以我替换了这个部分,当然我没有再次尝试能不能行,希望更快更简洁,就用这个函数吧。
最后就是我们的END,结束以后可以加上前面声明的结束标志“$$”,可以看到添加成功。
再来使用一下,看看是否得到和样例一样的结果,一样,MySQL有它自己的执行方法。
DELIMITER ;
SET @m_out = 0;
CALL MailingListCount(@m_out);
SELECT @m_out;
探索了好久,终于找到了,逻辑遵从上面,先使用SET设置一个变量用来接收结果,需要加@,再使用CALL调用过程,记住后面名字要和前面命名一致,再就是括号,括号内使用前面加上@符号的变量一起,再使用SELECT找到变量。结果打印出来,书上这里没有给出打印结果,因为设置变量那块不允许为空,我分别使用了“ 1 和 0 ”,测试结果都是这个NULL,姑且认为,count的结果就是没有。所以这里继续推进。
文中继续给出了另一个例子,在Orders表中插入一个新订单,加了特殊说明,样例程序仅适用于SQL Server:我先尝试着理解样例,再决定要不要迁移到MySQL上。
粗略解释一下:插入新订单的操作,首先是传入了,只有一个参数,也就是下订单顾客的ID,订单号和订单日期这两列是在存储过程中生成的,所以代码需要声明局部变量来存储订单号,接着检索当前最大订单号(MAX函数搞定)并自增1(SELECT搞定),然后用INSERT语句插入(新生成的订单号,当前系统日期[GETDATE函数搞定],顾客ID)组成的订单信息,再返回一个订单号就可以了。
加个注解及Mark,作为程序员,习惯两件事情,多版本+多注释,前者方便自己,后者不一定就仅仅便于他人。
数据库注解
-- 我是数据库注解
-- 所有的DBMS都支持我这种注解方式
-- 所以 为了某种可移植 请用这种方式添加注解(时间原因,刚好看完两种不同插入方法,就零点了,所提到的时间16日也跨过了,![]() )
)
为了更好地休息(划掉,并不。明天是周末,因为今天给家里大扫除,虽累,但也算真正意义上的第一个周末,里外打扫后说小眯十五分钟(甚至还定了闹钟,还是睡到了六点半,果然劳动使人快乐也更放松。之所以话这么多是因为这一课结束了。
长达半个月的(实际上是我的拖拉紧张和各种不安定因素)19课终于完结了。不撒花,不得意,不焦躁,不沉迷。
下面废话一点点:放上两张截图,是探索创建存储过程的截图,可以看到,还是进行了不同的尝试,有两个原因,1.MySQL的创建其实我并不熟悉,参看教程有一些晕,上面讲的案例和语法并没有加入查找操作的,而是一个DELETE;2.判空处理一直在报错,所以不能定位到到底是MySQL自身语法不适配还是创建的语法不对,那么索性抛开了两种参考,按照理解,自己来敲了结果给了惊喜。一次pass。而且也能很熟练的敲出命令,大概这就是深夜gc吧。希望所有的付出皆有三分回报,如果没有就当积福报。
 开始的位置,上一屏也有clear掉了。这开始可以看到
开始的位置,上一屏也有clear掉了。这开始可以看到
 滑到了第二屏,才开始出现探索成功的提示。
滑到了第二屏,才开始出现探索成功的提示。
还是那句老话,刻意练习,每日精进。渴求一个更加有体系,有逻辑的自己。
晚安吧,各位,后面推进这个课的速度可能要加快了,最慢两天得完成一课。还欠着其他课程呢!!















 93
93











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









