







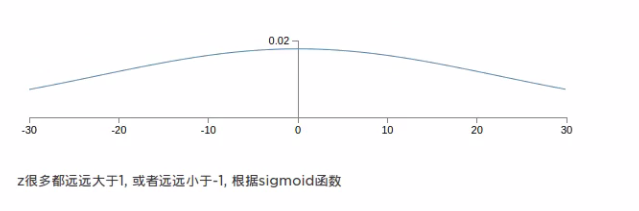
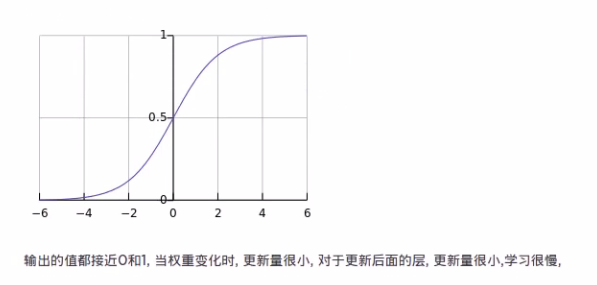
因为传统的初始化权重问题是用标准正态分布(均值为0,方差为1)随机初始化的,这其实是存在不合理的部分。
标准正态分布:
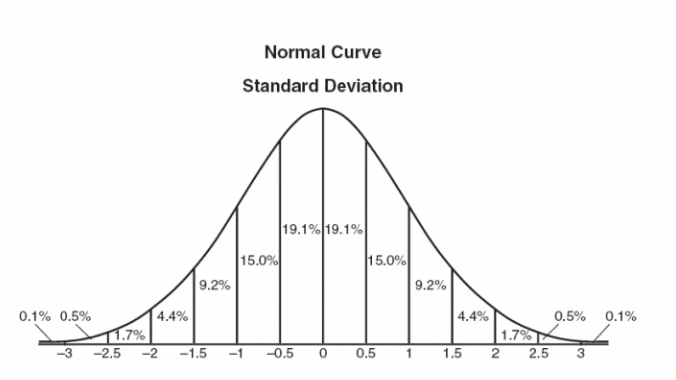

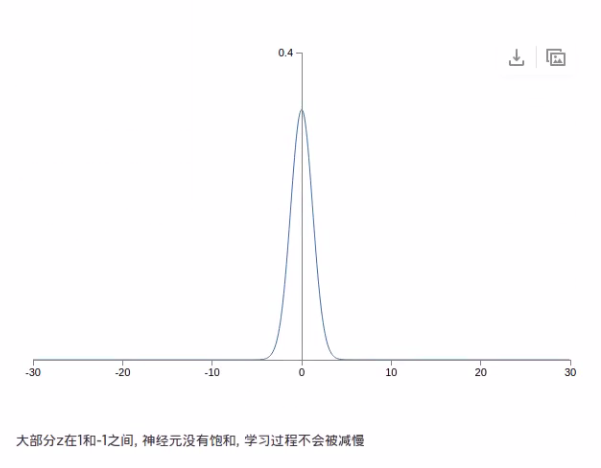
可以看出真实数据的分布其实是在靠近坡峰的部分,符合正态分布的。
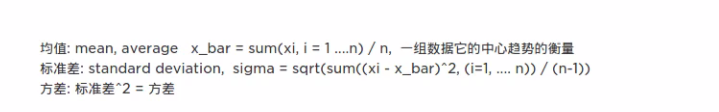
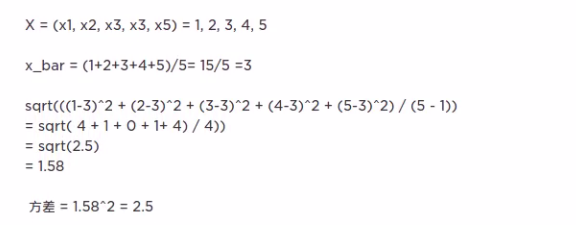
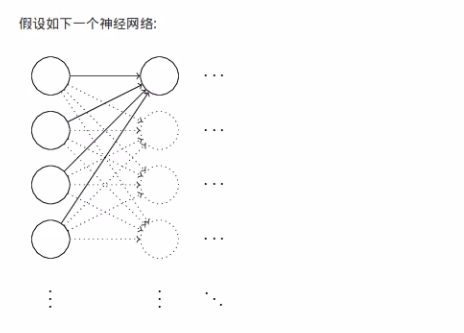



以下为转载
caffe中初始化权重
首先说明:在caffe/include/caffe中的 filer.hpp文件中有它的源文件,如果想看,可以看看哦,反正我是不想看,代码细节吧,现在不想知道太多,有个宏观的idea就可以啦,如果想看代码的具体的话,可以看:http://blog.csdn.net/xizero00/article/details/50921692,写的还是很不错的(不过有的地方的备注不对,不知道改过来了没)。
文件 filler.hpp提供了7种权值初始化的方法,分别为:常量初始化(constant)、高斯分布初始化(gaussian)、positive_unitball初始化、均匀分布初始化(uniform)、xavier初始化、msra初始化、双线性初始化(bilinear)。

275 Filler<Dtype>* GetFiller(const FillerParameter& param) { 276 const std::string& type = param.type(); 277 if (type == "constant") { 278 return new ConstantFiller<Dtype>(param); 279 } else if (type == "gaussian") { 280 return new GaussianFiller<Dtype>(param); 281 } else if (type == "positive_unitball") { 282 return new PositiveUnitballFiller<Dtype>(param); 283 } else if (type == "uniform") { 284 return new UniformFiller<Dtype>(param); 285 } else if (type == "xavier") { 286 return new XavierFiller<Dtype>(param); 287 } else if (type == "msra") { 288 return new MSRAFiller<Dtype>(param); 289 } else if (type == "bilinear") { 290 return new BilinearFiller<Dtype>(param); 291 } else { 292 CHECK(false) << "Unknown filler name: " << param.type(); 293 } 294
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4024
4024











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









