










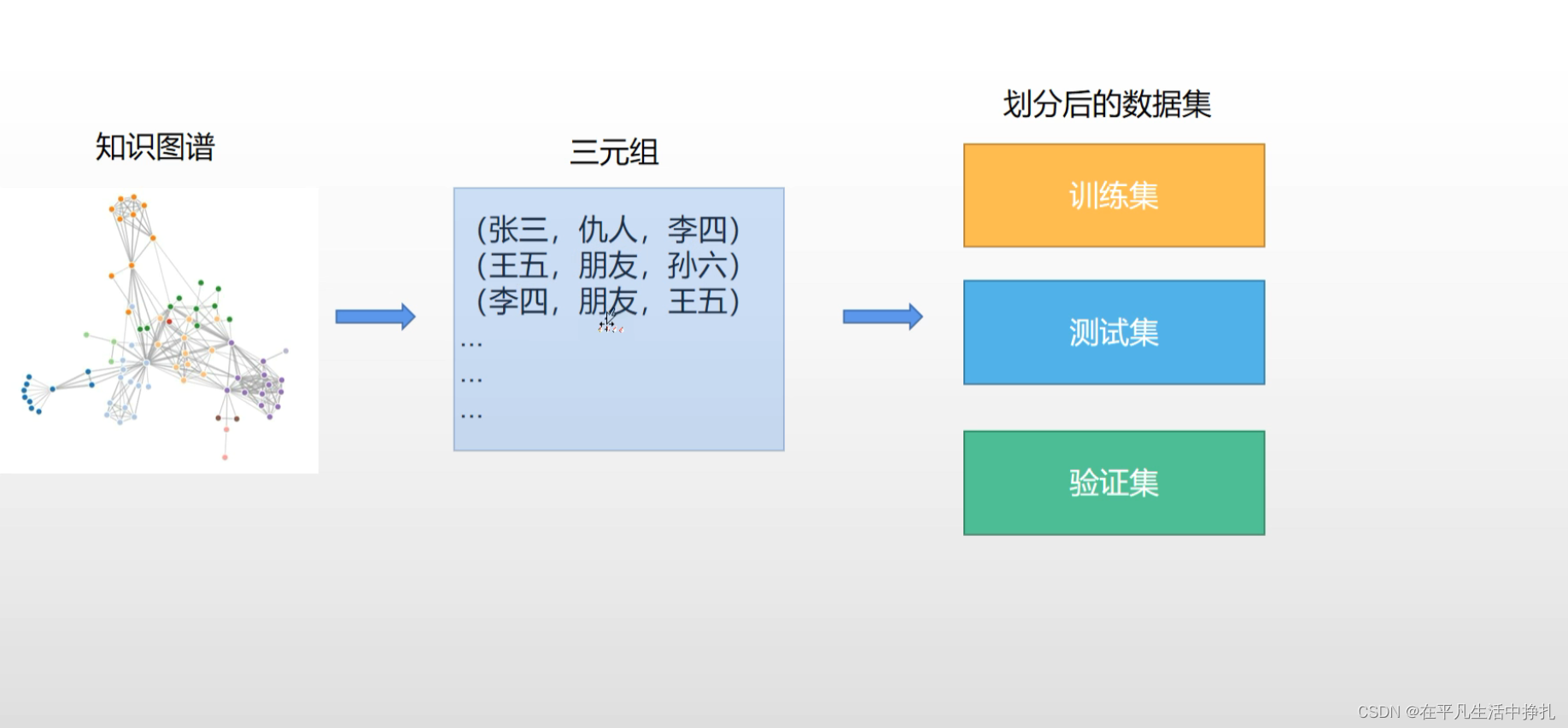
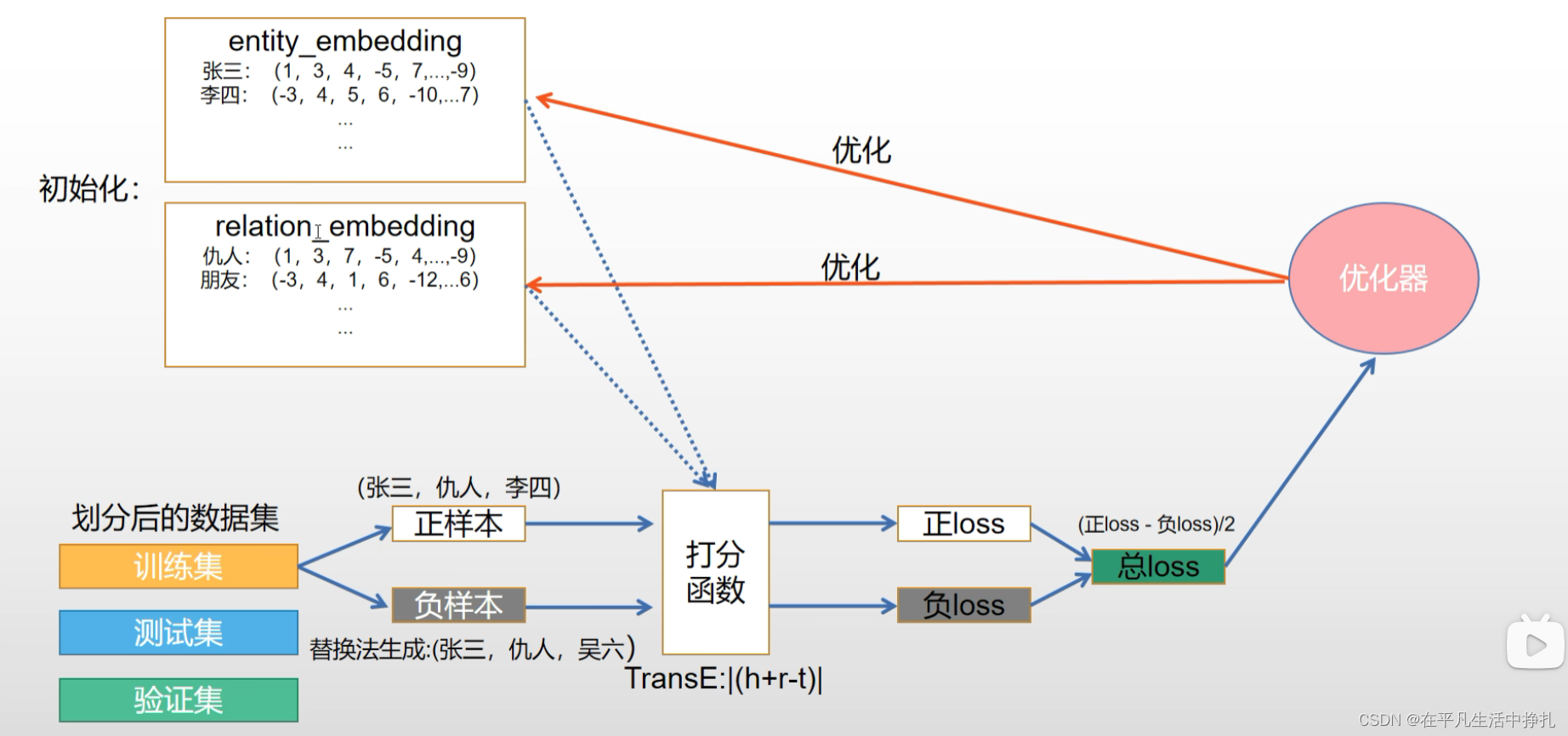
初始化:通过embedding将三元组信息提取为特征向量。
划分数据集:通过GBA(guity-by-association)原则创造负样本(加判断器确保生成的负样本正确)。
打分函数TransE:一个正则表达,一般是1/2范数。用于计算loss。表示头实体+关联-尾实体趋近于零,表示关联存在。
loss:经过打分函数TransE计算出,正样本中,张三(头实体)的仇人(关系)与李四(尾实体)更加接近(距离)。负样本中,张三(头实体)的仇人(关系)与吴六(尾实体)更加遥远(距离)。
优化器:用来优化entity_embedding。目的是经过迭代,让正样本loss无限趋近于零,让负样本loss无限趋近于无穷大。
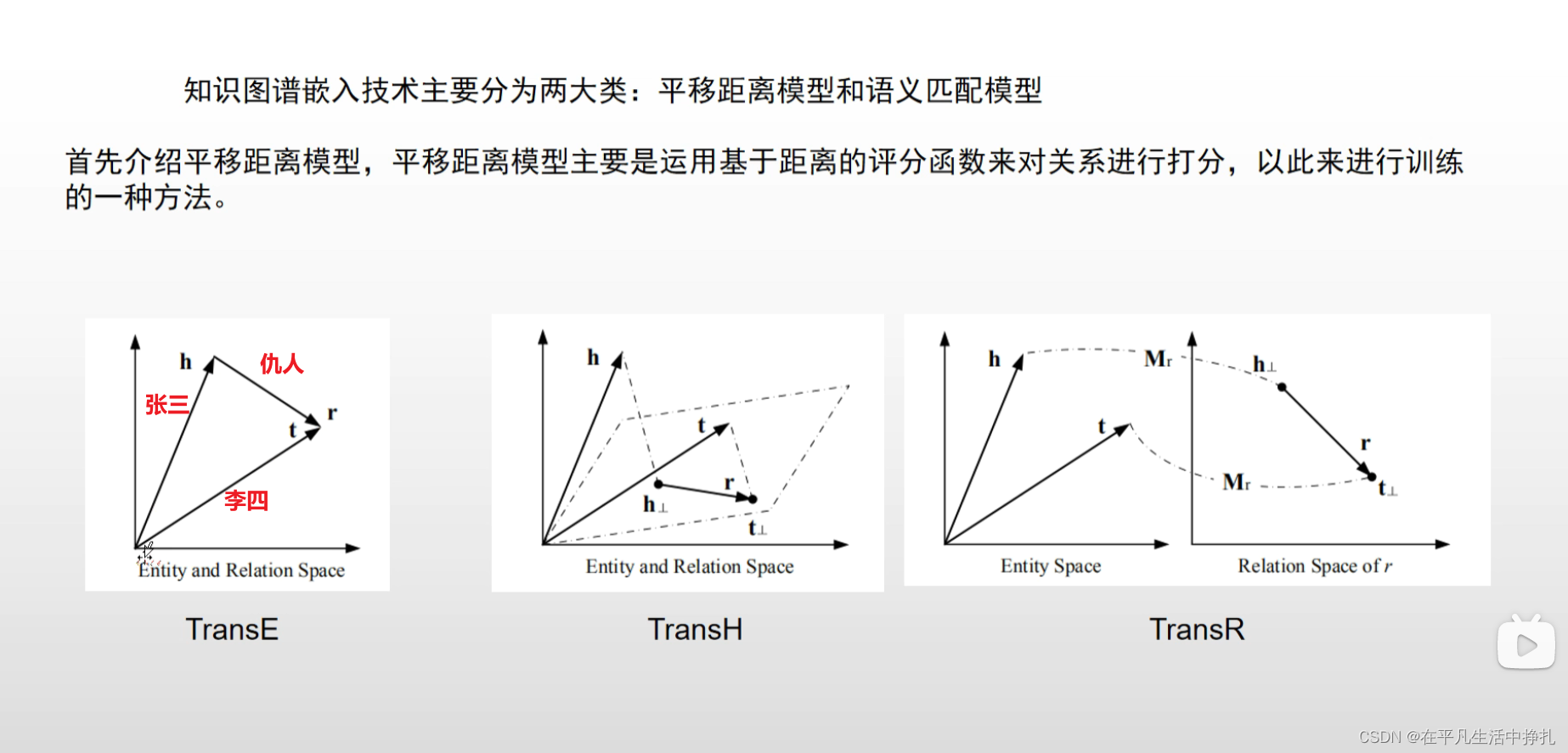 图中表明了TransE的向量表示。
图中表明了TransE的向量表示。
但是,TransE有个问题:
当张三有许多仇人的时候(头实体和关系唯一,尾实体不唯一),h向量和r向量是唯一的,t向量却有很多。这时候TransE优化到最后,会使得t向量长得都很像,向量t的实体失去了特异性。张三的仇人都长得一个样。
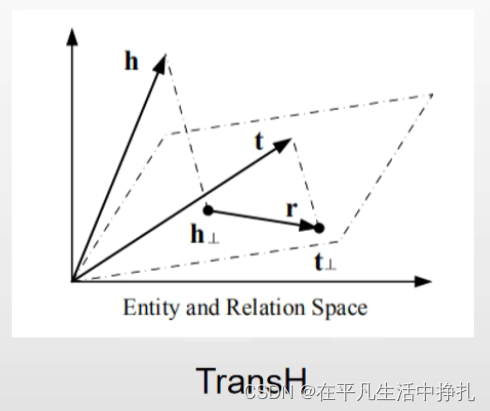
因此TransH方法,将h和r向量做投影,与每一个t向量在同一超平面以后再做类似TransE的向量计算。
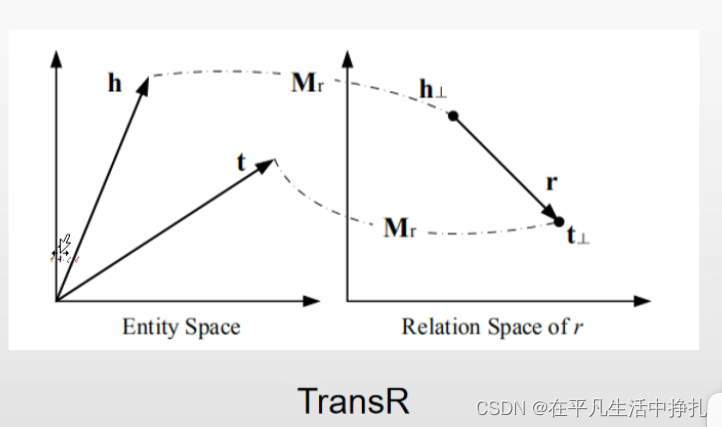
TransR方法,是以关系为空间,是通过Mr矩阵,将h和t投影到r空间,然后再进行向量的操作。















 86
86











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









