









如需转载请注明出处:https://blog.csdn.net/qq_29350001/article/details/78226286
讲到H.264除了前两篇文章提到的,I、P、B帧。参看: 图像和流媒体 -- I 帧,B帧,P帧,IDR帧的区别
还有其他相关术语:
NALU:H264编码数据存储或传输的基本单元,一般H264码流最开始的两个NALU是SPS和PPS,第三个NALU是IDR。SPS、PPS、SEI这三种NALU不属于帧的范畴。
SPS(Sequence Parameter Sets):序列参数集,作用于一系列连续的编码图像。
PPS(Picture Parameter Set):图像参数集,作用于编码视频序列中一个或多个独立的图像。
SEI(Supplemental enhancement information):附加增强信息,包含了视频画面定时等信息,一般放在主编码图像数据之前,在某些应用中,它可以被省略掉。
IDR(Instantaneous Decoding Refresh):即时解码刷新。
HRD(Hypothetical Reference Decoder):假想码流调度器。
上面这些知识我还是了解的。但还是思考了半晌,不知道从哪讲起?它们之间的关系又该怎么讲?
想了解更多内容,参看:新一代视频压缩编码标准-H.264_AVC(第二版).pdf
一、H.264 NALU语法结构
在H.264/AVC视频编码标准中,整个系统框架被分为了两个层面:视频编码层面(VCL)和网络抽象层面(NAL)。其中,前者负责有效表示视频数据的内容,而后者则负责格式化数据并提供头信息,以保证数据适合各种信道和存储介质上的传输。因此我们平时的每帧数据就是一个NAL单元(SPS与PPS除外)。在实际的H264数据帧中,往往帧前面带有00 00 00 01 或 00 00 01分隔符,一般来说编码器编出的首帧数据为PPS与SPS,接着为I帧……

然后我们参看:FFmpeg再学习 -- 视音频基础知识
使用 UltraEdit 查看一个 h.264 文件信息

其中 SPS、PPS 文章开始也讲了。
SPS(Sequence Parameter Sets):序列参数集,作用于一系列连续的编码图像。
PPS(Picture Parameter Set):图像参数集,作用于编码视频序列中一个或多个独立的图像。
如上图,在H264码流中,都是以"0x00 0x00 0x01"或者"0x00 0x00 0x00 0x01"为开始码的,找到开始码之后,使用开始码之后的第一个字节的低 5 位判断是否为 7(sps)或者 8(pps), 及 data[4] & 0x1f == 7 || data[4] & 0x1f == 8。然后对获取的 nal 去掉开始码之后进行 base64 编码,得到的信息就可以用于 sdp。 sps和pps需要用逗号分隔开来。
上图中,00 00 00 01是一个nalu的起始标志。后面的第一个字节,0x67,是nalu的类型,type &0x1f==0x7表示这个nalu是sps,type &0x1f==0x8表示是pps。
接下来我们来讲解一下NALU语法结构:
H264基本码流由一些列的NALU组成。原始的NALU单元组成:
[start code] + [NALU header] + [NALU payload];

H264基本码流结构分两层:视频编码层VCL和网络适配层NAL,这样使信号处理和网路传输分离

H.264码流在网络中传输时实际是以NALU的形式进行传输的.
每个NALU由一个字节的Header和RBSP组成.
NAL Header 的组成为:
forbidden_zero_bit(1bit) + nal_ref_idc(2bit) + nal_unit_type(5bit)
1、forbidden_zero_bit:
禁止位,初始为0,当网络发现NAL单元有比特错误时可设置该比特为1,以便接收方纠错或丢掉该单元。
2、nal_ref_idc:
nal重要性指示,标志该NAL单元的重要性,值越大,越重要,解码器在解码处理不过来的时候,可以丢掉重要性为0的NALU。
3、nal_unit_type:NALU类型取值如下表所示:
句法表中的 C 字段表示该句法元素的分类,这是为片区服务。

不过上面这张图,我实在没有找到出处啊。但是我在 x264 里看到了这个。

其中需要关注的是 SEI、SPS、PPS。我在 LIVE555 里又看到这个。

这不就是上面我们讲到的,nalu的类型 type &0x1f==0x7表示这个nalu是sps,type &0x1f==0x8表示是pps。
接下来我们来举个例子,来讲解下:
该视频下载:H.264 示例视频和工具
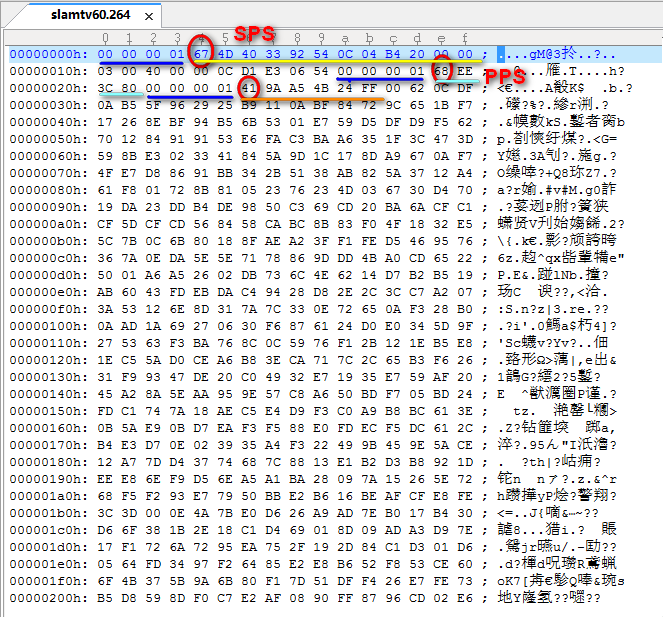
00 00 00 01 为起始符,67 即 nal_unit_type。
0x67的二进制是 0110 0111
则 forbidden_zero_bit(1bit) = 0;
nal_ref_idc(2bit) = 3;
nal_unit_type(5bit) = 7;即 SPS 类型。
然后看另一部分 RBSP
这里提一下 SODB 和 RBSP 关系
SODB(String Of Data Bits):最原始的编码数据RBSP, 长度不一定是8的倍数,此时需要对齐.
RBSP: 在SODB的后面填加了结尾比特(RBSP trailing bits 一个bit“1”)若干比特“0”,以便字节对齐。

我们知道码流是由一个个的NAL Unit组成的,NALU是由NALU头和RBSP数据组成,而RBSP可能是SPS,PPS,Slice或SEI,目前我们这里SEI不会出现,而且SPS位于第一个NALU,PPS位于第二个NALU,其他就是Slice(严谨点区分的话可以把IDR等等再分出来)了。
而上面这个h.264文件,相当于包含两个 NALU吧,第一个是SPS,第二个是PPS。
我们先看第一个NALU(SPS)的 RBSP (10个字节)
67 4D 40 33 92 54 0C 04 B4 20
转换成二进制:
0110 0111
0100 1101
0100 0000
0011 0011
1001 0010
0101 0100
0000 1100
0000 0100
1011 0100
0010 0000
先看NALU头,解析结果如下:
forbidden_zero_bit = 0 // 0 u(1)
nal_ref_idc = 3 // 11 u(2)
nal_unit_type = 7 // 00111 u(5)
这就对了,看看 NAL_SPS = 7;
接下来进入 RBSP,先讲SPS的
还记得视频编码数据工具 Elecard Stream Eye

点击 show\hide info 可查看 File 和 Headers (重点)


这里在推荐一款软件 下载:视频分析工具H264Visa

我们就是根据上图里的内容来进行分析。
profile_idc = 77 // 0100 1101 u(8) Main 参看:H264 各profiles用途和特点
constraint_set0_flag = 0 //0 u(1)
constraint_set1_flag = 1 //1 u(1)
constraint_set1_flag = 0 //0 u(1)
reserved_zero_5bits = 1 //1 u(5)
level_idc = 51 //0011 0011 u(8)
==================================================
对于 seq_parameter_set_id,我们看到它是ue(v),这是一种指数哥伦布编码
扩展:
参看:指数哥伦布码
指数哥伦布编码是一种在编码技术中经常用到的编码,其是无损编码,在HEVC中以及之前的编码技术H.264/AVC中,由于其可以由编码直接解得码字的变长码,所以广受欢迎。HM源码中的SPS/PPS和每个片的头部分都是用哥伦布编码进行编码。
对于一个需要编码的数 x,按照以下的几步进行编码:
1. 按照二进制形式写下 x+1,
2. 根据写下的数字,计算出当前数值的位数,然后在该数的前面加上当前数值位数减一后得到的数值个数的零。
例如:编码“3”
1. 该数加一后(即4)的二进制为100,
2. 当前数值的位数是三位,3减去1后得到2,所以在“100”的前方加上两个零,得“00100”即为3的哥伦布码。
下面列出1-8的哥伦布码:
0=> 1=> 1
1=> 10=> 010
2=> 11=> 011
3=> 100=> 00100
4=> 101=> 00101
5=> 110=> 00110
6=> 111=> 00111
7=> 1000=> 0001000
8=> 1001=> 0001001
哥伦布码扩展到负数范围
每一个负数进行编码的时候,将其映射到其绝对值的两倍。即-4映射为8进行编码;正数的映射为其两倍减一进行编码,即4映射为7进行编码。
例如:
0 => 0 => 1 => 1
1 => 1 => 10 => 010
=>1 => 2 => 11 => 011
2 => 3 => 100 => 00100
=>2 => 4 => 101 => 00101
3 => 5 => 110 => 00110
=>3 => 6 => 111 => 00111
4 => 7 => 1000 => 0001000
=>4 => 8 => 1001 => 0001001
K阶指数哥伦布码
为了用更少的比特表示更大的数值,可以使用多阶指数哥伦布编码(代价是相比起之前的0阶哥伦布码来书,小的数值可能需要更多的比特去表示)
进行K阶哥伦布编码的步骤是
1. 确定进行编码的阶数K
2. 将原数映射到” X + (2^k) -1” (即如果在3阶条件下编码4,则其将被映射到4+2^3-1=11)
3. 将上一步骤得到的数值进行0阶编码得到0阶哥伦布码(11->0001100)
4. 去掉码的前部分k个前导零(0001100->1100)
在进行解码的时候,从bit stream中寻找第一个非零比特值,然后把之前遇到的零的个数存在leadingzerobit参数中,即可根据该参数去被编码值了。
上面讲到的只是 ue(v),但是还有其他的像是 se(v),又是什么?
H264定义了如下几种描述子:
| ae(v) | 基于上下文自适应的二进制算术熵编码; |
| b(8) | 读进连续的8个比特; |
| ce(v) | 基于上下文自适应的可变长熵编码; |
| f(n) | 读进连续的n个比特; |
| i(n)/i(v) | 读进连续的若干比特,并把他们解释为有符号整数; |
| me(v) | 映射指数Golomb熵编码; |
| se(v) | 有符号指数Golomb熵编码; |
| te(v) | 截断指数Golomb熵编码; |
| u(n)/u(v) | 读进连续的若干比特,并将它们解释为无符号整数; |
| ue(v) | 无符号指数Golomb熵编码。 |
我们看到,描述子都在括号中带有一个参数,这个参数表示需要提取的比特数。
当参数是n时,表明调用这个描述子的时候回指明n的值,也即该句法元素是定长编码。
当参数是v时,对应的句法元素是变成编码,这时有两种情况:
i(v)和u(v)两个描述子的v由以前的句法元素指定,也就是说在前面会有句法元素指定当前句法元素的比特长度;陈列这两个描述子外,其他描述子都是熵编码,他们的解码算术本身能够确定当前句法元素的比特长度。
====================================================
seq_parameter_set_id = 0 // 1 ue(v)
log2_max_frame_num_minus4 = 3 //00100 ue(v)
pic_order_cnt_type = 0 //1 ue(v)
log2_max_pic_order_cnt_lsb_minus4 = 4 //00101 ue(v)
num_ref_frames = 1//010 ue(v)
gaps_in_frame_num_value_allowed_flag = 0 //0
pic_width_in_mbs_minus1 = 23 // 000011000 ue(v) (23+1)*16 = 384
pic_height_in_map_units_minus1 = 17 //000010010 ue(v) (17+1)*16 = 288
frame_mbs_only_flag = 1 //1
direct_8x8_inference_flag = 1 //1
frame_cropping_flag = 0 //0
vui_parameters_present_flag = 1 //1
以上分析部分和视频分析工具 header info SPS 比较发现结果是一致的。
SPS部分讲完了,然后再看 PPS
00 00 00 01 68 EE 3C 80
首先起始符 00 00 00 01
然后 68 即 nal_unit_type。
0x68的二进制是 0110 1000
则 forbidden_zero_bit(1bit) = 0;
nal_ref_idc(2bit) = 3;
nal_unit_type(5bit) = 8;即 PPS 类型。
然后再看 RBSP 部分
用视频分析工具得出的结果如下图:

将 EE 3C 80
转换成二进制:
1110 1110
0011 1100
1000 0000
pic_parameter_set_id = 0 //1 ue(v)
seq_parameter_set_id = 0 //1 ue(v)
entropy_coding_mode_flag = 1 //1
pic_order_present_flag = 0 //0
num_slice_groups_minus1 = 0 //1 ue(v)
num_ref_idx_l0_default_active_minus1 = 0 //1 ue(v)
num_ref_idx_l1_default_active_minus1 = 0 //1 ue(v)
weighted_pred_flag = 0 //0
weighted_bipred_idc = 0 //00
pic_init_qp_minus26 = 0 //1 ue(v)
pic_init_qs_minus26 = 0 //1 ue(v)
chroma_qp_index_offset = 0 //1 ue(v)
deblocking_filter_control_present_flag = 1 //1
constrained_intra_pred_flag = 0 // 0
redundant_pic_cnt_present_flag = 0 // 0
以上分析部分和视频分析工具 header info PPS 比较发现结果是一致的。
上面部分 参看:一步一步解析H.264码流的NALU(SPS,PSS,IDR) 同理可能还有 slice 部分的分析,这里不做介绍了
想深入了解的
记得一定要看哦,讲的是真好。还是贴出两张 NAL 句法,不然上面的讲的内容没一点解释,以后再看会有点懵。


到此,NALU语法结构大致讲完了。
二、NAL 进阶
我们上面有提到对获取的 nal 去掉开始码之后进行 base64 编码,这里有个 base64 编码,它是怎么回事?
1、live 555 源码分析
查看 live555 源码 live/liveMedia/H264VideoRTPSink.cpp +109
char const* H264VideoRTPSink::auxSDPLine() {
// Generate a new "a=fmtp:" line each time, using our SPS and PPS (if we have them),
// otherwise parameters from our framer source (in case they've changed since the last time that
// we were called):
H264or5VideoStreamFramer* framerSource = NULL;
u_int8_t* vpsDummy = NULL; unsigned vpsDummySize = 0;
u_int8_t* sps = fSPS; unsigned spsSize = fSPSSize;
u_int8_t* pps = fPPS; unsigned ppsSize = fPPSSize;
if (sps == NULL || pps == NULL) {
// We need to get SPS and PPS from our framer source:
if (fOurFragmenter == NULL) return NULL; // we don't yet have a fragmenter (and therefore not a source)
framerSource = (H264or5VideoStreamFramer*)(fOurFragmenter->inputSource());
if (framerSource == NULL) return NULL; // we don't yet have a source
framerSource->getVPSandSPSandPPS(vpsDummy, vpsDummySize, sps, spsSize, pps, ppsSize);
if (sps == NULL || pps == NULL) return NULL; // our source isn't ready
}
// Set up the "a=fmtp:" SDP line for this stream:
u_int8_t* spsWEB = new u_int8_t[spsSize]; // "WEB" means "Without Emulation Bytes"
unsigned spsWEBSize = removeH264or5EmulationBytes(spsWEB, spsSize, sps, spsSize);
if (spsWEBSize < 4) { // Bad SPS size => assume our source isn't ready
delete[] spsWEB;
return NULL;
}
u_int32_t profileLevelId = (spsWEB[1]<<16) | (spsWEB[2]<<8) | spsWEB[3];
delete[] spsWEB;
char* sps_base64 = base64Encode((char*)sps, spsSize);
char* pps_base64 = base64Encode((char*)pps, ppsSize);
char const* fmtpFmt =
"a=fmtp:%d packetization-mode=1"
";profile-level-id=%06X"
";sprop-parameter-sets=%s,%s\r\n";
unsigned fmtpFmtSize = strlen(fmtpFmt)
+ 3 /* max char len */
+ 6 /* 3 bytes in hex */
+ strlen(sps_base64) + strlen(pps_base64);
char* fmtp = new char[fmtpFmtSize];
sprintf(fmtp, fmtpFmt,
rtpPayloadType(),
profileLevelId,
sps_base64, pps_base64);
delete[] sps_base64;
delete[] pps_base64;
delete[] fFmtpSDPLine; fFmtpSDPLine = fmtp;
return fFmtpSDPLine;
}跳转查看 base64Encode
char* base64Encode(char const* origSigned, unsigned origLength) {
unsigned char const* orig = (unsigned char const*)origSigned; // in case any input bytes have the MSB set
if (orig == NULL) return NULL;
unsigned const numOrig24BitValues = origLength/3;
Boolean havePadding = origLength > numOrig24BitValues*3;
Boolean havePadding2 = origLength == numOrig24BitValues*3 + 2;
unsigned const numResultBytes = 4*(numOrig24BitValues + havePadding);
char* result = new char[numResultBytes+1]; // allow for trailing '\0'
// Map each full group of 3 input bytes into 4 output base-64 characters:
unsigned i;
for (i = 0; i < numOrig24BitValues; ++i) {
result[4*i+0] = base64Char[(orig[3*i]>>2)&0x3F];
result[4*i+1] = base64Char[(((orig[3*i]&0x3)<<4) | (orig[3*i+1]>>4))&0x3F];
result[4*i+2] = base64Char[((orig[3*i+1]<<2) | (orig[3*i+2]>>6))&0x3F];
result[4*i+3] = base64Char[orig[3*i+2]&0x3F];
}
// Now, take padding into account. (Note: i == numOrig24BitValues)
if (havePadding) {
result[4*i+0] = base64Char[(orig[3*i]>>2)&0x3F];
if (havePadding2) {
result[4*i+1] = base64Char[(((orig[3*i]&0x3)<<4) | (orig[3*i+1]>>4))&0x3F];
result[4*i+2] = base64Char[(orig[3*i+1]<<2)&0x3F];
} else {
result[4*i+1] = base64Char[((orig[3*i]&0x3)<<4)&0x3F];
result[4*i+2] = '=';
}
result[4*i+3] = '=';
}
result[numResultBytes] = '\0';
return result;
}2、从 RTSP 协议 SDP 数据中获得二进制的 SPS、PPS
我不会告诉你,上面base64 编码什么的我没看懂...
但是不妨碍,有一个工具: Base64编码/解码器 在线解码 可以base64编解码。
我们试一下:


你用也可以用通过程序来实现 base64编解码。
我们已经知道,在RTSP协议中DESCRIBE请求回复内容的SDP部分中,如果服务端的直播流的视频是H264的编码格式的话,那么在SDP中会将H264的sps、pps信息通过Base64编码成字符串发送给客户端(也就是解码器端),sps称为序列参数集,pps称为图形参数集。这两个参数中包含了初始化H.264解码器所需要的信息参数,包括编码所用的profile,level,图像的宽和高,deblock滤波器等。这样解码器就可以在DESCRIBE阶段,利用这些参数初始化解码器的设置了。那么如何将SDP中的字符串还原成sps、pps的二进制数据呢。下面的部分代码是从live555项目中取出来的,可以作为小功能独立使用,如果大家有用的着,可以直接拿去使用在项目中:
//main.cpp的内容
#include <stdio.h>
#include "Base64.h"
int main()
{
/*
RTSP 响应的SDP的内容中sprop-parameter-sets键值:
sprop-parameter-sets=Z2QAKq2wpDBSAgFxQWKQPQRWFIYKQEAuKCxSB6CKwpDBSAgFxQWKQPQRTDoUKQNC4oJHMGIemHQoUgaFxQSOYMQ9MOhQpA0LigkcwYh6xEQmIVilsQRWUURJsogxOU4QITKUIEVlCCTYQVhBMJQhMIjGggWQJFaIGBJZBAaEnaMIDwsSWQQKCwsrRBQYOWQweO0YEBZASNAogszlAUAW7/wcFBwMQAABdwAAr8g4AAADAL68IAAAdzWU//+MAAADAF9eEAAAO5rKf//CgA==,aP48sA==;
其中逗号前面的内容是sps的二进制数据被base64之后的结果
而逗号后面的内容(不要分号,分号是sdp中键值对的分隔符),是pps的内容
使用live555中的base64Decode函数分别对这两部分进行反base64解码得到的二进制数据就是h264中的sps pps 的二进制内容
分别是以67 和 68 开头
*/
char * sps_sdp = "Z2QAKq2wpDBSAgFxQWKQPQRWFIYKQEAuKCxSB6CKwpDBSAgFxQWKQPQRTDoUKQNC4oJHMGIemHQoUgaFxQSOYMQ9MOhQpA0LigkcwYh6xEQmIVilsQRWUURJsogxOU4QITKUIEVlCCTYQVhBMJQhMIjGggWQJFaIGBJZBAaEnaMIDwsSWQQKCwsrRBQYOWQweO0YEBZASNAogszlAUAW7/wcFBwMQAABdwAAr8g4AAADAL68IAAAdzWU//+MAAADAF9eEAAAO5rKf//CgA==";
char * pps_sdp = "aP48sA==";
unsigned int result_size=0;
unsigned char * p = base64Decode(sps_sdp,result_size);
for(int i =0;i<result_size;i++)
{
printf("%02X ",p[i]);
if((i+1)%16==0)
{
printf("\n");
}
}
printf("\n\n\n");
p = base64Decode(pps_sdp,result_size);
for(int i =0;i<result_size;i++)
{
printf("%02X ",p[i]);
if((i+1)%16==0)
{
printf("\n");
}
}
printf("\n");
return 0 ;
}<br>
/*
程序的解码输出如下,得到的分别是3500的sps和pps内容:
67 64 00 2A AD B0 A4 30 52 02 01 71 41 62 90 3D
04 56 14 86 0A 40 40 2E 28 2C 52 07 A0 8A C2 90
C1 48 08 05 C5 05 8A 40 F4 11 4C 3A 14 29 03 42
E2 82 47 30 62 1E 98 74 28 52 06 85 C5 04 8E 60
C4 3D 30 E8 50 A4 0D 0B 8A 09 1C C1 88 7A C4 44
26 21 58 A5 B1 04 56 51 44 49 B2 88 31 39 4E 10
21 32 94 20 45 65 08 24 D8 41 58 41 30 94 21 30
88 C6 82 05 90 24 56 88 18 12 59 04 06 84 9D A3
08 0F 0B 12 59 04 0A 0B 0B 2B 44 14 18 39 64 30
78 ED 18 10 16 40 48 D0 28 82 CC E5 01 40 16 EF
FC 1C 14 1C 0C 40 00 01 77 00 00 AF C8 38 00 00
03 00 BE BC 20 00 00 77 35 94 FF FF 8C 00 00 03
00 5F 5E 10 00 00 3B 9A CA 7F FF C2 80
68 FE 3C B0
*/其中用到的一个主要函数 base64Decode 的实现如下:
#include "Base64.h"
#include "strDup.h"
#include <string.h>
static char base64DecodeTable[256];
static void initBase64DecodeTable() {
int i;
for (i = 0; i < 256; ++i) base64DecodeTable[i] = (char)0x80;
// default value: invalid
for (i = 'A'; i <= 'Z'; ++i) base64DecodeTable[i] = 0 + (i - 'A');
for (i = 'a'; i <= 'z'; ++i) base64DecodeTable[i] = 26 + (i - 'a');
for (i = '0'; i <= '9'; ++i) base64DecodeTable[i] = 52 + (i - '0');
base64DecodeTable[(unsigned char)'+'] = 62;
base64DecodeTable[(unsigned char)'/'] = 63;
base64DecodeTable[(unsigned char)'='] = 0;
}
unsigned char* base64Decode(char const* in, unsigned& resultSize,
Boolean trimTrailingZeros) {
static Boolean haveInitedBase64DecodeTable = False;
if (!haveInitedBase64DecodeTable) {
initBase64DecodeTable();
haveInitedBase64DecodeTable = True;
}
unsigned char* out = (unsigned char*)strDupSize(in); // ensures we have enough space
int k = 0;
int const jMax = strlen(in) - 3;
// in case "in" is not a multiple of 4 bytes (although it should be)
for (int j = 0; j < jMax; j += 4) {
char inTmp[4], outTmp[4];
for (int i = 0; i < 4; ++i) {
inTmp[i] = in[i+j];
outTmp[i] = base64DecodeTable[(unsigned char)inTmp[i]];
if ((outTmp[i]&0x80) != 0) outTmp[i] = 0; // pretend the input was 'A'
}
out[k++] = (outTmp[0]<<2) | (outTmp[1]>>4);
out[k++] = (outTmp[1]<<4) | (outTmp[2]>>2);
out[k++] = (outTmp[2]<<6) | outTmp[3];
}
if (trimTrailingZeros) {
while (k > 0 && out[k-1] == '\0') --k;
}
resultSize = k;
unsigned char* result = new unsigned char[resultSize];
memmove(result, out, resultSize);
delete[] out;
return result;
}
static const char base64Char[] =
"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
char* base64Encode(char const* origSigned, unsigned origLength) {
unsigned char const* orig = (unsigned char const*)origSigned; // in case any input bytes have the MSB set
if (orig == NULL) return NULL;
unsigned const numOrig24BitValues = origLength/3;
Boolean havePadding = origLength > numOrig24BitValues*3;
Boolean havePadding2 = origLength == numOrig24BitValues*3 + 2;
unsigned const numResultBytes = 4*(numOrig24BitValues + havePadding);
char* result = new char[numResultBytes+1]; // allow for trailing '\0'
// Map each full group of 3 input bytes into 4 output base-64 characters:
unsigned i;
for (i = 0; i < numOrig24BitValues; ++i) {
result[4*i+0] = base64Char[(orig[3*i]>>2)&0x3F];
result[4*i+1] = base64Char[(((orig[3*i]&0x3)<<4) | (orig[3*i+1]>>4))&0x3F];
result[4*i+2] = base64Char[((orig[3*i+1]<<2) | (orig[3*i+2]>>6))&0x3F];
result[4*i+3] = base64Char[orig[3*i+2]&0x3F];
}
// Now, take padding into account. (Note: i == numOrig24BitValues)
if (havePadding) {
result[4*i+0] = base64Char[(orig[3*i]>>2)&0x3F];
if (havePadding2) {
result[4*i+1] = base64Char[(((orig[3*i]&0x3)<<4) | (orig[3*i+1]>>4))&0x3F];
result[4*i+2] = base64Char[(orig[3*i+1]<<2)&0x3F];
} else {
result[4*i+1] = base64Char[((orig[3*i]&0x3)<<4)&0x3F];
result[4*i+2] = '=';
}
result[4*i+3] = '=';
}
result[numResultBytes] = '\0';
return result;
}工程下载:demo_decoder_sdp
三、相关的工程
我之前讲过一个相关的工程,参看:DM368开发 -- 编码并实时播放
首先从 fwrite(Buffer_getUserPtr(hOutBuf),Buffer_getNumBytesUsed(hOutBuf), 1, outFile) != 1) 讲起。
(1)找到原来将获取帧保存为h.264文件部分,然后注释掉。

(2)查找起始符 00 00 00 01

(3)然后是 OnH264FrameDataOK 检测H264帧数据



到此结束!!下班啦... 这个程序其实是有问题的,明天再研究一下吧。
再者可参看:LIVE555再学习 -- testRTSPClient 实例 这个在此不讲了。
四、H.264 学习资源
参看:H.264 学习建议
如需转载请注明出处:https://blog.csdn.net/qq_29350001/article/details/78226286



















 780
780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











