







之前学习了机器学习,深度学习,NLP,都是均有涉猎,也不是贪心不足,而是保持着对新奇领域的好奇心,不断去学习,看看是啥样子的,
最近看了李宏毅老师的教学视频,感觉哈,要学习的东西好多,AI领域太广泛了。
不过,千里之行始于足下,Bettr late than never。
希望能得出其中的一些精髓性的东西来,跨领域会带俩不一样的思路哦。
一:强化学习(Reinforcement Learning)

简单的一句话就是,我们有一个Actor π,会从环境Environment观测到状态State(s),采取一定的措施 Action 比如a,在此同时,还会得到一定的奖励Reward比如 r。
Actor的目标就是去学习采取怎么的措施去最大化reward。
常见的场景就是,游戏博弈,棋类博弈等。让机器去学习下棋,打电玩游戏,某项特定任务等等。还运用在自动驾驶,飞行器,文本生成领域。
举个例子,打游戏,王者荣耀吧,让机器看到的是像素画面,产生的Action则是正确的动作,如移动上下左右,发一二三招,回城等。每一个action就是a_T,每一步骤获得的reward是r_T。等一轮结束后,这一轮叫做一个回合,也就是一个episode。
总的来说呢,我们有三种模型的强化学习,
一个是Policy-based,基于策略的,学习一个操作者Actor。也是本文要学习的。
一个是Value-based,基于价值的,学习一个评价者Critic。
一个是Model-based,基于模型的。
当然还有Policy-Value-based的混合型后面也会学习到。
二:基于策略的Policy Grident
好,有了上面的基础概念呢,我们就开始基于策略的RL学习之旅。
我们说了,基于策略的学习就是为了学习出一个好的Actor,让Actor根据环境State做出最好的Action,什么是最好的呢,就是得到的Reward是最大化的,或者结果玩游戏赢了就行。

我们把Actor产生Action的策略称为函数π。它的输入是从Environment观测的到state,输出是Action。我们的目的就是训练出这个Policy函数。
那它长什么样呢?它是一个Neural Network。以打游戏举例,输入就是游戏画面,在当前参数情况下。


三:怎么评估这个策略函数呢?
按照我们之前的经验,要得到一个网络,得先找到评估他好坏的方法,损失函数/代价函数就是这么来的啊,那我们也可以得到Actor的好坏评估,是骡子是马拉出来溜溜不就知道好坏了么,让他Actor跟环境好好交互一番,打N轮回合,看看得分情况,输赢情况就知道了好坏了,因此如果我们知道了怎么评估Actor的函数,不就可以用梯度下降去求解了么。





因此我们需要求出其偏导数。
四:具体计算


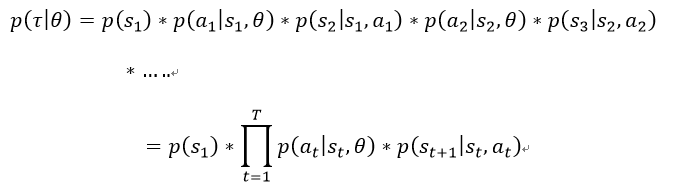




五:优化点



六:算法描述
















 135
135











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









