







我们继续学习一些其他的细节
一:样本均衡问题
我们来看看在SVM中样本不均衡的情况
比如两个样本集合的数目严重不对等,我们希望模型更能识别出少数样本,比如银行贷款,预测某人会不会抵赖,我们更希望能预测出抵赖的人,防止损失吧,大多数人是不会抵赖的,递来的人就是少数。
在这样的分布下,即便我们什么都不做,全部预测是不会抵赖,那么模型的准确度也是很高的,这样是没有任何意义,我们需要重点关注的是那部分少数的样本。
我们用class_weight来改变样本的分布权重比例。
同时我们也可以用sample_weight来改变每个样本的权重比例。
我们用代码来模拟下这个过程,第一步构建出样本不均衡的数据集。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn.datasets import make_blobs
# ===== 第一步:构造一个样本不均衡的数据集合例子
x, y = make_blobs(n_samples=[500, 50], # 两个簇,每个簇的样本个数分别就是元素值
centers=[[2, 2], [4, 4]], # 指定两个簇的中心
cluster_std=[1.5, 0.5], # 指定方差
n_features=2, # 样本特征是2
random_state=0,
shuffle=False)
print(x.shape)
print(y.shape)
plt.scatter(x[:, 0], x[:, 1], c=y, cmap='rainbow', s=10)
plt.show()

两类样本存在数据样本不均衡的现象,且有交叉重叠部分。
第二步:建立两个SVC模型,一个是不带有权重调整的,一个是有权重调整的。
# ===== 第二步:在样本不均衡的数据上进行建模
# 没有处理样本不均衡的,也就是没有设置class_weight的
svc1 = SVC(kernel='linear', C=1.0)
svc1.fit(x, y)
print(svc1.score(x, y))
# 处理样本不均衡的,也就是设置class_weight的
svc2 = SVC(kernel='linear', C=1.0, class_weight={1: 10})
svc2.fit(x, y)
print(svc2.score(x, y))
输出如下:
0.9418181818181818
0.9127272727272727
可见,带有权重的话,精确度会下降,这是为什么呢?我们画出决策边界来看看。
# ===== 第三步:将SVC的决策边界画出来
plt.figure(figsize=(6, 5))
plt.scatter(x[:, 0], x[:, 1], c=y, cmap='rainbow', s=10) # 先把样本所在的散点图画出来
ax = plt.gca() # 获取当前画布的子图对象
# 获取网格
xlim = ax.get_xlim() # 获取x轴范围
ylim = ax.get_ylim() # 获取y轴范围
xx = np.linspace(xlim[0], xlim[1], 30) # x轴范围平均分成30份
yy = np.linspace(ylim[0], ylim[1], 30) # y轴范围平均分成30份
YY, XX = np.meshgrid(yy, xx) # 行成了30x30个网点,网点2 横坐标和纵坐标都在,分别用YY和XX表示了
xy = np.vstack([XX.ravel(), YY.ravel()]).T
print(xy.shape) # 把900个点行成一个数组,放在了一起,用一个变量保存了。
z_svc1 = svc1.decision_function(xy).reshape(XX.shape) # 找到决策边界,根据决策函数,计算所有网点的值
a = ax.contour(XX, YY, z_svc1, colors='black', levels=[0], alpha=0.5, linestyles=['-']) # levels=0表示只画距离是0的
z_svc2 = svc2.decision_function(xy).reshape(XX.shape) # 找到决策边界,根据决策函数,计算所有网点的值
b = ax.contour(XX, YY, z_svc2, colors='red', levels=[0], alpha=0.5, linestyles=['-']) # levels=0表示只画距离是0的
plt.legend([a.collections[0], b.collections[0]], ['non-weighted', 'weighted'], loc='upper right') # 画出图例
plt.show()

我们能看到,没有经过类别权重调整的虽然精确度高,但是将少数样本拦腰截断了,对少数样本预测能力低下,但是对多数类别的样本的误差低;
经过class_weight调整的能够把少数类别样本全部分类正确,但是又误杀了一大堆多数类别样本,这就导致了准确率整体变低。
如果我们要追求总体准确率,那么不需要样本均衡,如果我们需要特别关注少数类的话,因为有时候把一个误差类分类错要比把一个多数类分类错的代价要惨痛的多啊。宁可多杀一个好人也不要错放一个坏人的这种保险思想。
比如银行贷款,潜在犯罪者,再比如新冠疫情下,宁愿相信你是疑似,高风险地区/境外回来需要集中隔离,都不能漏掉一个人传播病毒。一旦少数样本被分错,所带来的损失和代价将是巨大的。而将多数类别判断错误,顶多我们就是增加一些人为干预措施进行人为纠正排查和识别,这样的代价是可以接受的。
但是从另外的角度来看,如果我们一味追求少数类的识别正确,而把大量的多数类分类错误,这就会造成另外个问题,比如增加人为干预,成本上升,而且还带来了自己的收益反而下降了的情况,比如银行因为模型把正常客户分类错误了,就会拒绝很多交易,从而失去利润,人为增加人工排查成本也会增加。汽车召回事件,如果为了召回所有不符合标准的汽车,而把一些原本符合标准的汽车也召回,这将直接带来代价成本的提升。
因此,单纯的追求捕获少数类就会丧失一些利益和增加成本,但是不顾及少数的话,模型将失去意义,因此我们要在捕获少数的能力和将多数判断错误之间找到一个代价的平衡。
如果一个模型能在尽量鞥捕获少数类的情况下还能尽量对多数类判断正确,这就是很优秀了啊,我们需要混淆矩阵和ROC曲线来帮我们进行评估。
混淆矩阵就是:
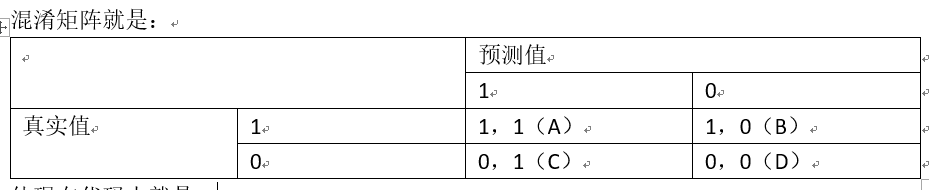
体现在代码中就是:
A1 = (y[y == svc1.predict(x)] == 1).sum() # 预测值是1,真实值是1。
B1 = (y[y != svc1.predict(x)] == 1).sum() # 预测值是0,真实值是1。
C1 = (y[y != svc1.predict(x)] == 0).sum() # 预测值是1,真实值是0。
D1 = (y[y == svc1.predict(x)] == 0).sum() # 预测值是0,真实值是0。
A2 = (y[y == svc2.predict(x)] == 1).sum() # 预测值是1,真实值是1。
B2 = (y[y != svc2.predict(x)] == 1).sum() # 预测值是0,真实值是1。
C2 = (y[y != svc2.predict(x)] == 0).sum() # 预测值是1,真实值是0。
D2 = (y[y == svc2.predict(x)] == 0).sum() # 预测值是0,真实值是0。
我们再混淆矩阵中一般有6个评估指标
1:准确率
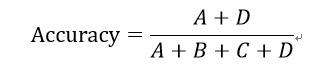
就是预测正确的样本除以样本总数,月接近于1越好。这个值就是svc,score(x,y)的值。
# 1:准确度
accuracy1 = (A1 + D1) / (A1 + B1 + C1 + D1)
print('不带均衡的分类器的准确率是:%f' % accuracy1)
accuracy2 = (A2 + D2) / (A2 + B2 + C2 + D2)
print('带均衡的分类器的准确率是:%f' % accuracy2)
输出是:
不带均衡的分类器的准确率是:0.941818
带均衡的分类器的准确率是:0.912727
和svc.score(x,y)是一样的。样本均衡后的模型的准确率略低。
2:精确度(precision)
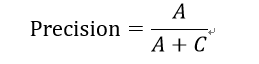
又叫做查准率,表示所有预测为少数的样本中,真正为少数的样本的比例。也是把多数类盘判别错后付出成本的度量。这个数值越高,表示我们越精确捕获到少数类,这个数值越低,表示我们误伤了很多多数类。
# 2:精确度
precision1 = A1 / (A1 + C1)
print('不带均衡的分类器的精确率是:%f' % precision1)
precision2 = A2 / (A2 + C2)
print('带均衡的分类器的精确率是:%f' % precision2)
输出是:
不带均衡的分类器的精确率是:0.714286
带均衡的分类器的精确率是:0.510204
样本均衡后的模型的精确度也低,原因就是误伤了很多多数类。
3:召回率(Recall)
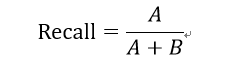
又称为敏感度,真正率,查全率,所有真实值是1的样本中被我们预测正确的样本所占的比例。这个值越高,表示我们捕获出了越多的少数类。召回率越低,代表我们没有捕获出足够的少数类。
# 3:召回率
Recall1 = A1 / (A1 + B1)
print('不带均衡的分类器的召回率是:%f' % Recall1)
Recall2 = A2 / (A2 + B2)
print('带均衡的分类器的召回率是:%f' % Recall2)
输出是:
不带均衡的分类器的召回率是:0.600000
带均衡的分类器的召回率是:1.000000
可见,少数样本被全部捕获了。
由此引申出的一个叫做假负率(False negative rate)的指标:
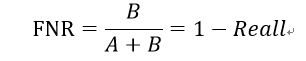
4:F1 measure
为了兼顾精确率和召回率,我们提出了一个新的综合性指标。
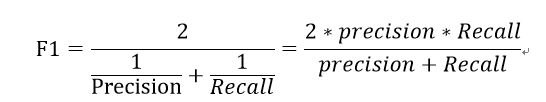
F1-measure的取值凡是【0,1】,越接近于1越好,能保证我们精确度和召回率都很高。
# F1 measure
F1M1 = (2 * precision1 * Recall1) / (precision1 + Recall1)
print('不带均衡的分类器的F1-measure是:%f' % F1M1)
F1M2 = (2 * precision2 * Recall2) / (precision2 + Recall2)
print('不带均衡的分类器的F1-measure是:%f' % F1M2)
输出是:
不带均衡的分类器的F1-measure是:0.652174
带均衡的分类器的F1-measure是:0.675676
综合一下,带有权重的F1指标要高一些。
5:特异度
所有真实为0的样本中,被正确预测为0的样本所占比例。

# 5:特异度
specificity1 = D1 / (C1 + D1)
print('不带均衡的分类器的精确率是:%f' % specificity1)
specificity2 = D2 / (C2 + D2)
print('带均衡的分类器的精确率是:%f' % specificity2)
输出是:
不带均衡的分类器的精确率是:0.976000
带均衡的分类器的精确率是:0.904000
由此引申出的一个叫做假正率(False positive rate)的指标:
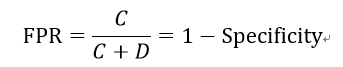
在scikit-learn中,有专门辅助类帮我们得到上面的值。
sklearn.metrics.confusion_matrix 混淆矩阵
sklearn.metrics.accuracy_score 准确率
sklearn.metrics.precision_score 精确率
sklearn.metrics.recall_score 召回率
sklearn.metrics.f1_score f1 measure
sklearn.metrics. precision_recall_curve 精确度-召回率曲线,可以展示不同阈值下的精确度召回率曲线。















 1536
1536











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









