







前言
线程与进程的定义
线程是一个基本的 CPU 执行单元。它必须依托于进程存活。一个线程是一个execution context(执行上下文),即一个 CPU 执行时所需要的一串指令。
进程是指一个程序在给定数据集合上的一次执行过程,是系统进行资源分配和运行调用的独立单位。可以简单地理解为操作系统中正在执行的程序。也就说,每个应用程序都有一个自己的进程。
**每一个进程启动时都会最先产生一个线程,即主线程。**然后主线程会再创建其他的子线程。
我们使用时候通常认为:CPU的核数就是最大进程数,因为每个进程就相当于一个独立的逻辑单元(理论上电脑可运行进程数是很多的,但是电脑的承载能力是有限的)。而每个进程会有很多线程(不单单是双线程)。
线程与进程的区别
- 一个进程可包含多个线程,其中有且只有一个主线程。
- 多线程共享同个地址空间、打开的文件以及其他资源。
- 多进程共享物理内存、磁盘、打印机以及其他资源。
多线程和多进程的适用条件
- 如果是用于科学计算,例如一些模型训练、矩阵计算等。你的每个任务的计算量是均等的,那建议用多进程。
- 如果是用于频繁的输入输出操作,例如爬虫等。你的每个任务的计算量是不等的,有大任务和小任务,那建议用多线程
多线程使用方法
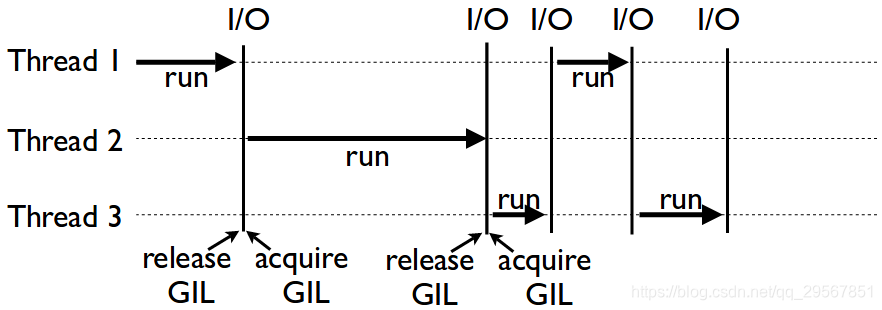
由于GIL(Global Interpreter Lock)的存在, 即程序运行时候,在每个时间序列只有掌握了GIL神剑的线程才能够运行。其实并没有真正的多线程并行的效果,它的优势在于它的I/O读写十分快,多线程之间的转换无缝衔接。
from multiprocessing.dummy import Pool as ThreadPool # 这是多线程执行任务,而不是多进程
因为多线程的鸡肋,就不多做介绍了。
多进程使用方法
我们来详细聊聊多进程。
推荐直接使用进程池进行操作,十分方便。
进程池
进程池分为四种方式:apply_async、apply、map_async、map。
其中apply_async和map_async是异步的,也就是启动进程函数之后会继续执行后续的代码不用等待进程函数返回。而另外两种是同步的,会等待进程函数的返回才会继续程序。
其实它们不是那种严格意义的"同步"和"异步",即运算串行运行和运算并行运行。它们的科学计算还是并行运算的,只不过是进程函数与后续程序的"同步"和"异步",所以它们的区别在于运行结果获取的方式,后续代码的执行需不需要等待进程函数结束,而计算速度是一样的。apply_async和map_async方式提供了一写获取进程函数状态的函数:ready()、successful()、get()。
apply和map的差别在于输入参数的不一样。apply可输入多个参数,但是创建多个线程的话需要一个个创建;map只能够输入一个参数(为一个列表,用于迭代),但是不用循环创建,一个即可。
代码运行展示:
apply:
from multiprocessing import Pool
def process(num):
print("num: {}".format(num**2))
time.sleep(1)
print("******")
return num**2
input_list = [10000000,1,3,5,7,9,10]
results = []
pool = Pool()
# pool = Pool(processes=6)#可指定进程数
for i in input_list:
result = pool.apply(process, (i, )) # 若为单形参则一定要加个逗号
results.append(result)
print("堵你一手")
print(results)
pool.close() # 关闭进程池,不能再添加进程了
pool.join() # 等待进程池里的进程运行完,才进入主进程
num: 100000000000000
******
num: 1
******
num: 9
******
num: 25
******
num: 49
******
num: 81
******
num: 100
******
堵你一手
[100000000000000, 1, 9, 25, 49, 81, 100]
可见apply是会等到进程函数运行结束,才会继续程序。而且它的计算是根据for循环顺序的,所以计算结果是按照顺序排列的
apply_async
from multiprocessing import Pool
import time
def process(num):
print("num: {}".format(num**2))
time.sleep(1)
print("******")
return num**2
input_list = [10000000000,100000000002,3,5,7,9,10000000000000,10000000000]
results = []
pool = Pool()
for i in input_list:
result = pool.apply_async(process, (i, ))
results.append(result)
print("堵你不住")
for res in results:
res.wait() # 等待进程函数执行完毕
if res.ready(): # 进程函数是否已经启动了
if res.successful(): # 进程函数是否执行成功
print(res.get()) # 进程函数返回值
pool.close() # 关闭进程池,不能再添加进程了
pool.join() # 等待进程池里的进程运行完,才进入主进程
num: 100000000000000000000
num: 10000000000400000000004
num: 9
num: 49
num: 25
num: 81
num: 100000000000000000000
num: 100000000000000000000000000
堵你不住
******
******
******
******
******
******
******
******
100000000000000000000
10000000000400000000004
9
25
49
81
100000000000000000000000000
100000000000000000000
可见,apply_async与apply区别在于:启动进程函数之后会继续执行后续的代码不用等待进程函数返回。而且数据的读取方式不一样。返回值是不按照输入列表顺序排列的。
map
from multiprocessing import Pool
import time
def process(num):
print("num: {}".format(num**2))
time.sleep(1)
return num**2
input_list = [1,3,5,7,9,10,20]
results = []
pool = Pool()
result = pool.map(process, input_list)
print("堵你一手")
print(result)
pool.close() # 关闭进程池,不能再添加进程了
pool.join() # 等待进程池里的进程运行完,才进入主进程
num: 1
num: 25
num: 9
num: 49
num: 100
num: 81
num: 400
堵你一手
[1, 9, 25, 49, 81, 100, 400]
可见map的输入是一个列表,输出也是按照顺序排列的列表,虽然它计算的时候是不按照顺序进行的。
map_async
from multiprocessing import Pool
import time
def process(num):
print("num: {}".format(num**2))
time.sleep(1)
print("******")
return num**2
input_list = [1,3,5,7,9,10,20]
results = []
pool = Pool()
result = pool.map_async(process, input_list)
print("堵你不住")
result.wait() # 等待所有进程函数执行完毕
if result.ready(): # 进程函数是否已经启动了
if result.successful(): # 进程函数是否执行成功
print(result.get()) # 进程函数返回值
num: 9
num: 1
num: 25
num: 100
num: 81
num: 49
num: 400
堵你不住
******
******
******
******
******
******
******
[1, 9, 25, 49, 81, 100, 400]
可见,map_async和map的区别在于,进程函数未结束它就会进行后续的程序,和数据的获取方式。它的计算也是无序的,且结果也是有序的。
**注意:**进程池pool的创建和处理还是放在主函数main内比较好吧,因为放在其他子函数内好像会出问题…
参考文献:
[1]














 1446
1446











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









