






URL
https://arxiv.org/pdf/2402.03286
TL;DR
2024 年 2 月 nvidia 的文章。提出了一种不需要任何额外训练的主体保持方法,可以一次生成的 batch 中,通过多个 prompt 生成对应的多张图片,这些图片都可以拥有一个主体。
本文提出的方法通过 subject-driven shared attention block来保证多图间的主体一致性,另外通过一些 trick 保证生成图片分布的多样性和 layout 的多样性。本方法可以保证不需要任何额外训练或 finetune 的情况下,完成主体保持的人物,同时相比其他需要训练的方法有更好的文本对齐能力

Model & Method
作者提出,已有的主体保持方法有很明显的几个缺陷:
- 强制模型在进行 posteriori 的主体保持,即强行制定一张 target 图片送给模型来进行生图。比如通过 encoder + cross attention、reference net 来进行。
- 提供参考图的方法破坏了模型本身的能力,让生成图片的分布远离了训练数据的分布。
本文主要通过对 self-attn 的操作,保证图片之间共享知识,来实现无训练版的主体保持。ppl如下图
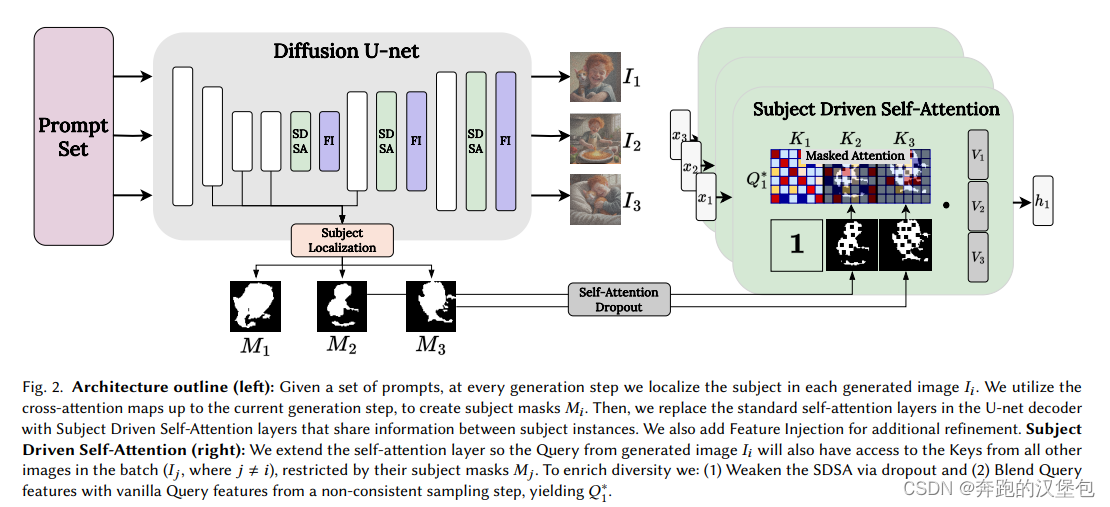
Unet 中主要的改动是:
- self-attn 替换成了 subject driven self-attn(SDSA)。除了当前 prompt 对应的 attn map 之外,还会附上其他 prompt 对应的 attn map,其他 prompt 的 feature 会用 cross attn 提取的 mask 保证只保留主体信息。这样 self-attn 就可以在所有的 prompt 的 feature 之间共享特征,实现了主体保持同时还能保证不同 prompt 之间的编辑性。
- 增加了一个 feature injection(FI)模块。文章提到仅使用 SDSA 无法保证细节的一致性比如眼睛(等 SD 常被诟病的细节),于是在 SDSA 之后,对单个 feature 以及对应的其他组 feature,分别计算一次相似度,选取与当前 feature 最相似的另一组 feature 做一次 blend 计算,即融合两张图片之间的特征,来保证细节的相似度。因为是强化细节特征,所以在 patch 维度而不是整图维度。具体的计算方法是先对 feature 做一次 DIFT 特征匹配,然后与 batch 内其他的 feature 两两计算 cos 相似度。
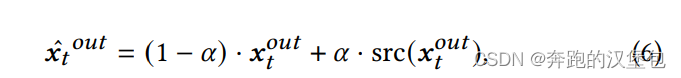
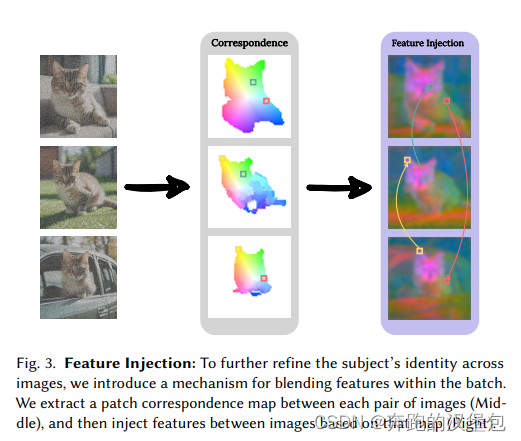
另外文章提到即使在 self-attn 之间共享的只是 mask 提取到的主体,但是仍然会出现生成图片分布过于一致的问题。作者给出的解法:
- 第一个 trick 是使用早期结构信息比较丰富的原始特征,融合到后续的特征中去这样可以保证分布不受后面特征注入的影响
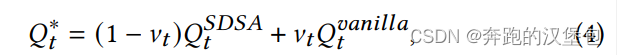
- 第二个trick 是在 SDSA 中增加 dropout 机制。
Dataset & Results
部分结果:



Thought
- 思路很棒,和 StoryDiffusion 一样都是在 self-attn 上做文章。
- Feature injection 操作感觉挺棒的,猜测是比较关键的技术,可以尝试一下细节保持的能力。(在 reference net 或者其他带注入的方法里面也许可以用到,这是之前一直想要的技术)















 294
294











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









