






URL
TD;DR
上帝视角看的神作 DIT 架构,22 年 12 月 META(伯克利+新乡大学)发布,一个取代了 Unet 的全 transformer diffusion 生图架构。
Model & Method
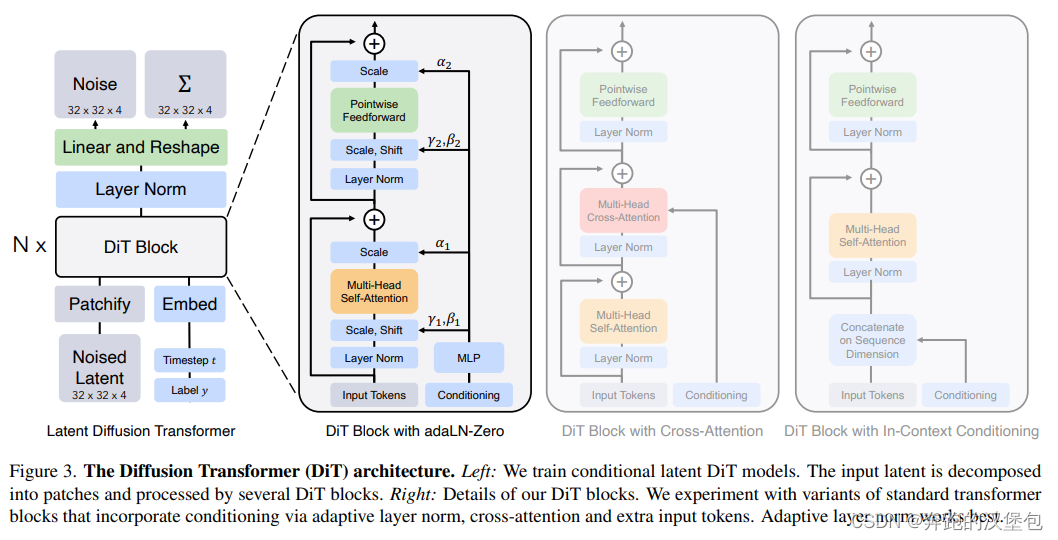
总体结构如下图,文章一共给出了 3 重 DiT 的 block 结构,区别是 condition 的注入方式,从左到右依次是:
- adaLN-Zero:就是通过 adaptive layer norm 把 timestamp + cls token 注入到 attn token 里面,但是仅限于单个 token 的情况比较好用,因为只能引入两个可学习参数
dimensionwise scale and shift parameters γ and β。对于 natural language 长文本来说不是很够用 - 常见的 cross attn 方式,用来处理带有 text condition 的长文本输入。
- 直接 concat 到 vis token 后面,和第一种情况类似,token 长度过长之后就不好用了。猜测效果还没有第一种好。好处是几乎不引入额外的计算量。
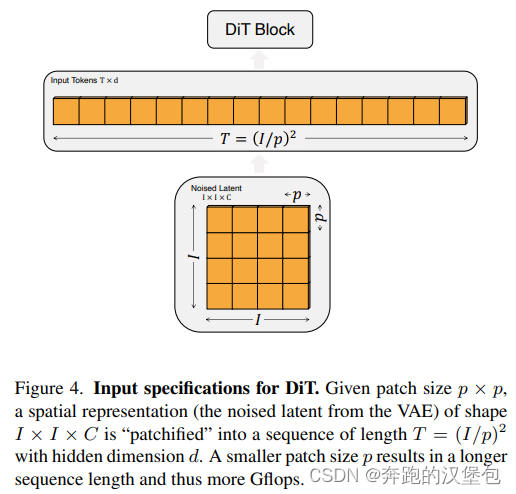
vae 之后的 latent,过类似 ViT 的 patch 操作,把原本二维的图像特征一维化。
DiT 的基本结构 follow ViT 的几种配置:ViT-B、S、L、XL,因此也有四种对印度个参数量设置
Dataset & Results
可以参考原文,结果展示不是很重要,重点是思路
Thought
- 篇幅不多但是思路非常清晰,输入的 patch 操作帮助 DiT 不会受到分辨率的影响。
- 另外因为是纯 transformer 架构,所以文生图的 scaling law 开始出现了















 1680
1680











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









