







1. 继承关系
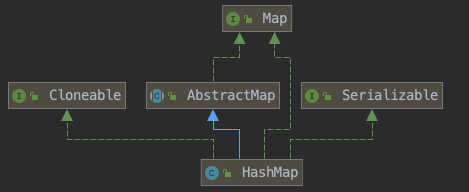
2. 基础属性
- DEFAULT_INITIAL_CAPACITY = 1 << 4
默认初始化大小16,构造方法可设置,设置值为传入参数的最小的2的幂次方的数值,就比如你传值为20,则HashMap的大小为32(2的5次方),传值为10,则大小为16 - MAXIMUM_CAPACITY = 1 << 30
最大容量2的30次方,int的最大正数值 - DEFAULT_LOAD_FACTOR = 0.75f
扩容因子默认0.75,可通过构造函数传入 - TREEIFY_THRESHOLD = 8
计数阈值,链表的元素大于8的时候,链表将转化为树(1.8后为红黑树) - UNTREEIFY_THRESHOLD = 6
计数阈值,红黑树的节点数量小于6时使用链表来代替树 - MIN_TREEIFY_CAPACITY = 64
链表转化为红黑树时哈希桶数组大小的最小值 - transient Node<K,V>[] table
数据存放结构,Node类中有包含自己的引用属性,用于在哈希冲突时形成链表。有子类TreeNode用用于形成树结构。
3. 常用方法解释
- key的hash值计算方法
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
此方法是求key的hash值,算法为作者定义的扰乱算法,目的是使不同的key尽量可以由自己的唯一hash值,算法总结为高16bt不变,低16bit和高16bit做一个异或
- Node数组存放index计算方式
index = (length - 1) & key.hash
HashMap中存储数据table的index是由key的Hash值决定的。我们希望这个hashmap里面的元素位置尽量的分布均匀些,常见即为数组长度取模运算(%),上面的&运算即为取模运算的变形
- put方法
图片涞源:https://www.jianshu.com/p/6cc30a8d0e98
如有侵权删除

- get方法
通过(tab.length - 1) & hash找到桶的位置,比较key是否相同进行返回,如果是链表则遍历链表比较,如果是红黑树则遍历树。比较时需满足三个条件:
e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k)))
- resize方法
当map容量大于扩容阙值时调用此方法进行table[]的扩容,方式为新建一个为原数组长度二倍的数组,扩容二倍的原因有下几点:
- 容量必须是2的次幂,则扩容只能乘二
- 当容量是2的幂次方时,hash&(length-1)==hash%length,加快计算
- 通过key计算index时是根据数组长度进行&运算得出的,二倍扩容刚好是长度<<1(左移一位),这样对于老组数往新数组迁移时会形成规律:元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置
- 如果是1.7问为何二倍的话,只能说2倍是满足新map冲突的最优解
4. 遍历
- 1.8 lambda 方式及entrySet遍历,下面两种方式都是通过HashMap内部类EntrySet的forEach方法实现的,原理为直接对table[]数组进行遍历
/** lambda 方式直接遍历 */
map.forEach((k, v) -> {
//doSomething
});
/** 获取EntrySet再foEeach遍历 */
map.entrySet().forEach(a -> {
a.getKey();
a.getValue();
//doSomething
});
- 通过获取keySet再forEach遍历,是通过HashMap内部类KeySet中的forEach方法实现的,原理为对table[]数组进行遍历
map.keySet().forEach(key -> {
String value = map.get(key);
//doSomething
});
- 通过获取values再forEach遍历,是通过HashMap内部类Values中的forEach方法实现的,原理为对table[]数组进行遍历
map.values().forEach(value -> {
//doSomething
});
- 获取EntrySet或者KeySet或者Values再通过Iterator遍历,其实现为HashMap内部类HashIterator实现Iterator接口中的hasNext和nextNode等方法,再底层还是对table[]的遍历
/** entrySet的iterator遍历 */
Iterator<Entry<String, String>> iterator = map.entrySet().iterator();
if (iterator.hasNext()) {
//doSomething
}
/** key的iterator遍历 */
Iterator<String> keyIterator = map.keySet().iterator();
if (keyIterator.hasNext()) {
//doSomething
}
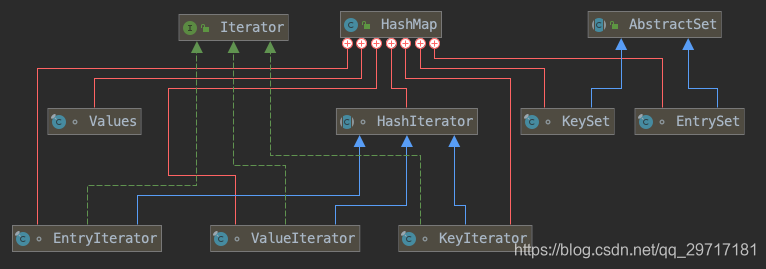
总结如下
| 遍历方法 | 遍历集合 | 所在类 | 所在方法 | 方法原理 |
|---|---|---|---|---|
| forEach/lambda遍历 | entrySet | EntrySet | forEach | 遍历map的table[] |
| keySet | KeySet | forEach | ||
| values | Values | forEach | ||
| iterator遍历 | entrySet.iterator | HashIterator及对应子类EntryIterator | nextNode\hasNext等 | |
| keySet.iterator | HashIterator及对应子类KeyIterator | |||
| values.iterator | HashIterator及对应子类ValueIterator |
- 相关内部类继承关系
5. LinkedHashMap
- 其为HashMap的子类, 同时其内部类Entry也继承了HashMap.Node增加了before和after属性,即靠这两个属性来保持顺序
- 在HashMap方法的put方法中新建节点操作为:
//LinkedHashMap重写了此方法返回自己的新节点类
tab[i] = newNode(hash, key, value, null);
同时HashMap还预留了三个接口专门给LinkHashMap,在HashMap的put,remove方法中均有调用来实现LinkHashMap的功能
// Callbacks to allow LinkedHashMap post-actions
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }
void afterNodeRemoval(Node<K,V> p) { }
6. 不同Map的区别
| 类 | 特性 |
|---|---|
| HashMap | 线程不安全,get方法时间复杂度最好O(1)最坏O(nlog2n),链表有转红黑树 |
| Hashtable | 线程安全,也只是多线程调用同一方法时安全,调用不同方法时需用户自己进行处理; 其继承Dictionary而其他Map继承AbstractMap |
| LinkHashMap | 继承HashMap,对HashMap.Node节点类增加before, after属性,使得其可以顺序遍历 |
| TreeMap | 内部没有数组,只有一个红黑树,所以查询时间复杂度为O(nlog2n) |














 4191
4191











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









